생성형 AI의 혁신 속도에 발맞춰 LLM(대규모 언어 모델)을 배포할 수 있는 강력하고 유연하며 효율적인 솔루션이 필요합니다. 오늘은 Red Hat AI Inference Server를 살펴보겠습니다. 이 서버는 Red Hat AI 플랫폼의 핵심 구성 요소로서, Red Hat OpenShift AI와 Red Hat Enterprise Linux AI(RHEL AI)에 포함됩니다. AI Inference Server는 하이브리드 클라우드 환경 전반에서 실질적인 이식성과 함께 최적화된 LLM 추론 기능을 제공하도록 설계된 독립 실행형 제품으로도 제공됩니다.
AI Inference Server는 어떠한 배포 환경에서도 지원되는 강화된 vLLM 배포판과 지능형 LLM 압축 툴, Hugging Face에 최적화된 모델 리포지토리를 함께 제공합니다. 이는 모두 Red Hat의 엔터프라이즈 지원과 타사 지원 정책에 따른 타사 배포 유연성을 기반으로 합니다.
vLLM 코어 및 고급 병렬 처리를 통한 추론 가속화
AI Inference Server의 중심에는 vLLM 서빙 엔진이 있습니다. vLLM은 처리량과 메모리 효율성이 높은 성능으로 유명합니다. PagedAttention(GPU 메모리 관리 최적화, 캘리포니아대학교 버클리의 연구에서 시작됨) 및 지속적 배치(Continuous Batching)와 같은 혁신적인 기술을 통해 구현되며, 기존 서빙 방식 대비 몇 배 더 높은 성능을 실현하는 경우도 많습니다. 또한 이 서버는 일반적으로 OpenAI 호환 API 엔드포인트를 노출하여 통합을 간소화합니다.
다양한 하드웨어에서 오늘날의 대규모 생성형 AI 모델을 처리하기 위해 vLLM은 다음과 같이 강력한 추론 최적화 기능을 제공합니다.
- TP(텐서 병렬 처리): 일반적으로 특정 노드 내에서 여러 GPU에 개별 모델 계층을 분할하여 해당 계층의 대기 시간을 줄이고 컴퓨팅 처리량을 높입니다.
- PP(Pipeline 병렬 처리): 다양한 GPU 또는 노드에서 순차적인 모델 계층 그룹을 스테이징합니다. 이는 단일 멀티 GPU 노드로는 처리할 수 없는 대규모 모델을 다루는 데 중요합니다.
- MoE(전문가 혼합, Mixture of Experts) 모델을 위한 EP(전문가 병렬 처리): vLLM에는 MoE 모델 아키텍처를 효율적으로 처리하고 고유한 라우팅 및 컴퓨팅 요구 사항을 관리할 수 있는 전문 최적화 기능이 포함됩니다.
- DP(데이터 병렬 처리): vLLM은 개별 요청을 다양한 vLLM 엔진으로 라우팅하는 데이터 병렬 어텐션을 지원합니다. MoE 계층에서는 데이터 병렬 엔진이 결합되어 모든 데이터 병렬 및 텐서 병렬 작업자 전반에 전문가를 샤딩합니다. 이는 KV(키-값 어텐션) 헤드 수가 적은 DeepSeek V3 또는 Qwen3와 같은 모델에서 특히 중요합니다. 이러한 모델에서는 텐서 병렬 처리로 인해 KV 캐시가 비효율적으로 중복됩니다. 이 경우 데이터 병렬 처리를 통해 vLLM을 더 많은 GPU로 확장할 수 있습니다.
- 양자화: LLM Compressor는 AI Inference Server의 구성 요소로, vLLM을 사용하여 더 빠르게 추론할 수 있도록 가중치 및 활성화 양자화 또는 가중치 전용 양자화를 통해 압축 모델을 생성하는 통합 라이브러리를 제공합니다. vLLM에는 양자화를 통한 성능 최적화를 위해 Marlin 및 Machete와 같은 사용자 정의 커널이 있습니다.
- 추측 디코딩(Speculative Decoding): 추측 디코딩은 더 작고 빠른 초안 모델을 사용하여 여러 개의 향후 토큰을 생성하는 방식으로 추론 대기 시간을 개선합니다. 그런 다음 더 큰 주요 모델이 더 적은 단계로 유효성을 검증하거나 수정합니다. 이 접근 방식은 출력 품질을 저하시키지 않으면서도 전체 디코딩 대기 시간을 줄이고 처리량을 늘립니다.
예를 들어, 노드 전반에 파이프라인 병렬 처리를 사용하고 각 노드 내에서는 텐서 병렬 처리를 사용하는 등 이러한 기술을 결합하면 복잡한 하드웨어 토폴로지 전반에서 대규모 모델을 효과적으로 확장할 수 있습니다.
컨테이너화를 통한 배포 이식성
AI Inference Server는 표준 컨테이너 이미지로 제공되며 배포 유연성이 탁월합니다. 이처럼 컨테이너화된 형식은 Red Hat OpenShift, Red Hat Enterprise Linux(RHEL), Red Hat 이외의 쿠버네티스 플랫폼, 기타 표준 Linux 시스템 등 배포 환경과 관계없이 정확히 동일한 추론 환경이 일관되게 실행되도록 한다는 점에서 하이브리드 클라우드 이식성의 핵심입니다. 비즈니스에 필요한 모든 곳에서 LLM을 서빙할 수 있는 예측 가능한 표준화 기반을 제공하여 다양한 인프라 전반에서 운영을 간소화합니다.
다중 가속기 지원
AI Inference Server는 강력한 다중 가속기 지원을 핵심 설계 원칙으로 하여 설계되었습니다. 이러한 기능을 통해 플랫폼은 NVIDIA, AMD GPU, Google TPU를 비롯한 다양한 하드웨어 가속기를 원활하게 활용할 수 있습니다. AI Inference Server는 기반 하드웨어의 복잡성을 추상화하는 통합 추론 서빙 계층을 제공함으로써 상당한 유연성과 최적화 기회를 제공합니다.
이러한 다중 가속기 지원을 통해 사용자는 다음을 수행할 수 있습니다.
- 성능 및 비용 최적화: 특정 모델 특성, 대기 시간 요구 사항, 비용 고려 사항에 따라 가장 적합한 가속기에 추론 워크로드를 배포합니다. 영역에 따라 서로 다른 가속기가 탁월한 성능을 발휘하며, 작업에 적합한 하드웨어를 선택하는 기능으로 성능과 리소스 활용도를 높일 수 있습니다.
- 미래 지향적 배포: 새롭고 더 효율적인 가속기 기술이 출시됨에 따라 서빙 인프라 또는 애플리케이션 코드를 크게 변경하지 않고도 AI Inference Server의 아키텍처를 통합할 수 있습니다. 이는 장기적인 실행 가능성과 적응성을 제공합니다.
- 추론 용량 확장: 다양한 워크로드 요구 사항을 처리하기 위해 동일한 유형의 가속기를 추가하거나 다양한 유형의 가속기를 통합하여 추론 용량을 손쉽게 확장할 수 있습니다. 이를 통해 변화가 많은 사용자 트래픽과 진화하는 AI 모델의 복잡성을 충족하는 데 필요한 민첩성을 제공합니다.
- 가속기 선택: 이 플랫폼은 동일한 소프트웨어 인터페이스로 다양한 가속기 벤더를 지원하므로 단일 하드웨어 공급업체에 대한 종속성을 줄여 하드웨어 조달 및 비용 관리를 더욱 효과적으로 제어할 수 있습니다.
- 인프라 관리 간소화: AI Inference Server는 다양한 가속기 유형 전반에서 일관된 관리 인터페이스를 제공하여 이기종 하드웨어에서 추론 서비스를 배포하고 모니터링하는 것과 관련된 운영 오버헤드를 간소화합니다.
Red Hat 내 Neural Magic 전문성을 활용한 모델 최적화
대규모 LLM을 효율적으로 배포하려면 종종 최적화가 필요합니다. AI Inference Server는 이제 Red Hat에 인수된 Neural Magic의 선구적인 모델 최적화 전문성을 활용하여 강력한 LLM 압축 기능을 통합합니다. 통합된 컴프레서는 SparseGPT와 같은 업계 최고의 양자화 및 희소성 기술을 사용하여 정확도에 큰 영향을 주지 않으면서 모델 크기와 컴퓨팅 요구 사항을 크게 줄여줍니다. 이를 통해 추론 속도가 빨라지고 리소스 활용도가 향상되어 메모리 풋프린트를 크게 줄이고 GPU 메모리가 제한된 시스템에서도 모델을 효과적으로 실행할 수 있습니다.
최적화된 모델 리포지토리를 통한 액세스 간소화
배포를 더욱 간소화하기 위해 AI Inference Server에는 인기 있는 LLM(예: Llama, Mistral, Granite 제품군)으로 구성된 엄선된 리포지토리에 대한 액세스가 포함됩니다. 해당 모델은 Hugging Face의Red Hat AI 페이지에 편리하게 호스팅되어 있습니다.
이러한 모델은 단순한 표준 모델이 아닙니다. 특히 vLLM 엔진에서 고성능으로 실행되도록 통합 압축 기술을 사용하여 최적화되었습니다. 즉, 즉시 배포 가능한 효율적인 모델을 별도의 작업 없이 곧바로 사용할 수 있어 AI 애플리케이션을 프로덕션 환경으로 전환하는 데 필요한 시간과 노력을 크게 줄이고 가치를 더 빠르게 실현할 수 있습니다.
Red Hat AI Inference Server 기술 개요
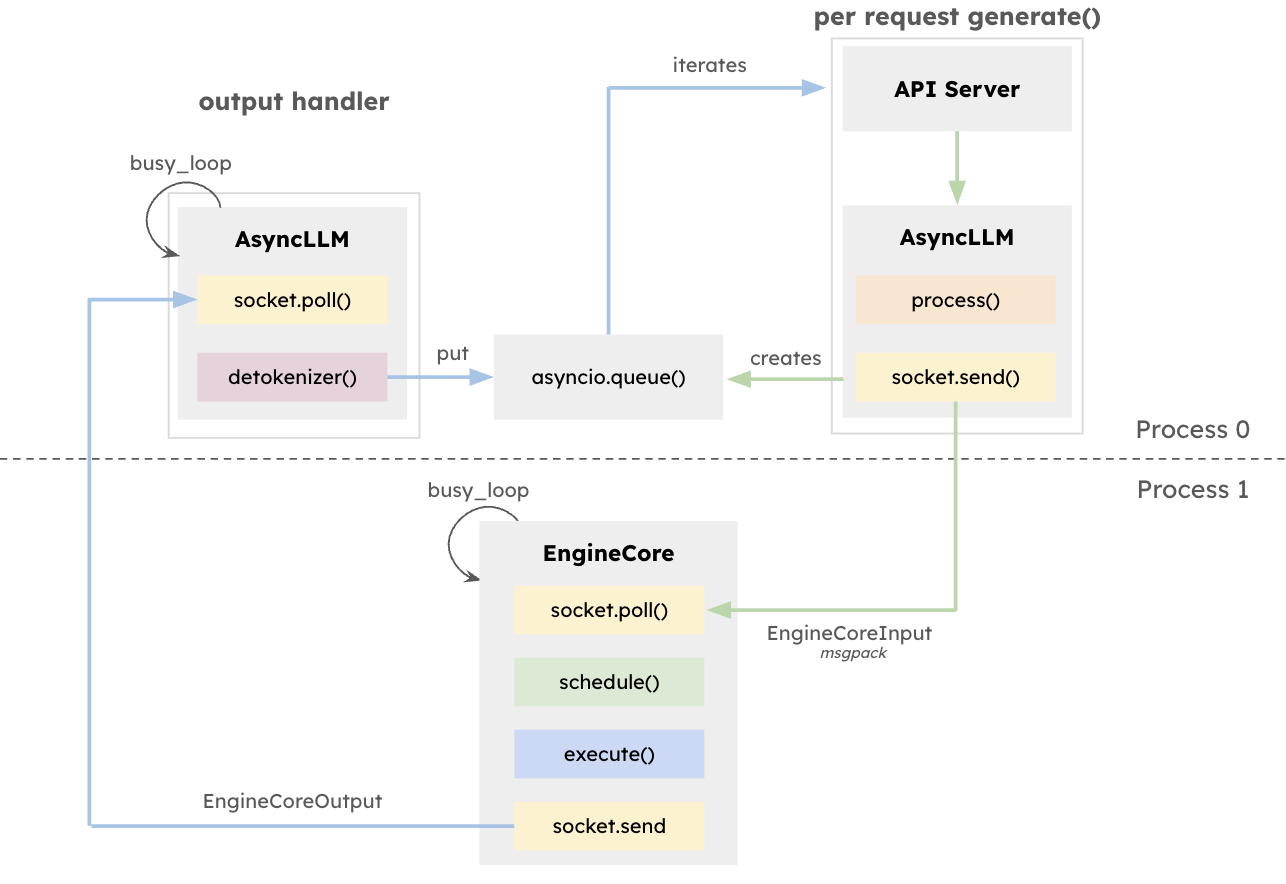
vLLM 아키텍처는 특히 다양한 요청 길이로 높은 동시성을 처리하는 시스템에서 LLM 추론의 처리량을 극대화하고 대기 시간을 최소화합니다. 이 설계의 중심에는 정방향 컴퓨팅을 조정하고 KV 캐시를 관리하며 여러 동시 프롬프트에서 발생하는 토큰을 동적으로 배치하는 전용 추론 엔진인 EngineCore가 있습니다.
EngineCore는 긴 컨텍스트 창을 관리하는 데에서 발생하는 오버헤드를 줄일 뿐만 아니라 대기 시간에 민감한 짧은 요청을 지능적으로 선점하거나 더 오래 실행되는 쿼리에 인터리빙합니다. 이러한 기능은 큐 기반 스케줄링과 각 요청에 대한 키-값 캐시를 가상화하는 새로운 접근 방식인 PagedAttention을 조합하여 구현됩니다. 실제로 EngineCore는 효율적인 GPU 메모리 사용을 개선하는 동시에 컴퓨팅 단계 간 유휴 시간을 단축합니다.
EngineCoreClient는 사용자 대상 서비스와 상호 작용하기 위해 API(HTTP, gRPC 등)와 상호 작용하고 요청을 EngineCore에 릴레이하는 어댑터 역할을 합니다. 다중 EngineCoreClient는 하나 이상의 EngineCore와 통신하여 분산형 배포 또는 멀티노드 배포를 용이하게 합니다. vLLM은 낮은 수준의 추론 작업에서 요청 처리를 명확하게 분리하므로 여러 EngineCore 전반에 부하를 분산하거나 사용자 요구에 맞게 클라이언트 수를 확장하는 등 유연한 인프라 전략을 펼칠 수 있습니다.
이러한 분리를 통해 다양한 서빙 인터페이스와 유연하게 통합할 수 있을 뿐만 아니라 분산 및 확장 가능한 배포가 가능합니다. EngineCoreClient는 별도의 프로세스에서 실행할 수 있으며, 네트워크를 통해 하나 이상의 EngineCore와 통신함으로써 부하를 분산하고 CPU 오버헤드를 줄일 수 있습니다.
Red Hat AI Inference Server 실행
RHEL에서 실행
$ podman run --rm -it --device nvidia.com/gpu=all -p 8000:8000 \
--ipc=host \
--env "HUGGING_FACE_HUB_TOKEN=$HF_TOKEN" \
--env "HF_HUB_OFFLINE=0" -v ~/.cache/vllm:/home/vllm/.cache \
--name=vllm \
registry.access.redhat.com/rhaiis/rh-vllm-cuda \
vllm serve \
--tensor-parallel-size 8 \
--max-model-len 32768 \
--enforce-eager --model RedHatAI/Llama-4-Scout-17B-16E-Instruct-FP8-dynamicOpenShift에서 실행
AI Inference Server에 대한 OpenShift 배포 사양의 예:

AI Inference Server 컨테이너 로그:
결론
Red Hat AI Inference Server는 최첨단 성능과 필요한 배포 유연성을 결합합니다. 컨테이너화된 특성으로 인해 진정한 하이브리드 클라우드 유연성을 제공하므로 데이터와 애플리케이션이 상주하는 모든 위치에 최첨단 AI 추론을 일관되게 배포하여 엔터프라이즈 AI 워크로드를 위한 강력한 기반을 제공할 수 있습니다.
Red Hat AI Inference Server 웹페이지 및 가이드 데모에서 자세한 내용을 확인하거나 기술 도큐멘테이션에서 세부 구성을 확인해 보세요.
Product
Red Hat AI Inference Server
저자 소개

Erwan Gallen is Senior Principal Product Manager, Generative AI, at Red Hat, where he follows Red Hat AI Inference Server product and manages hardware-accelerator enablement across OpenShift, RHEL AI, and OpenShift AI. His remit covers strategy, roadmap, and lifecycle management for GPUs, NPUs, and emerging silicon, ensuring customers can run state-of-the-art generative workloads seamlessly in hybrid clouds.
Before joining Red Hat, Erwan was CTO and Director of Engineering at a media firm, guiding distributed teams that built and operated 100 % open-source platforms serving more than 60 million monthly visitors. The experience sharpened his skills in hyperscale infrastructure, real-time content delivery, and data-driven decision-making.
Since moving to Red Hat he has launched foundational accelerator plugins, expanded the company’s AI partner ecosystem, and advised Fortune 500 global enterprises on production AI adoption. An active voice in the community, he speaks regularly at NVIDIA GTC, Red Hat Summit, OpenShift Commons, CERN, and the Open Infra Summit.

Carlos Condado is a Senior Product Marketing Manager for Red Hat AI. He helps organizations navigate the path from AI experimentation to enterprise-scale deployment by guiding the adoption of MLOps practices and integration of AI models into existing hybrid cloud infrastructures. As part of the Red Hat AI team, he works across engineering, product, and go-to-market functions to help shape strategy, messaging, and customer enablement around Red Hat’s open, flexible, and consistent AI portfolio.
With a diverse background spanning data analytics, integration, cybersecurity, and AI, Carlos brings a cross-functional perspective to emerging technologies. He is passionate about technological innovations and helping enterprises unlock the value of their data and gain a competitive advantage through scalable, production-ready AI solutions.

유사한 검색 결과
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래