While organizations are quickly adopting private and local AI solutions due to data privacy and full control over deployment scenarios, they still face performance and resource challenges during inference, or when the model is actually processing data. Fortunately, the latest open large language models (LLMs) are now as robust as closed models, but the key to maximizing performance and efficiency is through model optimization and compression.
We know that open models enable customization without vendor lock-in or prohibitive costs, and this article will guide you through the process of getting started with optimizing open models. Leveraging techniques such as quantization, sparsity and more, we'll learn how to significantly accelerate model responses and reduce infrastructure costs while maintaining model accuracy.
What is LLM compression and optimization?
We’ve noticed a trend of LLMs increasing in size, with tens or hundreds of billions of parameters added to support new capabilities and achieve higher benchmarks. But these dense model architectures challenge many organizations trying to scale their own AI solutions. This has led to model compression and optimization, which encompasses a range of techniques to create LLMs and systems which are smaller (reduced storage and memory requirements), faster (significant computational boosts) and more energy-efficient.
Real world benefits and case studies
Leading technology companies are already achieving significant benefits from LLM compression and optimization at scale.
- LinkedIn’s domain-adapted EON models—built on open source LLMs and tailored with proprietary data—enabled rapid, cost-effective deployment of gen AI features, such as improved candidate-job matching, while reducing prompt size by 30% and maintaining responsible AI practices
Roblox, scaled from supporting less than 50 to roughly 250 concurrent ML inference pipelines by optimizing its hybrid cloud infrastructure with open source frameworks like Ray and vLLM. This allowed Roblox to efficiently orchestrate real-time and batch inference across thousands of CPUs and GPUs, significantly reducing compute costs and boosting developer productivity. These real-world examples highlight how model compression, hardware-specific deployment and orchestration technologies are driving faster, more affordable and highly scalable AI models and applications without compromising accuracy or user experience.
Faster and cheaper inference through compressed models
As the demand for advanced AI capabilities continues to grow, so does the need for efficient ways to deploy and run these models on available hardware resources. This is exactly where LLM compression and optimization come into play—by applying various methods we can significantly reduce the computational requirements of AI without sacrificing performance.
Quantization of models for memory and computational savings
To accelerate inference and shrink model size, a leading choice is quantization, a technique used to convert high-precision model weights (such as 32-bit floating point) to lower formats (including 8-bit integers or 8-bit floating point). The biggest impact here is reducing the amount of memory needed to run the model, for example being able to deploy a Llama 70B parameter model on a single NVIDIA A100 GPU as opposed to requiring four A100s for the same un-quantized model. Quantization can also be applied to weights, activations or both, and can be done before or at runtime.
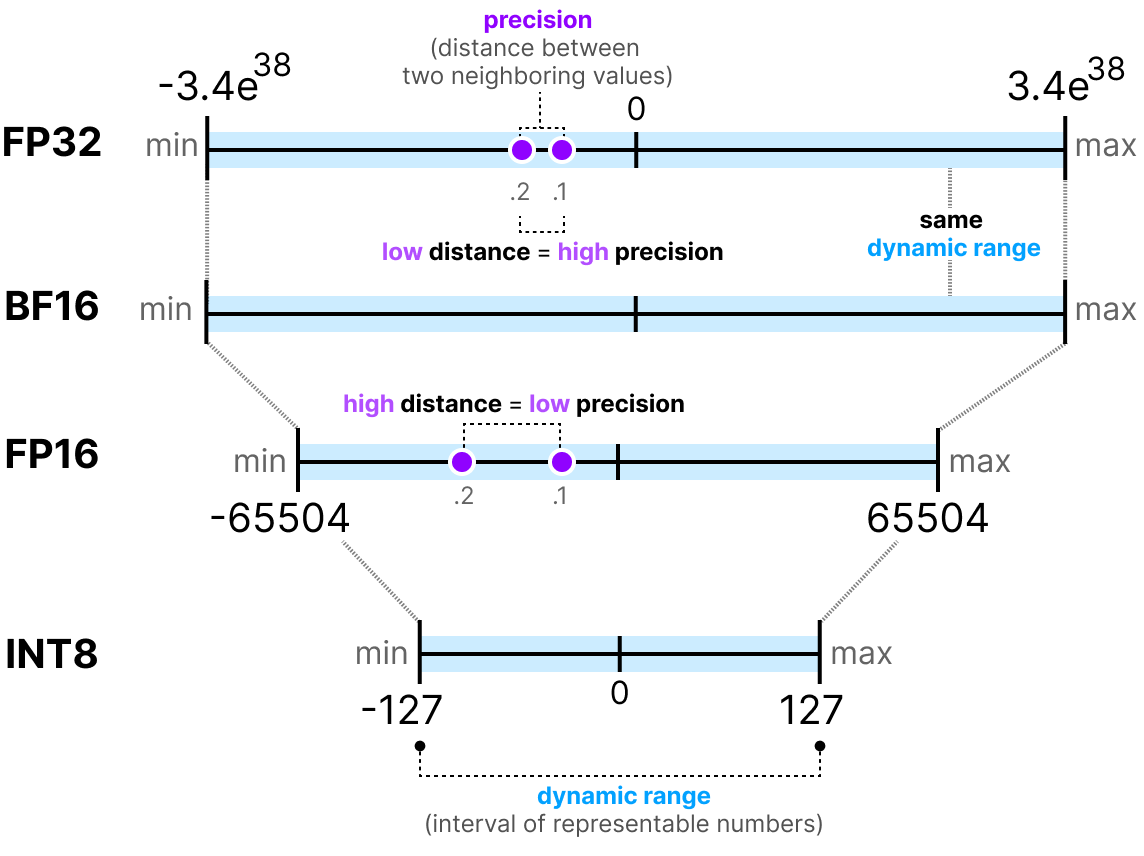
Sparsity and pruning for reducing model size
Other techniques to decrease storage, memory and computational demands—while maintaining most of the model's accuracy and performance—include sparsity and pruning. These strategically removes or reduces the significance of less important connections and information within a model.
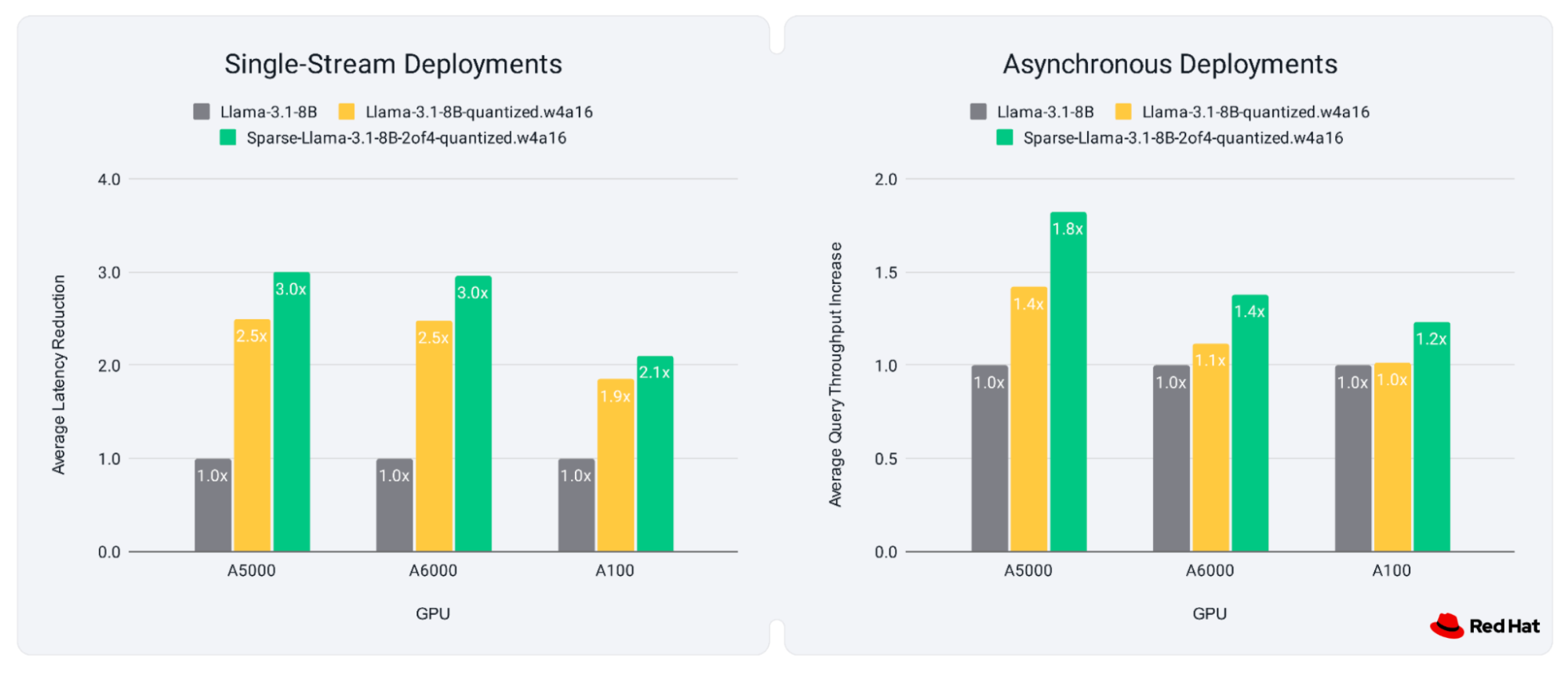
While less common than quantization, let’s take a look at the 2:4 Sparse Llama, which achieved 98.4% accuracy recovery on the Open LLM Leaderboard V1, and full accuracy recovery on fine-tuning tasks. This refers to a 2:4 sparsity pattern, where for each group of four weights, two are retained while two are pruned.
Afterwards, the sparse model was trained with knowledge distillation for 13 billion tokens to recover the accuracy loss incurred by pruning, and delivered up to 30% higher throughput and 20% lower latency from sparsity alone. In cases where quantization alone offers only minimal improvements, sparsity can offer throughput increases, and can also be combined with quantization to offer even better performance!
Red Hat AI’s optimized model repository
While these model compression techniques sound great, how can you actually get started and benefit from them?
Fortunately, Red Hat maintains a repository of pre-optimized LLMs for enterprise deployment, benchmarked and ready for inference!
Hosted on Hugging Face, you can choose from various popular AI LLMs, including Llama, Qwen, DeepSeek, Granite and more. The selection of quantized and compressed models can be downloaded and deployed across any environment.
Specifically, these optimized variants include:
- The full safe tensors needed to deploy with your choice of inference server
- Instructions on using them with vLLM
- Accuracy information based on popular LLM evaluations to provide clarity around before/after model compression
Just like that, you can begin to cut GPU requirements and costs in half!
Optimize your own model with LLM Compressor
Sure, foundational models are great and cover a variety of use cases, but many of us experiment with custom, fine-tuned models to become a domain expert or to accomplish a task.
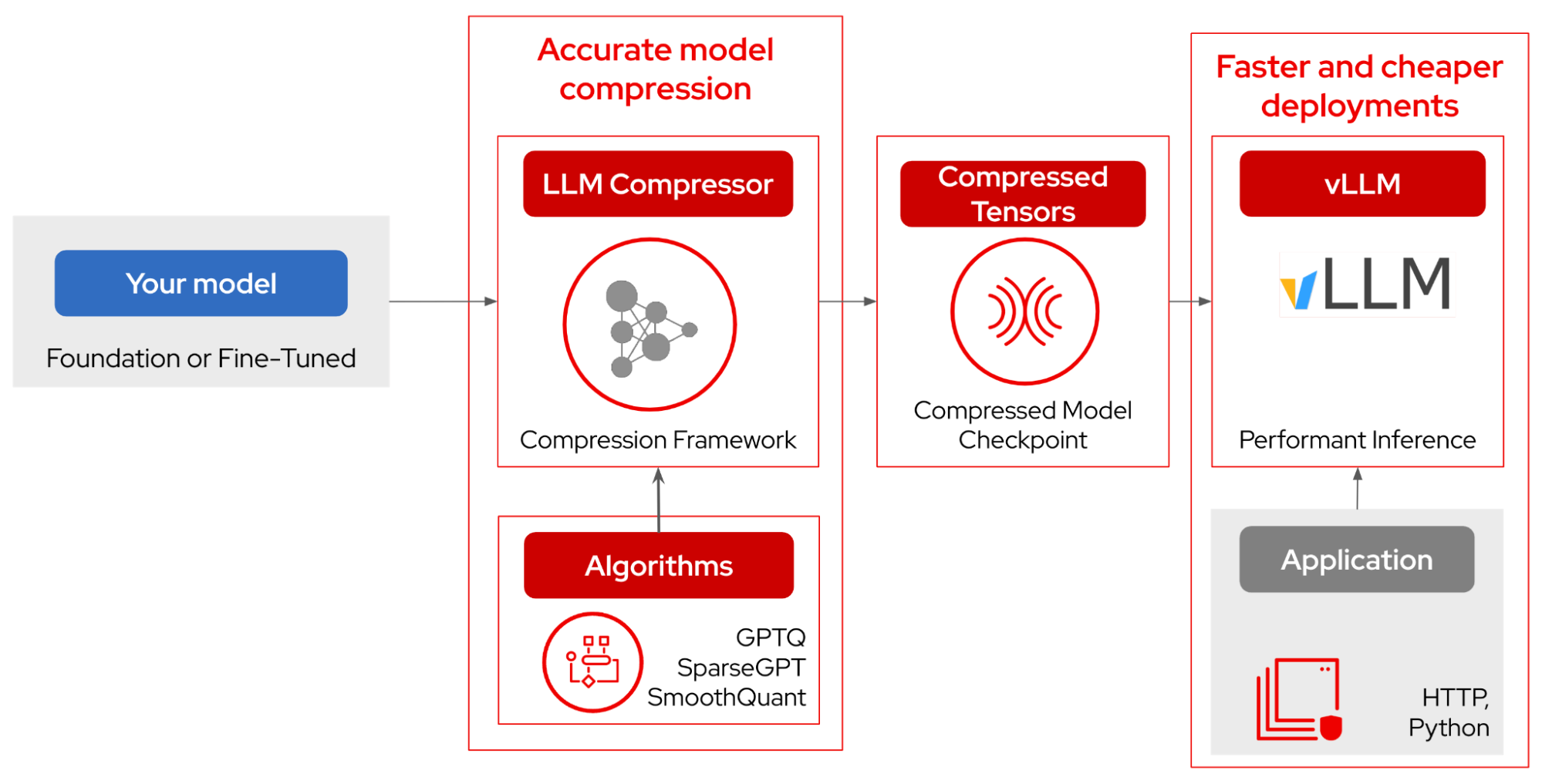
How can you compress and optimize a model yourself? That’s where the LLM Compressor library comes in. Using the same quantization algorithms used by the Red Hat model repository, you can apply various optimization techniques to your unique model (check this document to learn which to choose).
These techniques include GPTQ (4-bit weight quantization), SmoothQuant (INT8 activation quantization) and SparseGPT (50% structured sparsity). You can get started compressing models in less than 10 lines of code and the compressed tensors can be directly exported for accelerated serving via vLLM’s custom kernels for inference and usage in your applications.
Deploying optimized models on the hybrid cloud
Many enterprises are looking to move workloads from public to private clouds, and AI is no exception. In fact, many AI strategies involve some sort of hybrid solution, balancing between control (on-premises) and scalability (public cloud).
With vLLM, an open source project that is now becoming the de facto standard for LLM serving and inference, you get to make the choice of where and how your models run. As a high-throughput and memory-efficient inference and serving engine for models, you can use model compression techniques to significantly accelerate model responses and reduce infrastructure costs.
For example, you may be looking to deploy your models on Linux, and after installing vLLM, you can serve an OpenAI-compatible HTTP server using the following command as an example for a quantized Llama 4 model:``
vllm serve RedHatAI/Llama-4-Scout-17B-16E-Instruct-FP8-dynamicYou may be looking to distribute your workload across various infrastructures, however, using auto-scaling technology like Kubernetes. Using vLLM as a runtime in conjunction with KServe for serverless inferencing and Ray for distributing the workload can enable a truly elastic inference platform.
At Red Hat, we contribute to these projects via Open Data Hub and offer our own platform, Red Hat OpenShift AI, which allows you to seamlessly deploy and scale models over the hybrid cloud.
Wrapping up
The future of AI is open, and it's here now. Open source AI models are matching and even exceeding the performance of proprietary alternatives, giving you complete control over your deployments and data privacy. To truly harness this power, optimizing these models with techniques like quantization, sparsity and pruning is crucial. This allows you to boost inference while minimizing infrastructure needs.
By leveraging pre-optimized models or tools like LLM Compressor, you can significantly reduce memory footprint. This can translate to up to 3x faster throughput, 4x lower latency and a 2-4x improvement in inference. No matter where you deploy your models, you can now build a faster, more cost-efficient AI system.
product trial
Red Hat Enterprise Linux AI | 제품 체험판
저자 소개

Cedric Clyburn (@cedricclyburn), Senior Developer Advocate at Red Hat, is an enthusiastic software technologist with a background in Kubernetes, DevOps, and container tools. He has experience speaking and organizing conferences including DevNexus, WeAreDevelopers, The Linux Foundation, KCD NYC, and more. Cedric loves all things open-source, and works to make developer's lives easier! Based out of New York.

Legare Kerrison is a Technical Marketing Manager and Developer Advocate working on Red Hat's Artificial Intelligence offerings. She is passionate about open source AI and making technical knowledge accessible to all. She is based out of Boston, MA.
유사한 검색 결과
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래