El ritmo de innovación de la inteligencia artificial generativa exige soluciones potentes, flexibles y eficientes para implementar modelos de lenguaje de gran tamaño (LLM). Hoy presentamos Red Hat AI Inference Server. Es un elemento esencial de la plataforma Red Hat AI y se incluye en Red Hat OpenShift AI y Red Hat Enterprise Linux AI (RHEL AI). También está disponible como producto independiente, diseñado para ofrecer funciones optimizadas de inferencia de LLM con portabilidad legítima en todos los entornos de nube híbrida.
En cualquier entorno de implementación, AI Inference Server ofrece a los usuarios una distribución reforzada y con soporte de vLLM junto con herramientas inteligentes de compresión de LLM y un repositorio de modelos optimizado en Hugging Face. Todo esto está respaldado por el soporte empresarial de Red Hat y la flexibilidad de implementación de terceros de acuerdo con la política de soporte de terceros de Red Hat.
Aceleración de la inferencia con un núcleo de vLLM y un paralelismo avanzado
El mecanismo de inferencia vLLM es un elemento fundamental de AI Inference Server. Es conocido por su alto rendimiento y por el uso eficiente de la memoria, que se logra a través de técnicas innovadoras como PagedAttention (optimización de la gestión de la memoria de la unidad de procesamiento de gráficos, que se originó a partir de una investigación en la Universidad de California, Berkeley) y el procesamiento por lotes permanente, que a menudo alcanza un rendimiento superior en comparación con los métodos de puesta a disposición tradicionales. Además, el servidor suele exponer un extremo de la interfaz de programación de aplicaciones (API) compatible con OpenAI, lo que simplifica la integración.
vLLM ofrece optimizaciones de inferencia sólidas para gestionar los modelos de inteligencia artificial generativa de gran tamaño actuales en diversos sistemas de hardware:
- Paralelismo de tensores (TP): divide las capas de los modelos individuales en varias unidades de procesamiento de gráficos (GPU), generalmente dentro de un nodo, lo que reduce la latencia y aumenta el rendimiento informático de esa capa.
- Paralelismo de canales (PP): organiza grupos secuenciales de capas de modelos en diferentes GPU o nodos. Esto es esencial para ajustar los modelos que son demasiado grandes, incluso para un solo nodo de varias GPU.
- Paralelismo de expertos (EP) para modelos de mezcla de expertos (MoE): vLLM incluye optimizaciones especializadas para encargarse de las arquitecturas de modelos de MoE con eficiencia, gestionando sus necesidades únicas de informática y de enrutamiento.
- Paralelismo de datos (DP): vLLM admite la atención paralela de datos que enruta solicitudes individuales a diferentes motores. En las capas de MoE, los motores de datos paralelos se unen, con lo cual los expertos se dividen en todos los nodos de trabajo de datos paralelos y tensores paralelos. Esto es particularmente importante en modelos como DeepSeek V3 o Qwen3 que tienen una pequeña cantidad de cabezas de atención de clave-valor (KV), donde el paralelismo de tensores genera una duplicación innecesaria de memoria caché de KV. En este caso, el paralelismo de datos permite que vLLM se extienda a una mayor cantidad de GPU.
- Cuantificación: LLM Compressor es un elemento de AI Inference Server que proporciona una biblioteca unificada que permite crear modelos comprimidos con cuantificación de peso y de activación o cuantificación de solo peso para una inferencia más rápida con vLLM. Este motor tiene kernels personalizados, como Marlin y Machete, para optimizar el rendimiento con la cuantificación.
- Decodificación especulativa: mejora la latencia de la inferencia con un modelo de borrador más pequeño y rápido para generar varios tokens futuros, que luego el modelo principal más grande valida y corrige en menos pasos. Este enfoque reduce la latencia general de decodificación y aumenta el rendimiento sin comprometer la calidad del resultado.
Es importante tener en cuenta que estas técnicas a menudo se pueden combinar para ajustar de manera efectiva los modelos más grandes en topologías de hardware complejas, por ejemplo, usando el paralelismo de canales en los nodos y el paralelismo de tensores dentro de cada nodo.
Portabilidad de las implementaciones mediante la organización en contenedores
AI Inference Server se ofrece como una imagen de contenedor estándar y proporciona una flexibilidad de implementación incomparable. Este formato en contenedores es importante para la portabilidad de la nube híbrida, siempre que el mismo entorno de inferencia se ejecute de manera uniforme, ya sea a través de Red Hat OpenShift, Red Hat Enterprise Linux (RHEL), plataformas de Kubernetes que no sean de Red Hat u otros sistemas Linux estándares. Ofrece una base estandarizada y predecible para poner los LLM a disposición en cualquier entorno que requiera la empresa, lo que simplifica las operaciones en infraestructuras diversas.
Compatibilidad para varios aceleradores
Uno de los principios de diseño centrales de AI Inference Server es el buen funcionamiento con varios aceleradores. Esta función permite que la plataforma aproveche sin problemas una amplia gama de aceleradores de hardware, como NVIDIA, las GPU de AMD y las TPU de Google. Al proporcionar una capa de servicio de inferencia unificada que elimina las complejidades del hardware fundamental, AI Inference Server ofrece importantes oportunidades de optimización y flexibilidad.
Esta compatibilidad con varios aceleradores brinda a los usuarios:
- Optimización del rendimiento y los costos: implementa las cargas de trabajo de inferencia en el acelerador más adecuado según las características específicas del modelo, los requisitos de latencia y las consideraciones económicas. Los diferentes aceleradores se destacan en diferentes áreas, y la capacidad de elegir el hardware correcto para el trabajo mejora el rendimiento y el uso de los recursos.
- Implementaciones preparadas para el futuro: a medida que van surgiendo tecnologías de aceleración nuevas y más eficientes, la arquitectura de AI Inference Server permite su integración sin necesidad de realizar cambios significativos en la infraestructura de servicio de inferencia ni en el código de la aplicación. Esto proporciona viabilidad y capacidad de adaptación a largo plazo.
- Ajuste de la capacidad de inferencia: ajusta fácilmente la capacidad de inferencia agregando más aceleradores del mismo tipo o de otras clases para gestionar las diversas exigencias de las cargas de trabajo. Esto proporciona la agilidad necesaria para gestionar el tráfico fluctuante de usuarios y las complejidades en constante cambio del modelo de inteligencia artificial.
- Elección del acelerador: al admitir una variedad de proveedores de aceleradores con la misma interfaz de software, la plataforma reduce la dependencia a un solo proveedor de hardware, lo que ofrece un mayor control sobre la adquisición de estos sistemas y la gestión de costos.
- Gestión sencilla de la infraestructura: AI Inference Server proporciona una interfaz de gestión uniforme para los diferentes tipos de aceleradores, lo que simplifica la sobrecarga operativa asociada con la implementación y la supervisión de los servicios de inferencia en diferentes sistemas de hardware.
Optimización de los modelos con la experiencia de Neural Magic dentro de Red Hat
La implementación eficiente de los LLM más grandes a menudo requiere optimización. AI Inference Server integra funciones potentes de compresión de estos modelos y aprovecha la experiencia pionera en optimización que aporta Neural Magic y que ahora forma parte de Red Hat. El compresor integrado utiliza técnicas de cuantificación y dispersión líderes en el sector, como SparseGPT, para reducir drásticamente el tamaño del modelo y las necesidades informáticas sin disminuir significativamente la precisión. Esto posibilita inferencias más rápidas y un mejor uso de los recursos, lo que reduce el espacio de la memoria de modo considerable y permite que los modelos se ejecuten con efectividad incluso en sistemas con memoria de GPU limitada.
Acceso mejorado con un repositorio de modelos optimizado
Para simplificar aún más la implementación, AI Inference Server incluye acceso a un repositorio seleccionado de los LLM conocidos (como los de Llama, Mistral y Granite), convenientemente alojados en la página de Red Hat AI en Hugging Face.
No son tan solo modelos estándares, sino que se optimizaron específicamente para una ejecución de alto rendimiento en el motor vLLM usando técnicas de compresión integradas. Esto significa que obtienes modelos eficientes y listos para la implementación, lo que reduce drásticamente el tiempo y el esfuerzo necesarios para poner en producción las aplicaciones de inteligencia artificial y genera valor más rápido.
Descripción general técnica de Red Hat AI Inference Server
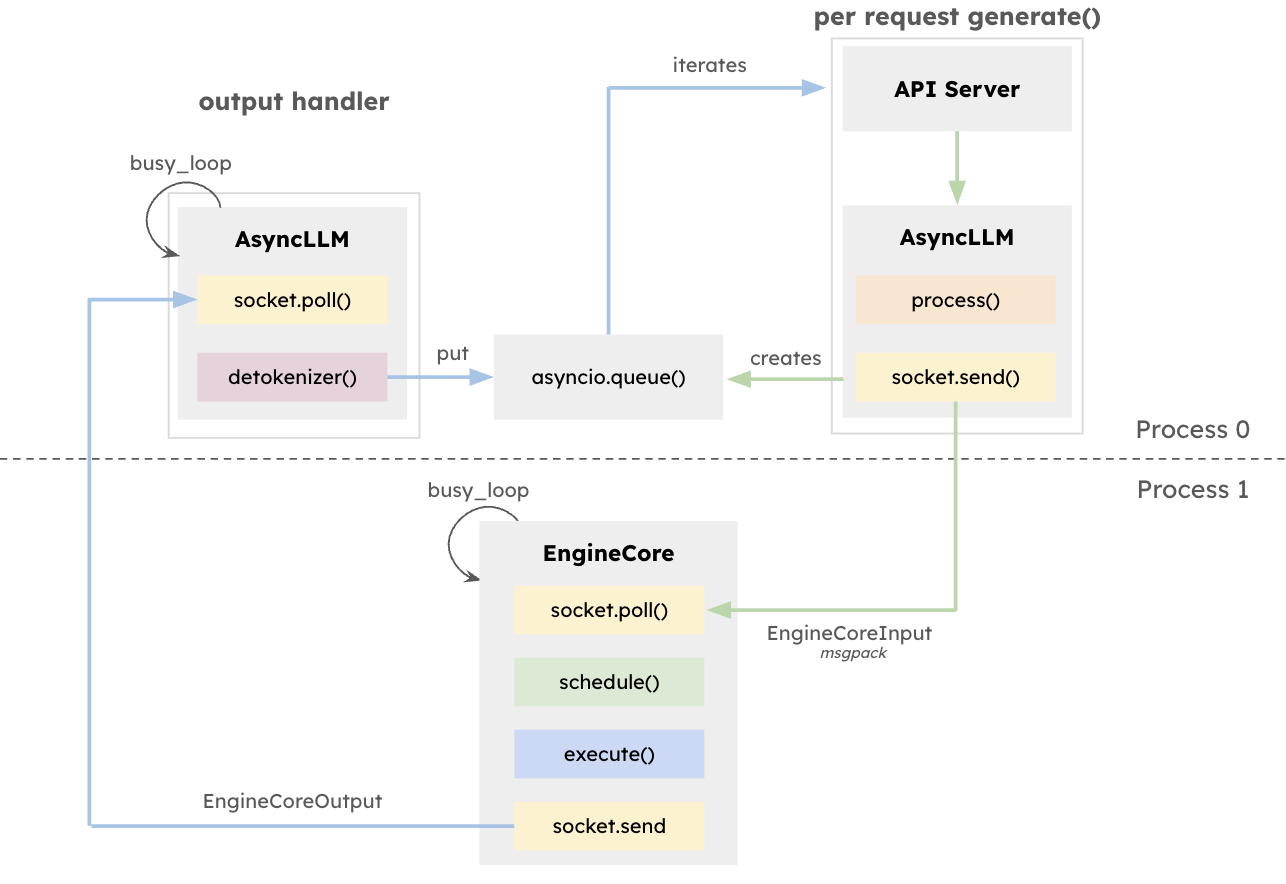
La arquitectura de vLLM busca aumentar al máximo el rendimiento y minimizar la latencia de la inferencia de los LLM, en particular en sistemas que gestionan alta simultaneidad con solicitudes de distintas duraciones. En el centro de este diseño se encuentra EngineCore, un motor de inferencia exclusivo que coordina los cálculos directos, administra la memoria caché de las KV y agrupa dinámicamente los tokens provenientes de varias solicitudes simultáneas.
EngineCore no solo reduce la sobrecarga de administrar ventanas de contexto largas, sino que también adelanta o intercala de manera inteligente las solicitudes cortas que responden con rapidez con consultas de ejecución más largas. Esto se logra al combinar la programación en colas y PagedAttention, un enfoque novedoso que virtualiza la memoria caché de clave-valor para cada solicitud. De hecho, EngineCore mejora el uso eficiente de la memoria de la GPU y reduce el tiempo de inactividad entre los pasos de cálculo.
Para interactuar con los servicios orientados al usuario, EngineCoreClient funciona como un adaptador que interactúa con las API (HTTP, gRPC, etc.) y vuelve a transmitir las solicitudes a EngineCore. Varios EngineCoreClient pueden comunicarse con uno o más motores de EngineCore, lo que facilita las implementaciones distribuidas o de varios nodos. Al separar claramente la gestión de las solicitudes de las operaciones de inferencia de bajo nivel, vLLM permite que se creen estrategias de infraestructura flexibles, como el equilibrio de carga en varios motores de EngineCore o el ajuste de la cantidad de clientes para satisfacer la demanda de los usuarios.
Esta separación no solo permite una integración flexible con varias interfaces de servicio, sino que también posibilita una implementación distribuida y flexible. Los EngineCoreClient pueden ejecutarse en procesos separados, comunicándose con uno o más motores de EngineCore a través de la red para equilibrar la carga y disminuir la sobrecarga de la CPU.
Ejecución de Red Hat AI Inference Server
Ejecución en RHEL
$ podman run --rm -it --device nvidia.com/gpu=all -p 8000:8000 \
--ipc=host \
--env "HUGGING_FACE_HUB_TOKEN=$HF_TOKEN" \
--env "HF_HUB_OFFLINE=0" -v ~/.cache/vllm:/home/vllm/.cache \
--name=vllm \
registry.access.redhat.com/rhaiis/rh-vllm-cuda \
vllm serve \
--tensor-parallel-size 8 \
--max-model-len 32768 \
--enforce-eager --model RedHatAI/Llama-4-Scout-17B-16E-Instruct-FP8-dynamicEjecución en OpenShift
Ejemplo de una especificación de implementación de OpenShift para AI Inference Server:

Registro del contenedor de AI Inference Server:
Conclusión
Red Hat AI Inference Server combina el rendimiento de vanguardia con la flexibilidad de implementación que necesitas. Su diseño en contenedores brinda una flexibilidad legítima de nube híbrida, lo que permite implementar la inferencia innovadora de la inteligencia artificial de manera uniforme dondequiera que residan tus datos y aplicaciones. Esto ofrece una base potente para las cargas de trabajo de inteligencia artificial de tu empresa.
Explora la página web de Red Hat AI Inference Server y nuestra demostración guiada para obtener más información o consulta nuestra documentación técnica para conocer las configuraciones detalladas.
Product
Red Hat AI Inference Server
Sobre los autores

Erwan Gallen is Senior Principal Product Manager, Generative AI, at Red Hat, where he follows Red Hat AI Inference Server product and manages hardware-accelerator enablement across OpenShift, RHEL AI, and OpenShift AI. His remit covers strategy, roadmap, and lifecycle management for GPUs, NPUs, and emerging silicon, ensuring customers can run state-of-the-art generative workloads seamlessly in hybrid clouds.
Before joining Red Hat, Erwan was CTO and Director of Engineering at a media firm, guiding distributed teams that built and operated 100 % open-source platforms serving more than 60 million monthly visitors. The experience sharpened his skills in hyperscale infrastructure, real-time content delivery, and data-driven decision-making.
Since moving to Red Hat he has launched foundational accelerator plugins, expanded the company’s AI partner ecosystem, and advised Fortune 500 global enterprises on production AI adoption. An active voice in the community, he speaks regularly at NVIDIA GTC, Red Hat Summit, OpenShift Commons, CERN, and the Open Infra Summit.

Carlos Condado is a Senior Product Marketing Manager for Red Hat AI. He helps organizations navigate the path from AI experimentation to enterprise-scale deployment by guiding the adoption of MLOps practices and integration of AI models into existing hybrid cloud infrastructures. As part of the Red Hat AI team, he works across engineering, product, and go-to-market functions to help shape strategy, messaging, and customer enablement around Red Hat’s open, flexible, and consistent AI portfolio.
With a diverse background spanning data analytics, integration, cybersecurity, and AI, Carlos brings a cross-functional perspective to emerging technologies. He is passionate about technological innovations and helping enterprises unlock the value of their data and gain a competitive advantage through scalable, production-ready AI solutions.

Más similar
Navegar por canal

Automatización
Las últimas novedades en la automatización de la TI para los equipos, la tecnología y los entornos

Inteligencia artificial
Descubra las actualizaciones en las plataformas que permiten a los clientes ejecutar cargas de trabajo de inteligecia artificial en cualquier lugar

Nube híbrida abierta
Vea como construimos un futuro flexible con la nube híbrida

Seguridad
Vea las últimas novedades sobre cómo reducimos los riesgos en entornos y tecnologías

Edge computing
Conozca las actualizaciones en las plataformas que simplifican las operaciones en el edge

Infraestructura
Vea las últimas novedades sobre la plataforma Linux empresarial líder en el mundo

Aplicaciones
Conozca nuestras soluciones para abordar los desafíos más complejos de las aplicaciones
Virtualización
El futuro de la virtualización empresarial para tus cargas de trabajo locales o en la nube