If you’ve ever struggled with manual, inconsistent, or expensive machine learning (ML) workflows (or if you'd love to have a formalized workflow at all), you’re not alone! Many teams hit roadblocks when trying to automate, scale, or manage their ML pipelines—especially as projects grow, scope creeps, and requirements inevitably change.
Red Hat OpenShift AI now brings a set of updates to data science pipelines, making it easier than ever to control and optimize your ML processes. These improvements aren’t just about new features, they’re also about helping you optimize resource consumption and minimize the 2am on-call page-outs by building workflows you can trust in production.
So, what exactly are data science pipelines in OpenShift AI?
Think of a data science pipeline in OpenShift AI as the navigation system for your entire ML workflow. You can visually build this pipeline, which is powered by a structure called a directed acyclic graph (DAG). A DAG acts as the blueprint for your process, from data prep to deployment, by mapping out each task in a clear, one-way workflow. This structure is what makes sure that every step runs in the correct order and your pipeline doesn't get stuck in an infinite loop.
This blueprint or map is technically a graph where each component (a node) runs inside of a container on Red Hat OpenShift. These nodes are connected by edges (think of this as the arrows on a flow chart), which define their dependencies, so a task only runs after its prerequisites are met and the appropriate outputs go to the right places (the inputs of the next steps). The graph is "directed" because the workflow only moves forward and "acyclic" because it can't circle back on itself. This workflow gives you precise control over your ML operations, making more efficient use of cluster resources. You also get to benefit from the built-in OpenShift metrics and a rich ecosystem of open source and commercial tools and add-ons to help manage, track, and optimize your resource consumption.
You'll find data science pipelines integrated right into the Red Hat OpenShift AI projects UI, in the "Train models" section and on the "Pipelines" tab:
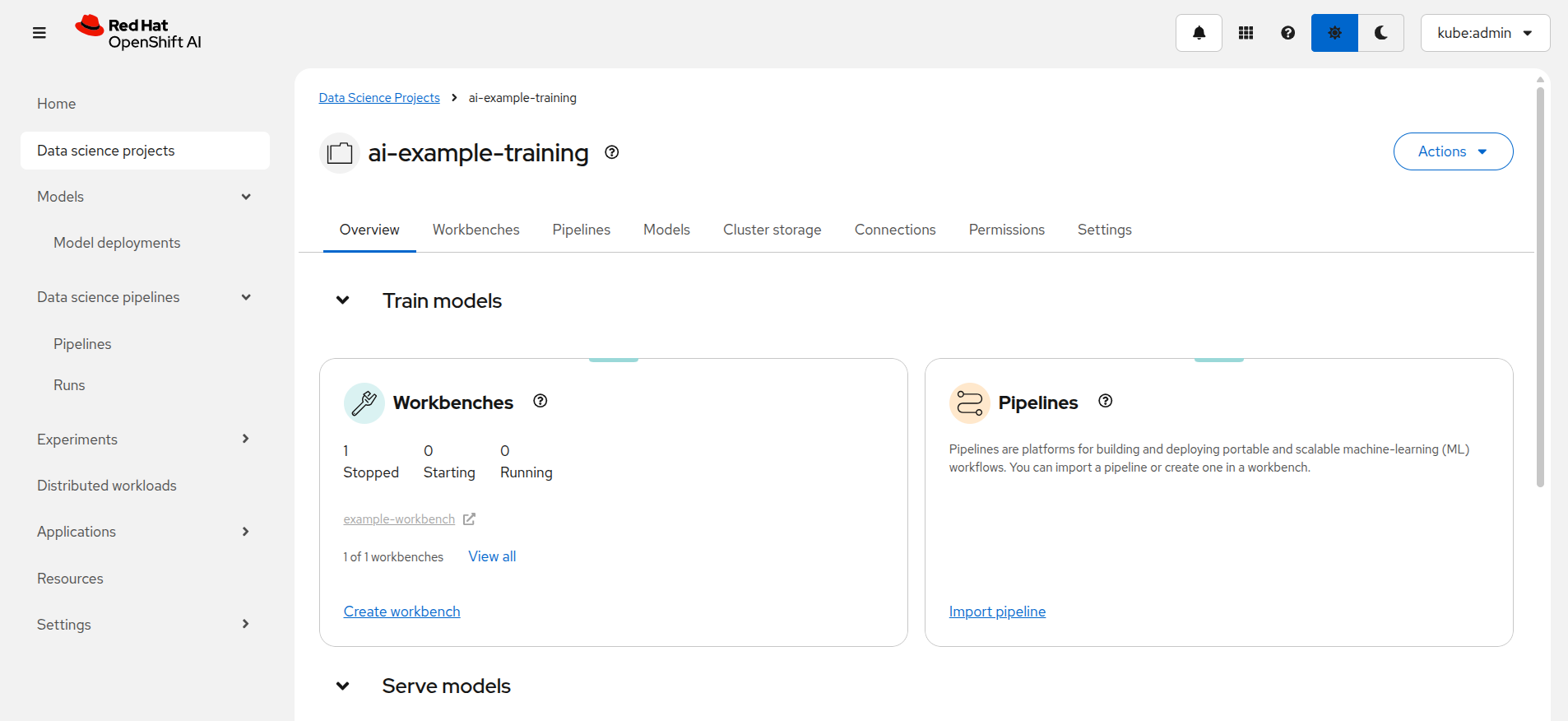
Creating a pipeline (and then what?)
To set up a workflow to automate model automation, we have two options: we can use Elyra’s visual "graph editor" for a "no-code" drag and drop solution, or we can write it in Python using the kfp module from the KubeFlow Pipelines SDK.
Here’s a brief overview of the steps:
- Create a data science project
- Create and configure a pipeline server
- Define your ML workflow, mapping out tasks from data preparation and cleaning to model serving
- Use Jupyter + Elyra's visual graph editor for a no-code approach, or write Python code with the kfp module for more flexible pipeline creation
- Create and run a pipeline experiment to try different configurations of your pipelines (customized to different environments, data sets, or runtime parameters)
- Review and compare the runs within your pipeline experiment
- Configure (and optionally schedule) pipeline runs
Dig into the great documentation on Working with data science pipelines | Red Hat OpenShift AI that does a far better job of explaining that process than I could.
Cool new things in data science pipelines (from Kubeflow Pipelines 2.4.x)
We work hard to make sure that OpenShift AI doesn't just keep pace with the awesome work happening upstream in the Kubeflow Pipelines project, but that we're also core contributors to that project.
Let's take a look at a few key enhancements that came with Kubeflow Pipelines 2.4.x1.
Flexible resource limits with placeholders
Kubeflow Pipelines 2.4.x introduced support for placeholders when setting resource limits. This is helpful because you can now set resource limits dynamically using parameters. For you, this means your pipeline definitions can be much more flexible and reusable across different environments or experiment runs where you might need varying CPU or memory (such as dev vs. prod).
Setting resource limits like set_cpu_limit(dev_cpu_limit), makes it easy to run the same pipeline with different resource profiles just by changing one parameter:
from kfp import dsl
@dsl.component
def sum_numbers(a: int, b: int) -> int:
return a + b
@dsl.pipeline
def pipeline(
dev_cpu_limit: str = '4000m',
Memory_limit: str = '15G',
accelerator_type: str = 'NVIDIA_TESLA_P4',
accelerator_limit: str = '1'
):
sum_numbers_task = sum_numbers(a=1, b=2)
sum_numbers_task.set_cpu_limit(dev_cpu_limit)
sum_numbers_task.set_memory_limit(memory_limit)
sum_numbers_task.set_accelerator_type(accelerator_type)
sum_numbers_task.set_accelerator_limit(accelerator_limit)
if __name__ == '__main__':
from kfp import compiler
compiler.Compiler().compile(
pipeline_func=pipeline, package_path=__file__.replace('.py', '.yaml'))Better control over parallel loops
Another cool feature introduced in Kubeflow Pipelines 2.4.1 is the new parallelism limit for ParallelFor tasks. ParallelFor allows you to iterate over a large dataset using multiple tasks spread out across pods/nodes, and later combine the results. The new parallelism limit parameter helps you limit how many tasks are scheduled at once (think concurrency), which is particularly useful for tasks like running inference across large data sets. When you're running large pipelines that use GPUs, setting this limit correctly can help you avoid using too many resources, helping keep your system more stable, and potentially saving you a lot on compute costs by controlling parallel GPU tasks.
from kfp import dsl
@dsl.component
def train_model(epochs: int) -> str:
# Placeholder for actual model training logic
return f"Model trained for {epochs} epochs"
@dsl.pipeline
def my_training_pipeline():
with dsl.ParallelFor(items=[1, 5, 10, 25], parallelism=2) as epochs:
train_task=train_model(epochs=epochs)Reliable SubDAG Output resolution
When you build more complex, nested workflows (think of it as a pipeline calling another pipeline – represented as ‘SubDAGs’), you want to be sure the nested pipelines run correctly every time. Kubeflow Pipelines 2.4.0 improved how outputs are handled from SubDAGs. This improvement means that if you use nested pipelines, the outputs from those inner workflows connect correctly to the steps that follow in the main workflow and don’t get overwritten by other parallel or concurrent SubDAGs. This helps avoid broken dependencies that could prevent the pipeline from running correctly, so building modular, multi-level pipelines is a lot more reliable.
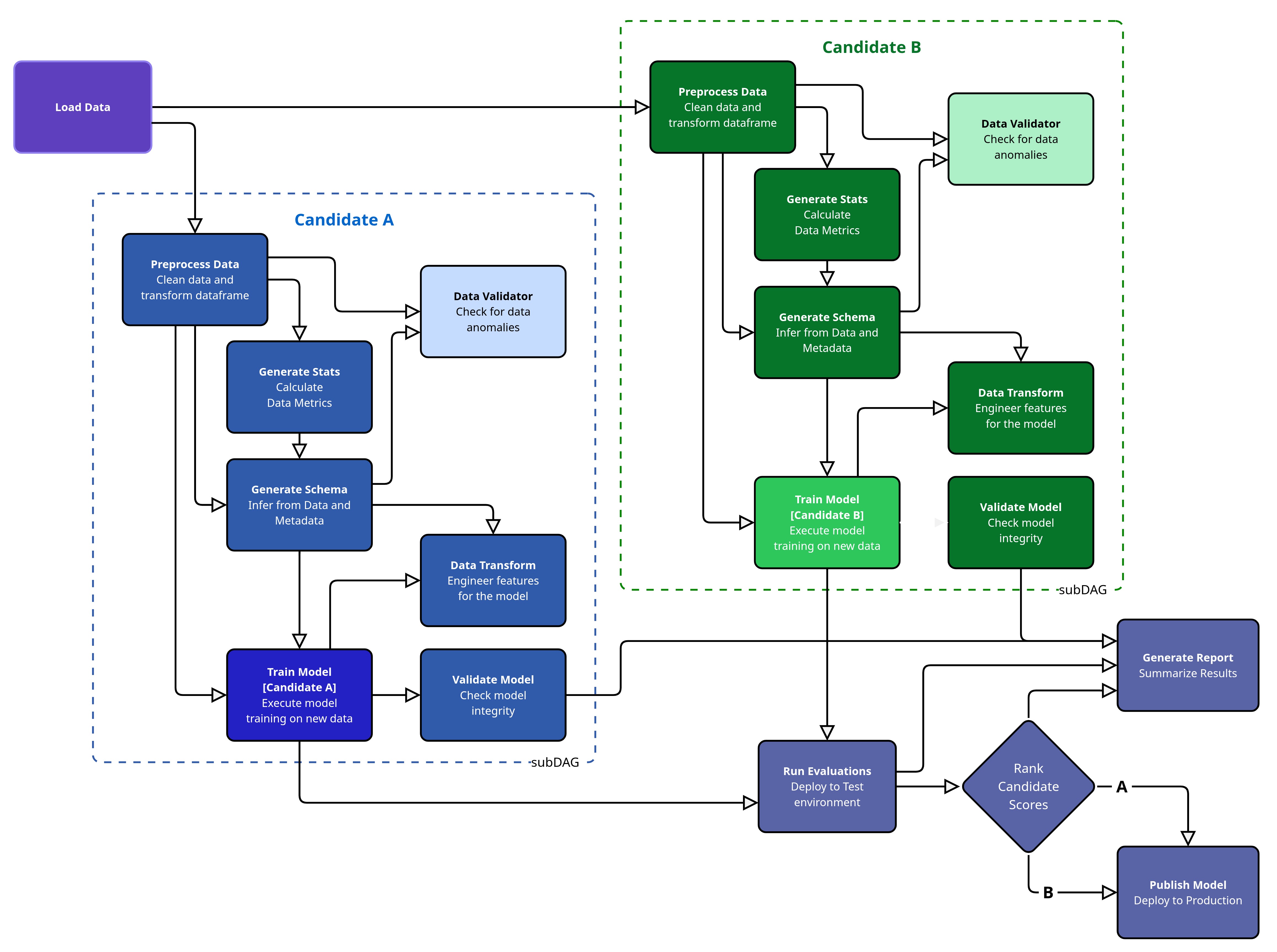
In the main pipeline, you can have nested workflows (SubDAGs). This improvement means that the results from the nested workflows correctly feed into the following steps of the main pipeline and the outputs don’t trample each other.
How these updates help you in OpenShift AI
These data science pipelines improvements provide the following benefits when you're working in OpenShift AI:
- More flexibility: With parameterized resource limits, it's easier to adapt your pipelines for different cluster sizes or project needs without having to rewrite your code.
- Smarter resource use and potential cost savings: The parallelism limit feature is a game-changer for managing resources, especially for those heavy compute tasks on accelerators. You get more control, which can lead to better stability and lower costs.
- More reliable workflows: The fix for SubDAG outputs means you can build more complex, modular pipelines with greater confidence that they'll run correctly.
- Smoother MLOps: All these features together give you better tools for automating your ML workflows, making your MLOps practices within the OpenShift AI platform more efficient and easier to repeat.
OpenShift AI leverages the benefits of OpenShift to provide a platform that gives you a consistent way to run your applications (and now your AI workloads!) anywhere—on-premises, across different clouds, or at the edge. That consistency is a big deal for avoiding vendor lock-in and managing your environment.
An important heads-up: The data science pipelines 2.0 change
Starting with OpenShift AI version 2.9, we shifted to data science pipelines 2.0 (based on Kubeflow Pipelines 2.x) which is now the default in OpenShift AI.
Also, starting with the release of OpenShift AI 2.16 onward, resources from data science pipelines 1.0 are no longer supported or managed by OpenShift AI, which means you can no longer deploy, view, or edit those older pipelines from the dashboard or the KubeFlow Pipelines API server.
It's really important to understand that OpenShift AI doesn't automatically move your existing data science pipelines 1.0 instances to 2.0. If you're upgrading to OpenShift AI 2.16 or later, you'll need to manually migrate your existing data science pipelines 1.0 instances.
A big part of this is updating and recompiling your old pipelines—data science pipelines 2.0 doesn't use the kfp-tekton library, but in most cases you can just swap kfp-tekton usage with the kfp library, making sure you use the latest version of the KFP SDK.
Additionally, while data science pipelines 2.0 does include an installation of Argo Workflows, Red Hat doesn't support direct customer use of that embedded Argo Workflow deployment.
Wrapping up
The latest updates to data science pipelines in Red Hat OpenShift AI, thanks to the advancements in Kubeflow Pipelines 2.4.x, bring some useful new capabilities for managing your ML workflows. Being able to use flexible resource limits, control parallel execution, and trust your nested workflows (SubDAGs) and their outputs means more flexibility, better efficiency, and more reliable AI/ML workflows for you.
These updates are an example of how Red Hat is committed to giving you a strong, open source-based platform for your entire AI/ML journey on OpenShift. It's all about helping you innovate faster and manage your AI/ML operations more effectively.
Learn more
- Check out Red Hat OpenShift AI
- Try out Red Hat OpenShift AI in your own cluster
- Dig into Working with data science pipelines
- Read up on the Red Hat OpenShift AI 2.23 new features, including the upstream KFP upgrades
- Learn about Migrating to data science pipelines 2.0
- Find out more about building an ops foundation for the future of generative AI
- Explore the upstream Kubeflow Pipelines documentation
À propos de l'auteur

Alex Handy (not to be confused with the other Alex Handy - https://www.861278361.xyz/en/authors/alex-handy) is a Canadian Principal Consultant in Red Hat's AI Practice, bringing a wealth of technical experience since joining Red Hat in 2019. His expertise spans architecting and delivering solutions across a broad range of Red Hat technologies, including OpenShift AI, OpenShift, Red Hat Ceph Storage, OpenShift Data Foundation, OpenStack, Ansible, ACM, and RHEL. Alex has partnered with customers across diverse industries such as finance, media, technology, energy, manufacturing, and government. Outside of his work with open source solutions, you can find Alex in his workshop, experimenting in his HomeLab, or caring for his family's hobby farm on Canada's West Coast.
Contenu similaire
Parcourir par canal

Automatisation
Les dernières nouveautés en matière d'automatisation informatique pour les technologies, les équipes et les environnements

Intelligence artificielle
Actualité sur les plateformes qui permettent aux clients d'exécuter des charges de travail d'IA sur tout type d'environnement

Cloud hybride ouvert
Découvrez comment créer un avenir flexible grâce au cloud hybride

Sécurité
Les dernières actualités sur la façon dont nous réduisons les risques dans tous les environnements et technologies

Edge computing
Actualité sur les plateformes qui simplifient les opérations en périphérie

Infrastructure
Les dernières nouveautés sur la plateforme Linux d'entreprise leader au monde

Applications
À l’intérieur de nos solutions aux défis d’application les plus difficiles
Virtualisation
L'avenir de la virtualisation d'entreprise pour vos charges de travail sur site ou sur le cloud