With large language models (LLMs) quickly advancing and becoming more and more integrated into mission-critical enterprise workflows, their capability to accurately reason and respond to very domain-specific and highly specialized knowledge matters. This is especially the case in the cybersecurity space, where the stakes are high and where accuracy is critical and often assumed to be a given. Thus, assessing the performance of LLMs on realistic and high-quality benchmarks specific to cybersecurity is not only useful, but also necessary.
This blog post describes our evaluation of a number of IBM Granite and InstructLab models with the CyberMetric Dataset, a dedicated benchmark for the evaluation of cybersecurity knowledge. Our evaluation has been conducted on a Red Hat Enterprise Linux (RHEL) AI 1.3 virtual machine (VM) that includes InstructLab and a single NVIDIA L4 GPU.
We benchmarked the following models:
IBM Granite
- granite-3.3-8b-instruct
- granite-3.3-2b-instruct
- granite-3.0-8b-instruct
- granite-3.0-2b-instruct
InstructLab
- merlinite-7b-pt
- granite-3.0-8b-lab-community
The CyberMetric evaluation sets used
- CyberMetric-80-v1.json
- CyberMetric-500-v1.json
- CyberMetric-2000-v1.json
- CyberMetric-10000-v1.json
What is the CyberMetric Dataset?
The CyberMetric Dataset is a relatively new benchmarking tool in the cybersecurity domain. It comprises over 10,000 human-validated, multiple-choice questions, making it a comprehensive resource for evaluating LLMs in cybersecurity contexts.
The dataset is sourced from a wide range of authoritative materials, including open standards, NIST guidelines, research papers, publicly available books, RFCs and other relevant publications. It was generated using retrieval-augmented generation (RAG) techniques, which combine the strengths of retrieval-based models with generative capabilities.
Additionally, the CyberMetric Dataset has undergone a rigorous, multi-stage refinement process. This process involves both LLMs and human experts, providing high-quality data that accurately reflects real-world cybersecurity knowledge.
The dataset is designed to evaluate an LLM’s understanding and recall across nine distinct cybersecurity domains:
- Disaster recovery and business continuity planning (BCP)
- Identity and access management (IAM)
- IoT security
- Cryptography
- Wireless security
- Network security
- Cloud security
- Penetration testing
- Compliance/audit
The dataset is conveniently available in four distinct sizes: 80, 500, 2000 and 10,000 questions.
What is InstructLab ?
InstructLab is an open source platform designed by Red Hat and IBM to simplify the process of customizing and aligning LLMs for specific domains. The method-based on the LAB method (Large-scale Alignment for chatBots)—makes it possible to enhance models efficiently with minimal human input or compute resources.
InstructLab achieves this by injecting knowledge from taxonomy, automatically generating synthetic data and fine-tuning models for specific behaviors and tasks using skillful approaches. Enhanced models can be served locally using the ilab CLI with backends like vLLM or llama.cpp.
InstructLab is unique in its support for upstream contributions and continuous community-driven improvements, unlike traditional fine-tuning workflows. It is model-agnostic and powers regularly updated versions of open-weight models such as IBM Granite and Merlinite (derived from Mistral).
Benchmarked model types:
- Granite models: These are the foundational LLMs developed by IBM. Models that end with the word 'instruct' are specifically adapted for following instructions and participating in conversational or reasoning tasks
- InstructLab models: These models represent community-driven fine-tuning. Typically, they are based on foundational models like Granite, but have been further trained with InstructLab tooling and methodology, with the aim of achieving general-purpose or domain-aligned performance
Why these specific models?
Our choice of models was based on the intention of providing a relevant comparison point, particularly against the official CyberMetric leaderboard. Choosing the merlinite-7b-pt, granite-3.0-8b-lab-community, granite-3.0-2b-instruct, and granite-3.0-8b-instruct models was a decision that fit the benchmark's release period.
Our evaluation included the most recent IBM Granite 3.3 models (granite-3.3-8b-instruct and granite-3.3-2b-instruct). This allows us to showcase the performance evolution of the Granite models.
Model serving via InstructLab
All models were served locally on our RHEL AI VM using the ilab command. The process involves downloading the model and then serving it:
ilab model download --repository ibm-granite/granite-3.3-8b-instruct --hf-token <your_token>
Once downloaded, serving is initiated:
ilab model serve --model-path ~/.cache/instructlab/models/ibm-granite/granite-3.3-8b-instruct --gpus 1
Mitigating GPU memory limitation
There is an issue due to our limited setup environment that only has a single L4 GPU. During model serving through InstructLab (which utilizes vLLM as the backend), we have encountered a common problem where some model configurations caused GPU memory exhaustion due to a large max_position_embeddings value. Specifically, several models had this parameter set to ‘131072’ in their config.json, which significantly increased the memory required by the key-value (KV) cache in vLLM, often resulting in out-of-memory (OOM) errors.
Solution:
To address this, we manually modified the config.json file to set a lower, more hardware compatible value:
"max_position_embeddings": 4096
This value defines the maximum number of tokens the model can handle in a sequence, based on its positional encoding. By reducing it to 4096, the KV cache memory footprint is significantly reduced while still being sufficient for the CyberMetric dataset, which features relatively short multiple-choice questions. The model's accuracy remains unaffected by this adjustment because our use case inputs do not exceed this token length.
By making this change, we were able to successfully serve the models without instability or crashes, enabling the benchmarking process to continue smoothly on our single GPU setup.
Script adaptation and enhancement
We adapted and further enhanced the original CyberMetric evaluation script, which was initially designed to interact with OpenAI API, to support benchmarking against our locally served models via InstructLab. The key modifications are:
- Changing the API call mechanism from openai.ChatCompletion.create in favor of requests.post library to send HTTP requests directly to the local vLLM server endpoint exposed by InstructLab
- Removing API key authentication, as it was no longer necessary for a local server
We made only minimal changes to the core logic of the original Cybermetric script to preserve the integrity and reproducibility of the benchmark methodology. As part of the enhancement, we also introduced a key parameter configuration not present in the original version:
- Since the CyberMetric script evaluates models from multiple providers (OpenAI, Qwen, Mistral, etc.), the lack of a fixed temperature setting could lead to variability across runs, depending on each model's default behavior. Our modification explicitly sets the temperature to 0.0 so results are reproducible and comparable across all tested models
Benchmark results and analysis
For our evaluation, we used the CyberMetric benchmark dataset as the foundation. Rather than relying solely on the aggregated leaderboard, we organized the results by model size by grouping models into comparable parameter classes (~2B, 7B and 8B). This approach allows a fair and meaningful comparison by evaluating models within the same capacity range, avoiding skewed results due to differences in model scale. In addition, we have excluded all proprietary models that do not disclose the model size to preserve the integrity of the comparison.
~2B parameter-class models
This category includes LLMs ranging from 1.5B to 2.7B parameters.
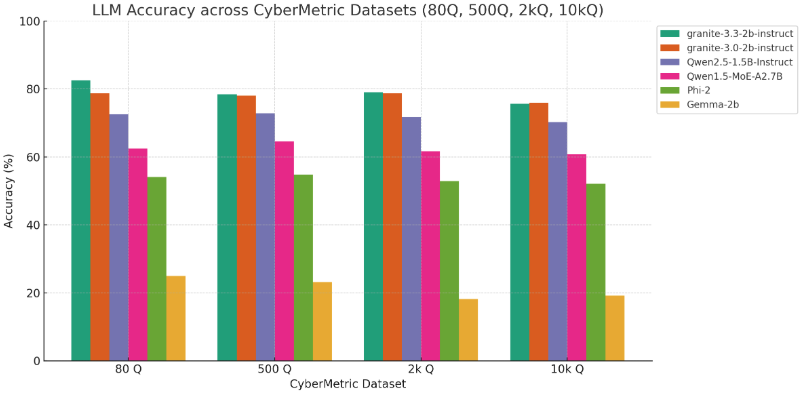
Observations:
- Granite-3.3-2b-instruct stands out as the leading model in this category, achieving an average accuracy of almost 79%. It significantly surpasses all other competitors and demonstrates enhancements compared to its earlier version, Granite-3.0
- The step up from Granite-3.0 to Granite-3.3 yields a +1% gain in average accuracy which is noticeable particularly at the smaller scales (80Q and 2kQ), suggesting better instruction tuning or domain alignment
- Although Qwen2.5-1.5B-Instruct shows decent performance, its reduced accuracy with larger datasets indicates a weaker grasp of cybersecurity subjects
- Non-instruct models like Qwen1.5-MoE and Phi-2 fall significantly behind, showing the critical role of instruction tuning for this task
- Gemma-2b underperforms in all datasets and appears unsuited for cybersecurity QA tasks without significant fine-tuning
7B parameter-class models
This category includes LLMs with 7B parameters.
LLM model | Instruction fine-tuned | Company | Size | License | 80 Q | 500 Q | 2k Q | 10k Q |
Qwen2.5-7B-Instruct | ✔ | Qwen | 7B | Apache 2.0 | 92.50% | 89.20% | 87.45% | 83.56% |
Falcon3-7B-Instruct | ✔ | TII | 7B | Apache 2.0 | 91.25% | 85.60% | 84.25% | 80.72% |
Qwen2-7B-Instruct | ✔ | Qwen | 7B | Apache 2.0 | 91.25% | 84.40% | 82.00% | 78.75% |
Merlinite-7b-pt | ✔ | Instructlab | 7B | Apache 2.0 | 86.25% | 81.20% | 81.95% | 79.63% |
Mistral-7B-Instruct-v0.2 | ✔ | Mistral AI | 7B | Apache 2.0 | 78.75% | 78.40% | 76.40% | 74.82% |
Zephyr-7B-beta | ✔ | HuggingFace | 7B | MIT | 80.94% | 76.40% | 72.50% | 65.00% |
Gemma-1.1-7B-it | ✔ | 7B | Open | 82.50% | 75.40% | 75.75% | 73.32% | |
Qwen1.5-7B | ✘ | Qwen | 7B | Open | 73.75% | 70.10% | 69.96% | 65.17% |
Qwen-7B | ✘ | Qwen | 7B | Open | 68.42% | 64.08% | 63.84% | 54.09% |
DeciLM-7B | ✘ | Deci | 7B | Apache 2.0 | 56.55% | 56.20% | 53.85% | 51.32% |
Gemma-7b | ✘ | 7B | Open | 42.50% | 37.20% | 36.00% | 34.28% |
Observations:
- Merlinite-7b-pt stands out as the best-performing community-aligned model below the top-tier leaders, with average accuracy over 82%
- Although leading models such as Qwen2.5-7B-Instruct excel in overall accuracy, the gap with Merlinite-7b-pt narrows considerably when applied to larger datasets, with Merlinite even surpassing it on the 10K dataset
- Non-instruct models such as DeciLM-7B and Gemma-7B show steep drops in performance and are not viable for cybersecurity without extensive tuning
8B parameter-class models
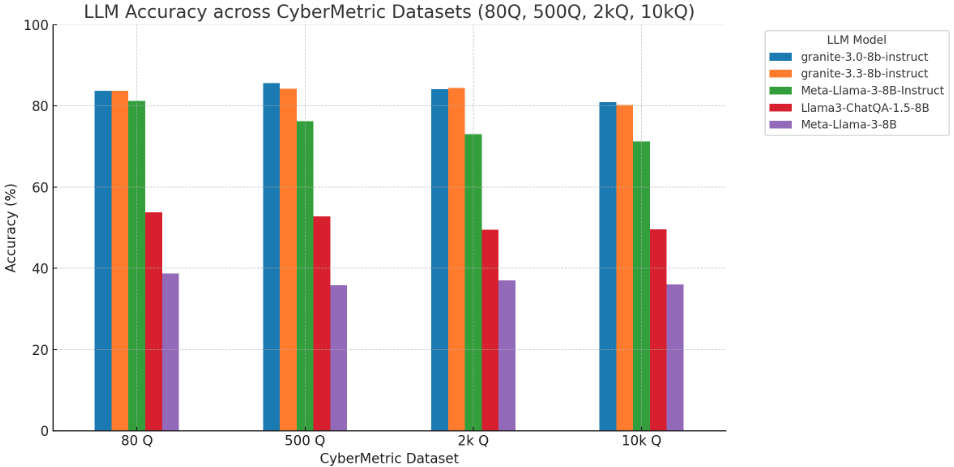
Observations:
- Granite-3.0-8b-instruct tops the 8B category with an impressive average accuracy of 83.61% across all CyberMetric datasets. Its performance remains consistent and reliable, exhibiting a decline of less than 3% from 80Q to 10kQ, which is essential for reasoning in long-context cybersecurity scenarios
- Compared to Granite-3.3-8b-instruct, the 3.0 version slightly outperforms on average, despite the newer release. While 3.3 shows a marginal edge at 2kQ, its drop at 10kQ (80.22%)
- Meta-Llama-3-8B-Instruct underperforms relative to both Granite models, particularly in large-scale datasets. It drops by over 10 percentage points from 80Q to 10kQ, revealing weaker domain adaptation despite instruction tuning
- Base models like Llama3-ChatQA-1.5-8B and Meta-Llama-3-8B deliver poor results across the board, with accuracy hovering near 50% and 37%, respectively. This indicates that instruction tuning is crucial for benchmarks of the CyberMetric type
- Overall, Granite-3.0/3.3-instruct offer the most reliable 8B-class models for cybersecurity tasks, delivering top-tier accuracy without relying on proprietary APIs and making them highly suitable for self-hosted deployments
Access to evaluation scripts and detailed results
To support reproducibility and further analysis, we have published a GitHub repository containing:
- The modified CyberMetric evaluation script adapted for local serving via InstructLab
- Raw benchmarking outputs for all tested models
- A breakdown of incorrectly answered questions for each model and dataset size
This resource allows readers to inspect model-specific failure cases and better understand performance differences in cybersecurity reasoning.
Wrapping up
Based on our testing, we found the following:
Granite-3.3-2b-instruct clearly leads the ~2B category, establishing a benchmark for compact, instruction-optimized models in the field of cybersecurity. Its capability to sustain performance across varying dataset sizes while utilizing fewer parameters than many rivals positions it as an excellent option for environments with limited resources.
Merlinite-7b-pt proves to be one of the most balanced and domain-resilient 7B models. While not the highest scoring, it offers exceptional value for community-driven projects needing strong cybersecurity performance without proprietary dependencies.
Granite-3.0 and 3.3 set the benchmark for open source 8B models in cybersecurity reasoning. They offer a rare mix of high accuracy, stability across scales and open licensing—making them ideal for cost-effective deployments. Compared to competitors, Granite-8B models deliver near state-of-the-art performance.
product trial
Red Hat Enterprise Linux Server 無料製品トライアル | Red Hat
執筆者紹介

チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細
仮想化
オンプレミスまたは複数クラウドでのワークロードに対応するエンタープライズ仮想化の将来についてご覧ください