すべての GPU をデータセンターに設置できない理由
スケーリング、管理、環境の問題に対処するためには、IT アーキテクチャに対する一元化されたアプローチが推奨されてきました。次のようなユースケースはこのアプローチによるものです。
- ハードウェアを格納するデータセンターを大規模で優れたものにする
- ノードやハードウェアを追加するための余地が基本的にいつでも残っており、これらはすべてローカルで (場合によっては同じサブネット上で) 管理できる
- 電力、冷却、接続性は常時確保され、冗長化されている
壊れていないソリューションを修正する必要があるのかと問われそうですが、修正が必要な訳ではなく、画一的なソリューションであらゆるニーズに対応できることはほとんどないということを覚えておく必要があります。一例として、製造業での品質管理を見てみましょう。
製造業の品質管理
工場や組立ラインには数百、時には数千のエリアが存在する場合があり、各エリアでは組立ラインで特定のタスクが実行されます。従来のモデルでは、各デジタルステップまたは実際のツールは、その作業を実行するだけでなく、作業結果をはるか遠くのクラウド内の中央アプリケーションに中継する必要がありました。これについては次のような疑問が生じることがあります。
- スピード:写真を撮影し、クラウドにアップロードし、中央アプリケーションで分析し、応答を送信してアクションを実行するのに、どれくらい時間がかかるのか?収益の減少を覚悟して作業スピードを落とすのか、それとも複数のエラーや事故のリスクを冒して速度優先にするのか?意思決定はリアルタイムまたはそれに近い形で行われるのか?
- 量:すべてのセンサーからの生データのストリームを継続的にアップロードまたはダウンロードするためには、どのくらいのネットワーク帯域幅が必要になるのか?それは可能か?途方もなく高いコストがかからないか?
- 信頼性:ネットワーク接続が中断した場合はどうなるのか、工場全体が停止してしまうのか?
- 拡張:ビジネスが順調な場合、あらゆる場所にあるすべてのデバイスから取得する生データを処理できるように中央データセンターを拡張できるのか?可能な場合、どれくらいの費用が必要か?
- セキュリティ:生データの中に機密データと見なされるものが含まれていないか?該当のエリア外に送信することは許可されるのか?どこかに保存するのか?ストリーミングして分析する前に暗号化する必要があるのか?
エッジへの移行
これらの質問のいずれかで答えに詰まった場合は、エッジコンピューティングを検討する価値があります。エッジコンピューティングとは簡単に言うと、より小さくてレイテンシーの影響を受けやすい機能、またはプライベートなアプリケーション機能をデータセンター外に移動させ、実際の作業が行われている場所のすぐそばに配置することです。エッジコンピューティングはすでに広く利用されています。私たちが運転する車や、ポケットの中に入れているスマートフォンに使われています。エッジコンピューティングは、スケールを問題からメリットに変えます。
もう一度、製造業の例を見てみましょう。各組立ラインの近くに小さなクラスタがあれば、上記の問題はすべて軽減できます。
- スピード:完了したタスクの写真をそのサイトで確認でき、ローカルハードウェアを使用することで遅延を軽減できます。
- 量:外部サイトへの帯域幅を大幅に削減し、経常的なコストを節約できます。
- 信頼性:広域ネットワーク接続が中断しても、ローカルで作業を続行し、接続が再確立されたときに中央のクラウドに再同期できます。
- スケール:工場が 2 つでも 200 でも、必要なリソースは各ロケーションにあるので、ピーク時に稼働させるためだけに中央データセンターを大規模に構築する必要性を低減できます。
- セキュリティ:生データをその場所から外に出さないため、潜在的な攻撃対象領域が減少します。
エッジ + パブリッククラウドの組み合わせ
業界をリードするエンタープライズ Kubernetes プラットフォームである Red Hat OpenShift は、最も必要とされる場所にアプリケーション (およびインフラストラクチャ) を配置できる柔軟な環境を提供します。この場合、一元化されたパブリッククラウドで実行できるだけでなく、同じアプリケーションを組立ラインに移動させることができます。アプリケーションはその場でデータをすばやく取り込み、処理し、その場で対応できます。それが、エッジでの機械学習 (ML) です。エッジコンピューティングとプライベートクラウドおよびパブリッククラウドを組み合わせる例を 3 つ見てみましょう。1 つ目は、エッジコンピューティングとパブリッククラウドを組み合わせたものです。
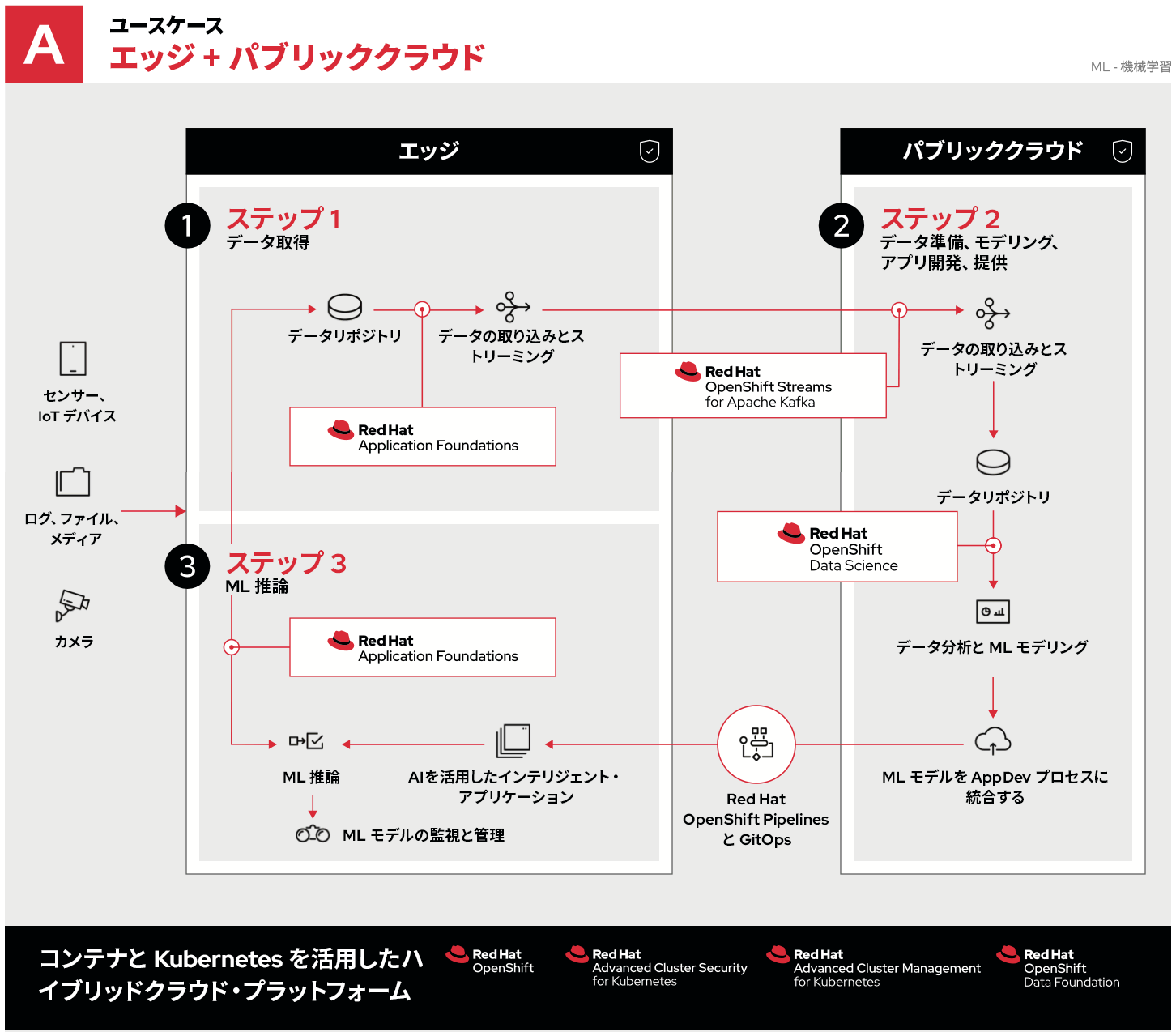
- データの取得はサイトで行われ、サイトで生データが収集されます。測定や作業を実行するセンサーや IoT (モノのインターネット) デバイスは 、Red Hat AMQ ストリームまたは AMQ ブローカー・コンポーネントを使用してローカルのエッジサーバーに接続できます。それらのサーバーは、小規模なシングルノードから大規模な高可用性クラスタまで、アプリケーションの要件に応じてさまざまな構成が可能です。大きな利点となるのは、これらは組み合わせることができるため、リモートエリアには小規模なノードを配置し、より多くのスペースがある場所にはより大規模なクラスタを配置できることです。
- データの準備、モデリング、アプリケーションの開発、提供は、実際に作業が行われる場所で実行されます。データが取り込まれ、保存され、分析されます。組立ラインの例で言えば、パターン (材料やプロセスの欠陥など) についてウィジェットのイメージが分析されます。実際の学習はここで行われます。新たに得られた知見は、エッジに存在するクラウドネイティブ・アプリケーションに統合されます。これらのすべてがエッジで行われるわけではありません。負荷の高い中央処理装置およびグラフィックス・プロセッシング・ユニット (CPU/GPU) を高密度の一元化されたクラスタで実行すれば、軽量のエッジデバイスで実行する場合と比較してプロセスを数日から数週間単位でスピードアップすることができるからです。
- Red Hat OpenShift Pipelines と GitOps を使用することで、開発者は継続的インテグレーションおよび継続的デリバリー (CI/CD) を使用してアプリケーションを継続的に改善し、プロセスを可能な限り迅速化することができます。獲得した知識を活用するスピードが増すほど、時間とリソースをより効率的に収益創出に集中させることができます。そしてエッジに戻し、人工知能を活用した新しい (更新された) アプリケーションが新しい知識を使用してデータを監視し、取り込んでから、最近のモデルと比較します。このサイクルは、継続的な改善の一環として繰り返されます
エッジ + プライベートクラウドの組み合わせ
2 つ目の例では、ステップ 2 がオンプレミスのプライベートクラウドで行われることを除き、プロセス全体は先ほどと同じです。
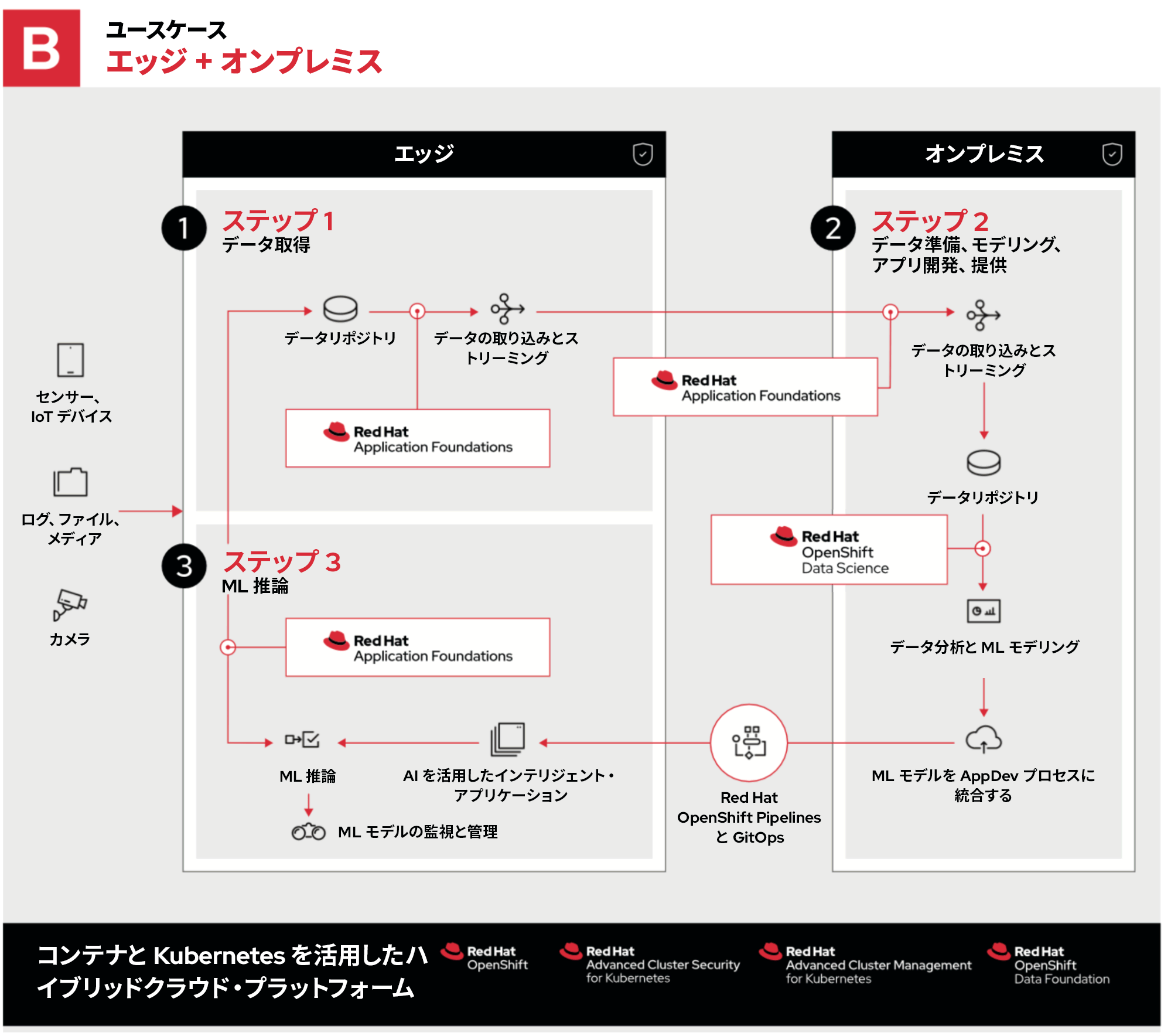
組織がプライベートクラウドを選択する理由は、次のとおりです。
- すでにハードウェアを所有しており、既存の資産を使用できる
- データロケールとセキュリティに関する厳格な規制に従う必要がある。機密データをパブリッククラウドに保存すること、およびパブリッククラウドを通過させることができない
- FPGA、GPU、パブリッククラウド・プロバイダーからレンタルできない構成など、カスタムハードウェアが必要
- ローカルハードウェアよりもパブリッククラウドで実行するほうがコストがかかる特定のワークロードがある
これらは、OpenShift で実現できる柔軟性を示す例の一部です。その方法は単純で、Red Hat OpenStack Platform プライベートクラウド上で OpenShift を実行するだけです。
エッジ + ハイブリッドクラウドの組み合わせ
最後の例では、パブリッククラウドとプライベートクラウドからなるハイブリッドクラウドを使用します。
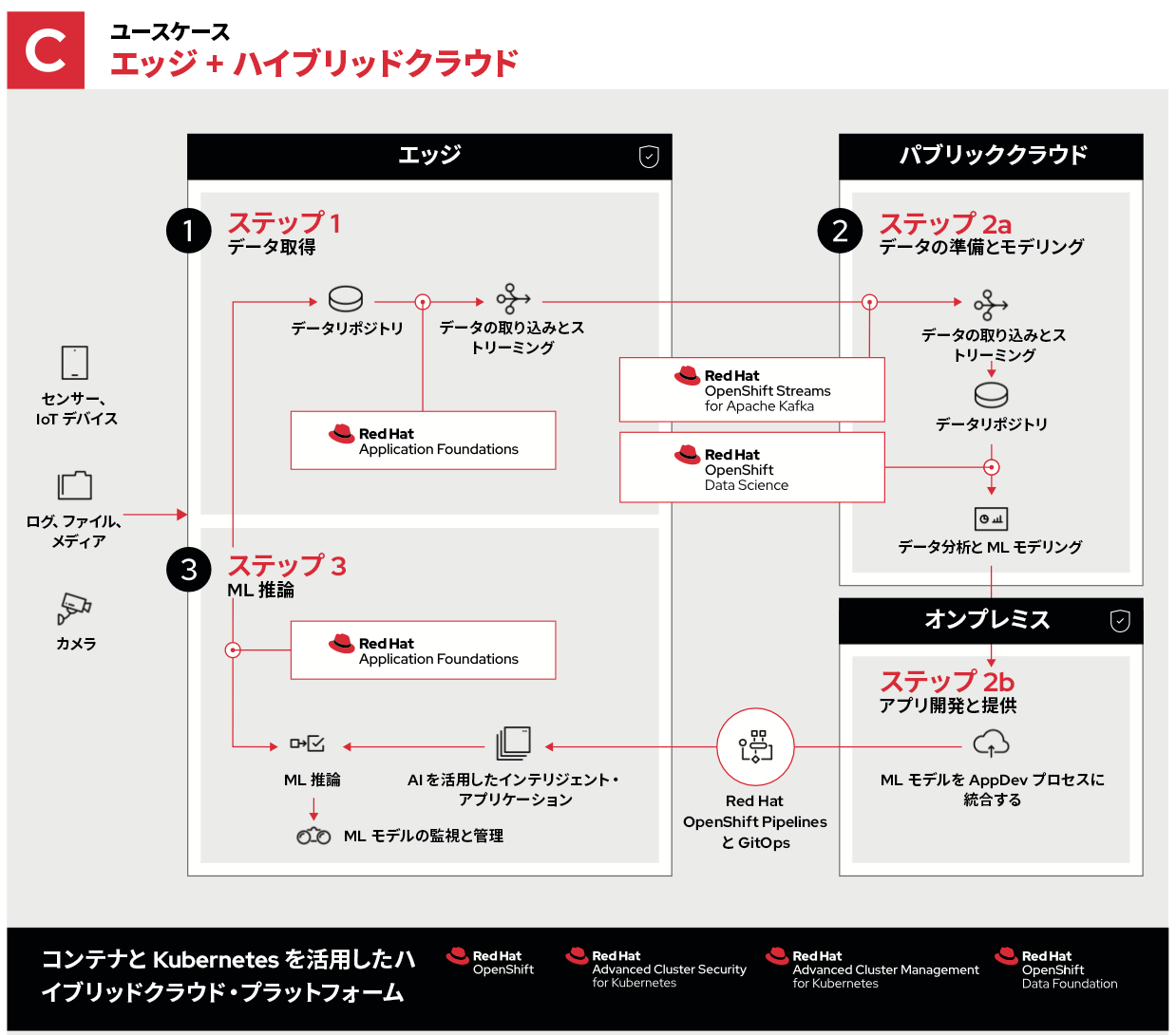
この場合でも、ステップ 1 と 3 は同じです。ステップ 2 のプロセスも同じですが、最適な環境で実行されるように分散されています。
- ステップ 2a はエッジからのデータの取り込み、保存、分析です。パブリッククラウドのリソースの規模、地理的な多様性、接続性を活用して、データを収集し、解析します。
- ステップ 2b ではオンプレミスでのアプリケーション開発が可能になります。これにより、特定の開発ワークフローを高速化、保護、あるいはカスタマイズしてからそれらの更新をエッジに送り返すことができます。
Red Hat が提供するもの
考慮する必要がある変数や検討事項の数を考えると、優れたエッジコンピューティング環境には柔軟性が欠かせません。Red Hat は、低速で信頼性が低い、またはネットワーク接続がない環境への対応や、厳格なコンプライアンス、極端なパフォーマンス要件への対応など、適切なアプリケーションを適切な場所で実行できるように調整された柔軟なソリューションを構築するために必要なツールを提供します。
エッジ、広く利用されているパブリッククラウド、オンプレミスのプライベートクラウドなど、どこで知見が得られるかにかかわらず (または、それらのすべての場所で得られる場合でも)、開発者は使い慣れたツールを使用して、(OpenShift で実行されている) クラウドネイティブ・アプリケーションを継続的に革新し、最適な方法と場所で実行することができます。
執筆者紹介

Ben has been at Red Hat since 2019, where he has focused on edge computing with Red Hat OpenShift as well as private clouds based on Red Hat OpenStack Platform. Before this he spent a decade doing a mix of sales and product marking across telecommunications, enterprise storage and hyperconverged infrastructure.
チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細
仮想化
オンプレミスまたは複数クラウドでのワークロードに対応するエンタープライズ仮想化の将来についてご覧ください