Intel recently launched the Intel® Xeon® 6 processors with Performance-Cores (P-Cores) [9], code-named Granite Rapids. This part of the Intel Xeon 6 processor family offers high-end, enterprise-focused processors targeted at a diverse range of workloads. It really shines when you can leverage the bandwidth and parallelism of the CPU! To explore how Intel’s new chips measure up, we’ve worked with Intel and others to run benchmarks with the latest Red Hat Enterprise Linux 10 [6.12.0-55.7.1]. Intel® Xeon® 6 processors are supported starting from RHEL 9.4 as well.
Compared to the 5th Gen Intel Xeon Scalable processors family, it now supports up to 128 cores per socket vs 64 cores, can handle DDR5-6400 memory speeds over DDR5-5600 prior generation, larger L2 cache per core, and up to 24 GT/s UPI 2.0 speeds. Faster MRDIMMs are available with speeds up to 8800 MT/s.
In past blogs, we analyzed performance of Red Hat Enterprise Linux running on previous generations of Intel® Xeon®:
- Red Hat Enterprise Linux achieves significant performance gains with Intel's 4th Generation Xeon Scalable Processors
- Red Hat Enterprise Linux Performance Results on 5th Gen Intel® Xeon® Scalable Processors
The Red Hat Performance Engineering team configured top-end systems (with RDIMM DDR memory) using the last few generations Intel Xeon processors for these benchmarks to conduct performance measurements:
- An Intel Xeon CPU Max Series platform, codenamed Sapphire Rapids HBM (SPR-HBM) - which offers exceptionally fast bandwidth due to its 64GB of high-bandwidth memory (HBM) in cache mode. We also employed a 4th Gen Intel Xeon Scalable platform with 4-sockets launched around the same time. [3] [4]
- A 5th Gen Intel Xeon Scalable platform, codenamed Emerald Rapids (EMR) [2]
- An Intel Xeon 6 processor with Performance-Cores (P-Cores) [1] [9], code-named Granite Rapids (GNR-AP) - represents the latest generation. Note: A reference design system from Intel was used here because it was available most immediately.
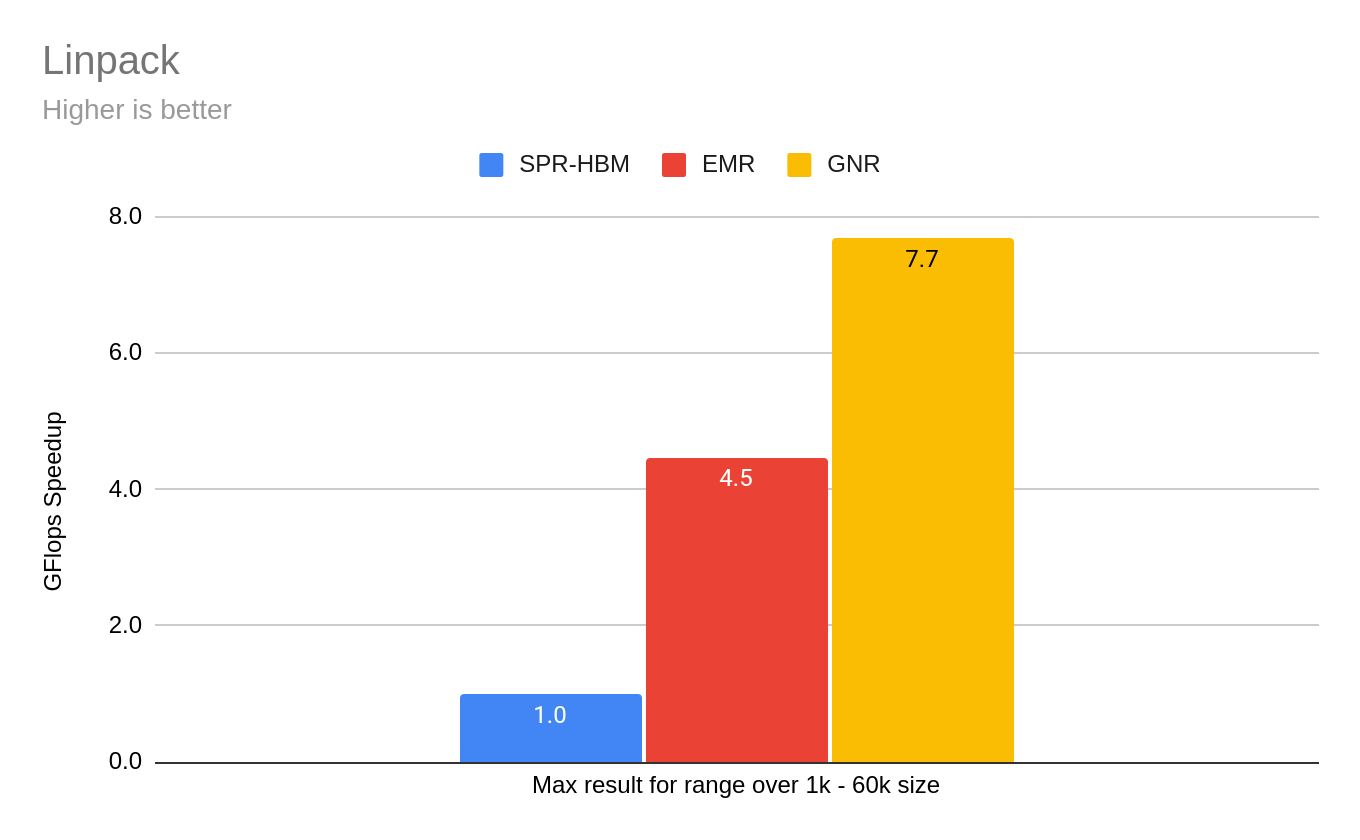
Estimated Linpack
HPC workloads show gains from Granite Rapids in CPU and memory bandwidth workloads.
Using Intel kit https://downloadmirror.intel.com/837792/l_onemklbench_p_2025.0.0_777.tgz
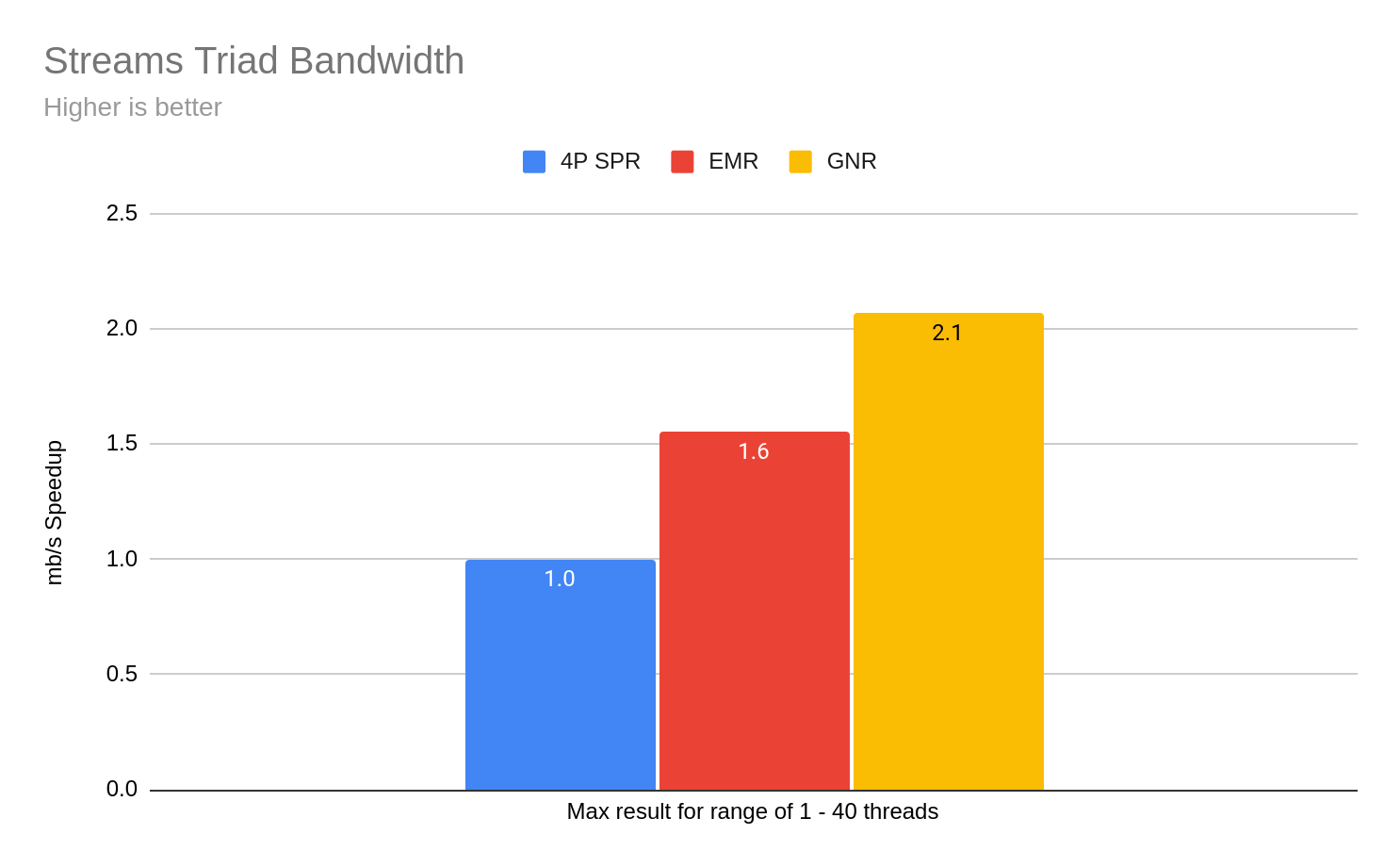
Estimated Streams Triad Bandwidth
Using https://www.cs.virginia.edu/stream/FTP/Code/stream.c
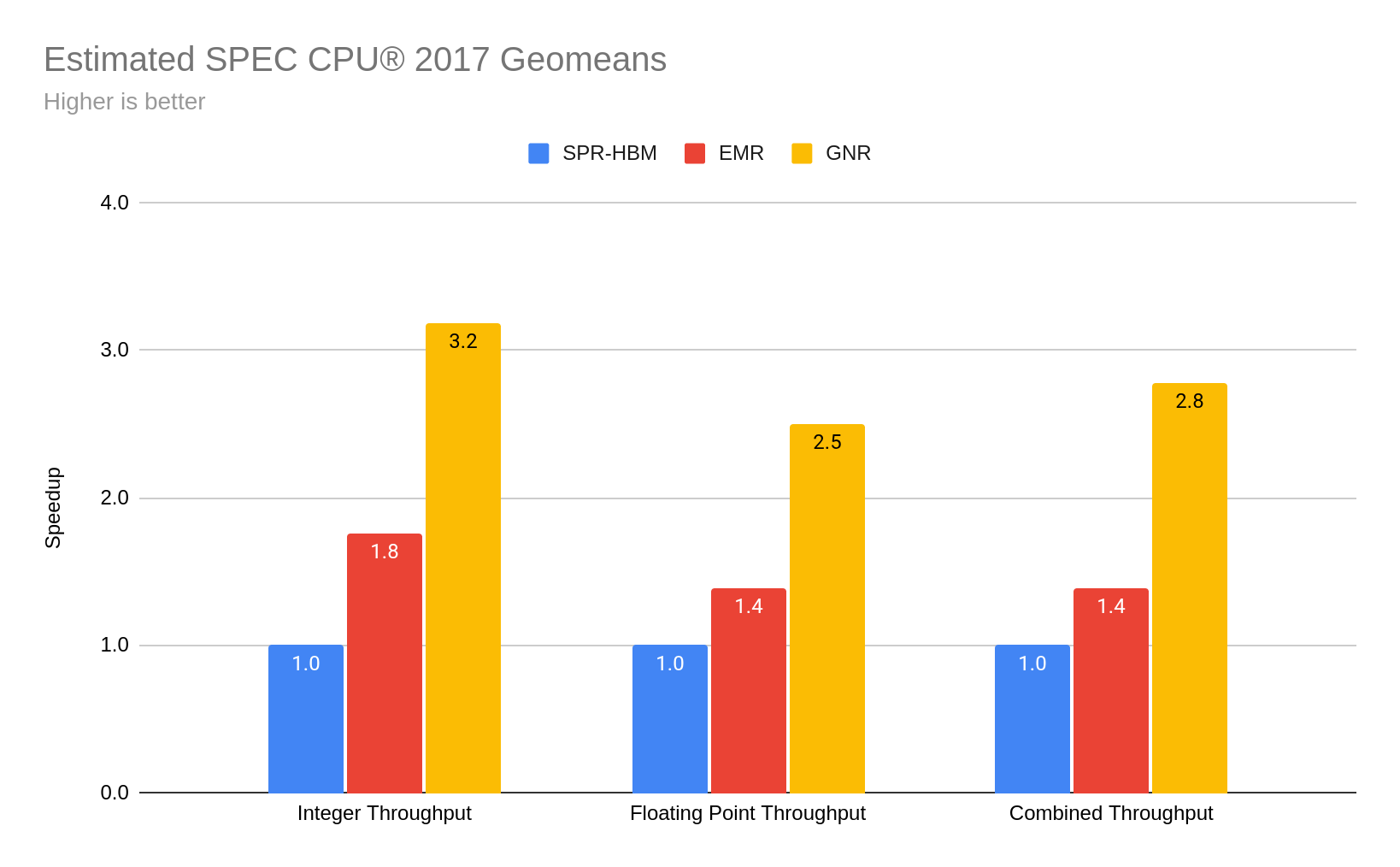
Estimated SPEC CPU® 2017
Because of the gains shown for HPC workloads, we see the nice speedups using RHEL10 kernel builds built with ISAv3 compared to older kernels built with ISAv2. Here we show estimated SPEC CPU® results gathered from Intel’s SPEC CPU® 2017 binary kit with config "ic2024.0.2-lin-sapphirerapids-rate-20231213.cfg". This was run on an Intel Xeon CPU Max Series processor (SPR-HBM), a 5th Gen Intel Xeon processor (EMR), and an Intel Xeon 6 processor (GNR), all running a pre-release version of RHEL 10. Speedup factors are shown for geomeans of the integer benchmarks, the floating point benchmarks and overall metric that includes both.
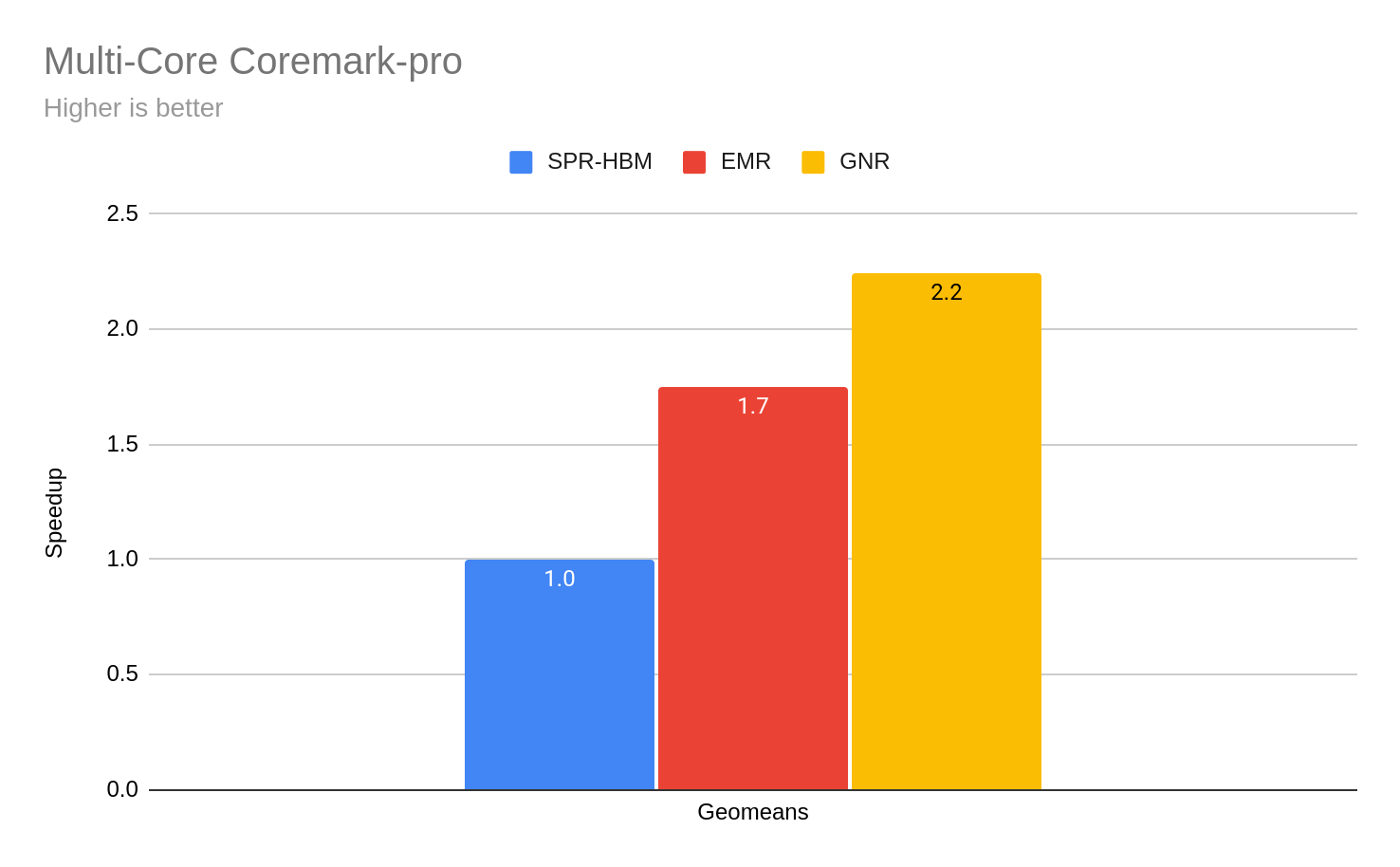
Estimated Coremark®-pro
Gain for other industry standard workloads gains of 2.2x based on the Multi-Core Coremark results.
Using https://github.com/eembc/coremark-pro
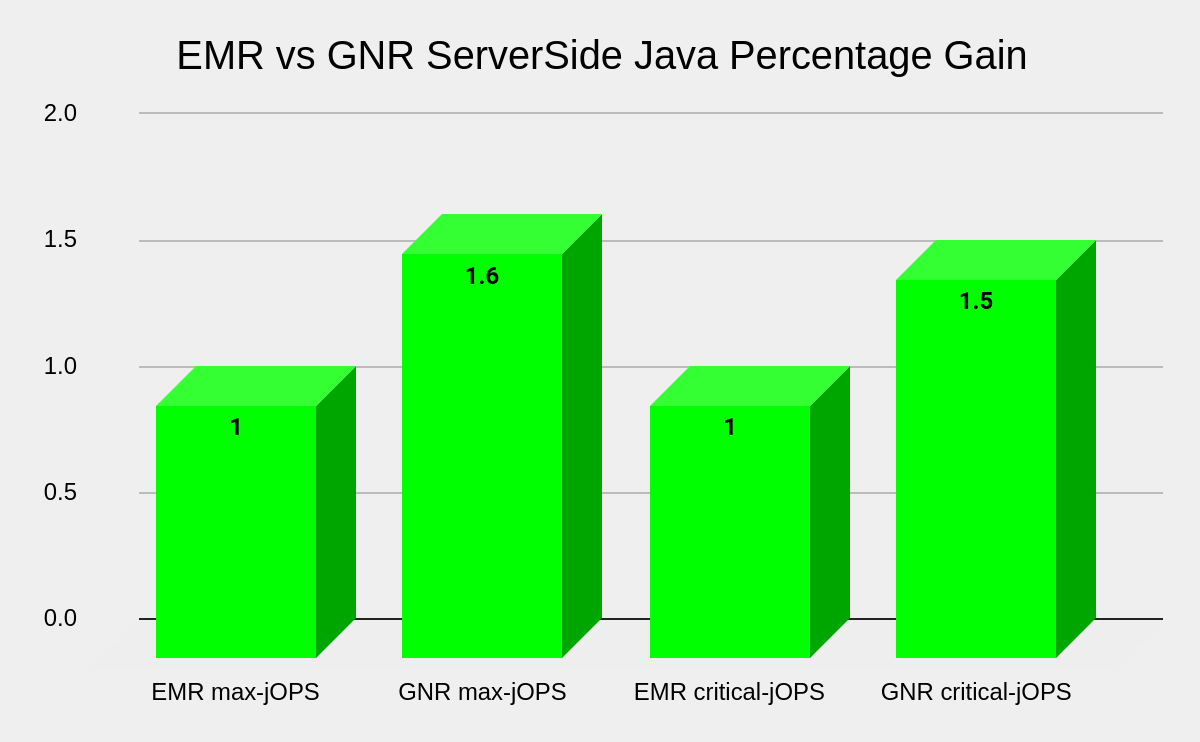
Server Side java throughput and Server Side java throughput under SLA
Here we explore the Intel Xeon 6 processor [1] by comparing performance to the previous 5th Gen Intel Xeon processor[2] using two throughput-based metrics: maximum throughput and throughput under service level agreement (SLA).
Optimal tuning was achieved by configuring Intel’s Sub-NUMA Clustering (SNC) BIOS setting to implement 3 NUMA nodes/socket for a total of 6 NUMA nodes on Intel’s Xeon 6972P processor (GNR). This allowed optimal NUMA node java pairing using numactl in Red Hat Enterprise Linux to fully approach peak performance compared to 4 NUMA nodes on the 5th Gen Intel Xeon platform
The tuning details can be found in the [5], [6], [7], and [8] footnotes below.
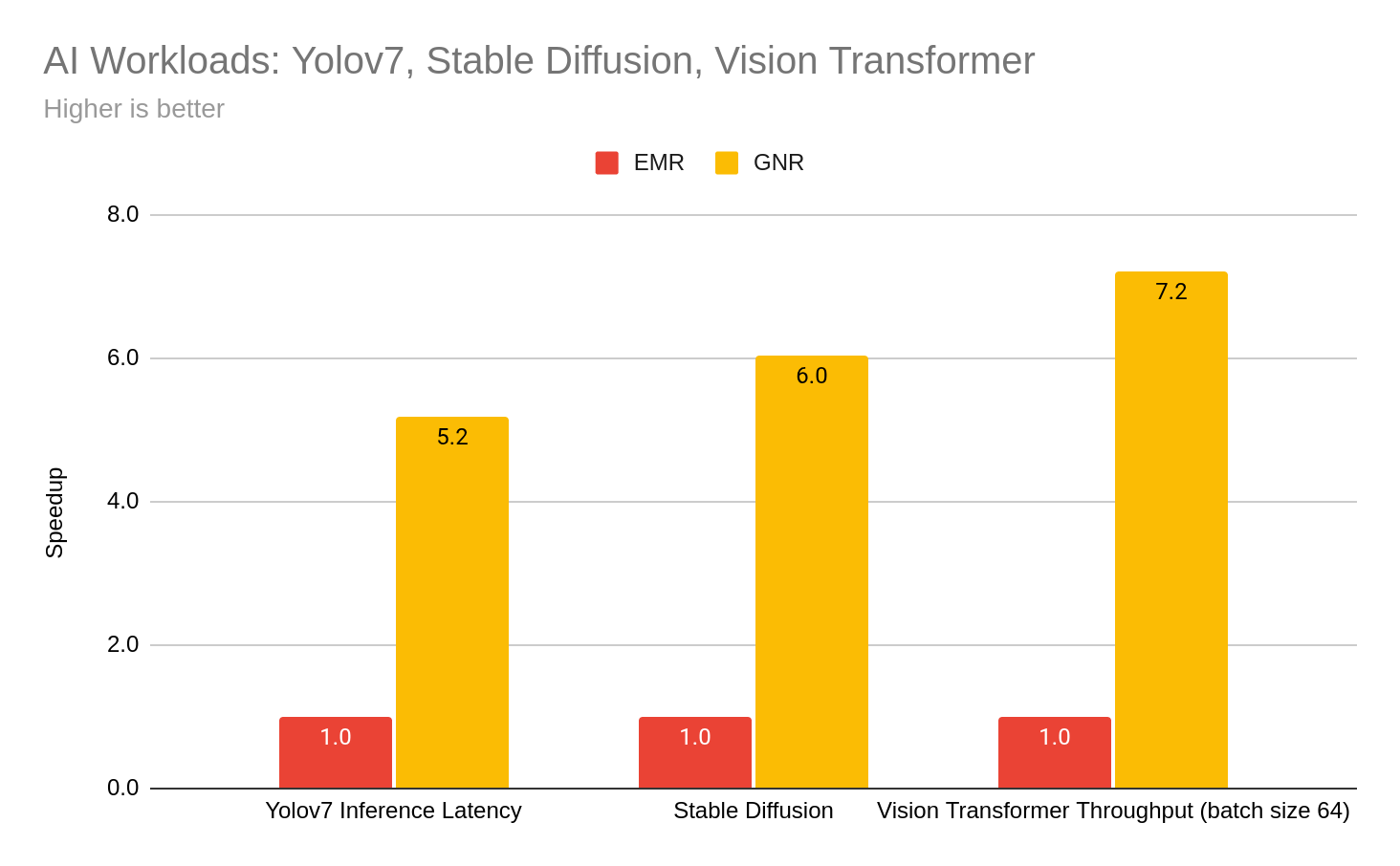
AI Workloads
Performance in AI/ML is another area of improvement easily measured on RHEL10 from models shared by Intel for CPU inference. Here we show speedups in Yolov7, Stable Diffusion, and Vision Transformer highlighting the fp16 datatype in Intel Advanced Matrix Extensions (Intel® AMX) [10] on the Intel Xeon 6 processor (GNR).
Using models from the Intel https://github.com/intel/ai-reference-models/tree/main/models_v2/pytorch
repository in the inference/cpu directories for Yolov7, Stable Diffusion and Vision Transformer (vit).
Summary
The Red Hat Performance Engineering team works with Intel to ensure performance capabilities of Red Hat Enterprise Linux on systems prior to hardware vendors shipping them in production. This blog reviewed a number of capabilities of Intel Xeon 6 platform [1] of features including higher CPU count, faster DDR5 memory, larger CPU caches. All of these features and more are supported with RHEL on Intel Xeon 6 platforms including the new RHEL 10 and from RHEL 9.4 onward!
Intel and Red Hat explored x86-64-v3 for Red Hat Enterprise Linux 10 which lifts the baseline to leverage modern CPU microarchitectures. The collaboration between Intel and Red Hat helps expand our capabilities and we will continue delivering innovative features in future versions of RHEL, where we hope to continue being the trusted OS for customers and partners.
Footnotes
Intel, the Intel logo and Xeon are trademarks of Intel Corporation or its subsidiaries.
[1] Intel® Xeon® 6 platform Hardware Configuration
Processor: 2 x Intel® Xeon® 6972P Processor,2.40 GHz (192 Cores / 384 Threads)
Motherboard: Intel AvenueCity/AvenueCity, (BIOS BHSDCRB1.IPC.0035.D44.2408292336 08/29/2024)
Memory: 1536 GB @ 6400 MT/s
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 52 bits physical, 57 bits virtual
Byte Order: Little Endian
CPU(s): 384
On-line CPU(s) list: 0-383
Vendor ID: GenuineIntel
BIOS Vendor ID: Intel(R) Corporation
Model name: Intel(R) Xeon(R) 6972P
BIOS Model name: Intel(R) Xeon(R) 6972P CPU @ 2.4GHz
BIOS CPU family: 179
CPU family: 6
Model: 173
Thread(s) per core: 2
Core(s) per socket: 96
Socket(s): 2
Stepping: 1
CPU(s) scaling MHz: 23%
CPU max MHz: 3900.0000
CPU min MHz: 800.0000
BogoMIPS: 4800.00
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr
sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts
rep_good nopl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor
ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt
tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3
cat_l2 cdp_l3 intel_ppin cdp_l2 ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow flexpriority
ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm rdt_a avx512f avx512dq
rdseed adx smap avx512ifma clflushopt clwb intel_pt avx512cd sha_ni avx512bw avx512vl xsaveopt
xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local split_lock_detect
user_shstk avx_vnni avx512_bf16 wbnoinvd dtherm ida arat pln pts hwp hwp_act_window hwp_epp
hwp_pkg_req hfi vnmi avx512vbmi umip pku ospke waitpkg avx512_vbmi2 gfni vaes vpclmulqdq
avx512_vnni avx512_bitalg avx512_vpopcntdq la57 rdpid bus_lock_detect cldemote movdiri movdir64b
enqcmd fsrm md_clear serialize tsxldtrk pconfig arch_lbr ibt amx_bf16 avx512_fp16 amx_tile
amx_int8 flush_l1d arch_capabilities
Virtualization features:
Virtualization: VT-x
Caches (sum of all):
L1d: 9 MiB (192 instances)
L1i: 12 MiB (192 instances)
L2: 384 MiB (192 instances)
L3: 960 MiB (2 instances)
NUMA:
NUMA node(s): 6
Vulnerabilities:
Gather data sampling: Not affected
Itlb multihit: Not affected
L1tf: Not affected
Mds: Not affected
Meltdown: Not affected
Mmio stale data: Not affected
Reg file data sampling: Not affected
Retbleed: Not affected
Spec rstack overflow: Not affected
Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Spectre v2: Mitigation; Enhanced / Automatic IBRS; IBPB conditional; RSB filling; PBRSB-eIBRS Not affected;
BHI BHI_DIS_S
Srbds: Not affected
Tsx async abort: Not affected[2] 5th Gen Intel® Xeon® platform Hardware Configuration
Processor: 2 x Intel® Xeon® Platinum 8592+ @ 3.90GHz (128 Cores / 256 Threads)
Motherboard: Dell Inc. PowerEdge R760/05H0JD, (BIOS 2.4.4 09/27/2024)
Memory: 1008 GB @ 5800 MT/s
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 57 bits virtual
Byte Order: Little Endian
CPU(s): 256
On-line CPU(s) list: 0-255
Vendor ID: GenuineIntel
BIOS Vendor ID: Intel
Model name: INTEL(R) XEON(R) PLATINUM 8592+
BIOS Model name: INTEL(R) XEON(R) PLATINUM 8592+ CPU @ 1.9GHz
BIOS CPU family: 179
CPU family: 6
Model: 207
Thread(s) per core: 2
Core(s) per socket: 64
Socket(s): 2
Stepping: 2
CPU(s) scaling MHz: 100%
CPU max MHz: 3900.0000
CPU min MHz: 800.0000
BogoMIPS: 3800.00
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr
sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts
rep_good nopl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64
monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe
popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb
cat_l3 cat_l2 cdp_l3 cdp_l2 ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm rdt_a avx512f avx512dq
rdseed adx smap avx512ifma clflushopt clwb intel_pt avx512cd sha_ni avx512bw avx512vl xsaveopt
xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local split_lock_detect
user_shstk avx_vnni avx512_bf16 wbnoinvd dtherm ida arat pln pts vnmi avx512vbmi umip pku ospke
waitpkg avx512_vbmi2 gfni vaes vpclmulqdq avx512_vnni avx512_bitalg avx512_vpopcntdq la57 rdpid
bus_lock_detect cldemote movdirimovdir64b enqcmd fsrm md_clear serialize tsxldtrk pconfig
arch_lbr ibt amx_bf16 avx512_fp16 amx_tile amx_int8 flush_l1d arch_capabilities
Virtualization features:
Virtualization: VT-x
Caches (sum of all):
L1d: 6 MiB (128 instances)
L1i: 4 MiB (128 instances)
L2: 256 MiB (128 instances)
L3: 640 MiB (2 instances)
NUMA:
NUMA node(s): 4
Vulnerabilities:
Gather data sampling: Not affected
Itlb multihit: Not affected
L1tf: Not affected
Mds: Not affected
Meltdown: Not affected
Mmio stale data: Not affected
Reg file data sampling: Not affected
Retbleed: Not affected
Spec rstack overflow: Not affected
Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Spectre v2: Mitigation; Enhanced / Automatic IBRS; IBPB conditional; RSB filling; PBRSB-eIBRS SW sequence; BHI BHI_DIS_S
Srbds: Not affected
Tsx async abort: Not affected[3] Intel® Xeon® CPU Max Series platform Hardware Configuration
Processor: 2 x Intel® Xeon® CPU Max 9462 @ 3.50GHz (64 Cores / 128 Threads)
Motherboard: Dell Inc. PowerEdge R760, (BIOS 2.4.4 09/27/2024)
Memory: 1TB @ 4800 MT/s
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 57 bits virtual
Byte Order: Little Endian
CPU(s): 128
On-line CPU(s) list: 0-127
Vendor ID: GenuineIntel
BIOS Vendor ID: Intel
Model name: Intel(R) Xeon(R) CPU Max 9462
BIOS Model name: Intel(R) Xeon(R) CPU Max 9462 CPU @ 2.7GHz
BIOS CPU family: 179
CPU family: 6
Model: 143
Thread(s) per core: 2
Core(s) per socket: 32
Socket(s): 2
Stepping: 8
CPU(s) scaling MHz: 98%
CPU max MHz: 3500.0000
CPU min MHz: 800.0000
BogoMIPS: 5400.00
Flags:
fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht
tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc
cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm
pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch
cpuid_fault epb cat_l3 cat_l2 cdp_l3 cdp_l2 ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow flexpriority ept
vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm rdt_a avx512f avx512dq rdseed adx smap
avx512ifma clflushopt clwb intel_pt avx512cd sha_ni avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc
cqm_occup_llc cqm_mbm_total cqm_mbm_local split_lock_detect avx_vnni avx512_bf16 wbnoinvd dtherm ida arat pln pts
vnmi avx512vbmi umip pku ospke waitpkg avx512_vbmi2 gfni vaes vpclmulqdq avx512_vnni avx512_bitalg tme
avx512_vpopcntdq la57 rdpid bus_lock_detect cldemote movdiri movdir64b enqcmd fsrm md_clear serialize tsxldtrk
pconfig arch_lbr ibt amx_bf16 avx512_fp16 amx_tile amx_int8 flush_l1d arch_capabilities
Virtualization features:
Virtualization: VT-x
Caches (sum of all):
L1d: 3 MiB (64 instances)
L1i: 2 MiB (64 instances)
L2: 128 MiB (64 instances)
L3: 150 MiB (2 instances)
NUMA:
NUMA node(s): 2
Vulnerabilities:
Gather data sampling: Not affected
Itlb multihit: Not affected
L1tf: Not affected
Mds: Not affected
Meltdown: Not affected
Mmio stale data: Not affected
Reg file data sampling: Not affected
Retbleed: Not affected
Spec rstack overflow: Not affected
Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Spectre v2: Mitigation; Enhanced / Automatic IBRS; IBPB conditional; RSB filling; PBRSB-eIBRS SW sequence; BHI BHI_DIS_S
Srbds: Not affected
Tsx async abort: Not affected[4] 4th Gen Intel® Xeon® Scalable platform 4-socket Hardware Configuration
Processor: 4 x Intel® Xeon® Platinum 8490H @ 3.50GHz (240 Cores / 480 Threads)
Motherboard: Dell Inc. PowerEdge R960, (BIOS 2.4.4 09/27/2024)
Memory: 2TB @ 4800 MT/s
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 57 bits virtual
Byte Order: Little Endian
CPU(s): 240
On-line CPU(s) list: 0-239
Vendor ID: GenuineIntel
BIOS Vendor ID: Intel
Model name: Intel(R) Xeon(R) Platinum 8490H
BIOS Model name: Intel(R) Xeon(R) Platinum 8490H CPU @ 1.9GHz
BIOS CPU family: 179
CPU family: 6
Model: 143
Thread(s) per core: 1
Core(s) per socket: 60
Socket(s): 4
Stepping: 8
CPU(s) scaling MHz: 99%
CPU max MHz: 3500.0000
CPU min MHz: 800.0000
BogoMIPS: 3800.00
Flags:
fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht
tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc
cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm
pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch
cpuid_fault epb cat_l3 cat_l2 cdp_l3 cdp_l2 ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow flexpriority ept
vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm rdt_a avx512f avx512dq rdseed adx smap
avx512ifma clflushopt clwb intel_pt avx512cd sha_ni avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc
cqm_occup_llc cqm_mbm_total cqm_mbm_local split_lock_detect user_shstk avx_vnni avx512_bf16 wbnoinvd dtherm ida
arat pln pts vnmi avx512vbmi umip pku ospke waitpkg avx512_vbmi2 gfni vaes vpclmulqdq avx512_vnni avx512_bitalg
avx512_vpopcntdq la57 rdpid bus_lock_detect cldemote movdiri movdir64b enqcmd fsrm md_clear serialize tsxldtrk
pconfig arch_lbr ibt amx_bf16 avx512_fp16 amx_tile amx_int8 flush_l1d arch_capabilities
Virtualization features:
Virtualization: VT-x
Caches (sum of all):
L1d: 11.3 MiB (240 instances)
L1i: 7.5 MiB (240 instances)
L2: 480 MiB (240 instances)
L3: 450 MiB (4 instances)
NUMA:
NUMA node(s): 4
Vulnerabilities:
Gather data sampling: Not affected
Itlb multihit: Not affected
L1tf: Not affected
Mds: Not affected
Meltdown: Not affected
Mmio stale data: Not affected
Reg file data sampling: Not affected
Retbleed: Not affected
Spec rstack overflow: Not affected
Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Spectre v2: Mitigation; Enhanced / Automatic IBRS; IBPB conditional; RSB filling; PBRSB-eIBRS SW sequence; BHI BHI_DIS_S
Srbds: Not affected
Tsx async abort: Not affected
[5] 5th Gen Intel® Xeon® Scalable platform SPECjbb®2015 tuning for ServerSide Java Throughput
specjbb.controller.type = HBIR_RT
specjbb.group.count=8
specjbb.forkjoin.workers.Tier1=310
specjbb.forkjoin.workers.Tier2=7
specjbb.forkjoin.workers.Tier3=32
specjbb.comm.connect.client.pool.size=232
specjbb.customerDriver.threads=75
specjbb.customerDriver.threads.probe=69
specjbb.customerDriver.threads.saturate=85
specjbb.mapreducer.pool.size=223
specjbb.comm.connect.selector.runner.count=1
specjbb.comm.connect.worker.pool.max=81
specjbb.comm.connect.worker.pool.min=24
specjbb.comm.connect.timeouts.connect=600000
specjbb.comm.connect.timeouts.read=600000
specjbb.comm.connect.timeouts.write=600000
cpupower -c all frequency-set -g performance
echo "performance" | tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor
echo always > /sys/kernel/mm/transparent_hugepage/defrag
echo always > /sys/kernel/mm/transparent_hugepage/enabled
echo 300 > /sys/kernel/mm/hugepages/hugepages-1048576kB/nr_hugepages
echo 8000 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages
systemctl stop systemd-update-utmp-runlevel.service
echo 10000 > /proc/sys/kernel/sched_cfs_bandwidth_slice_us
echo 1000 > /sys/kernel/debug/sched/migration_cost_ns
echo 16000000 > /sys/kernel/debug/sched/base_slice_ns
echo 100 > /proc/sys/kernel/sched_rr_timeslice_ms
echo 1000000 > /proc/sys/kernel/sched_rt_period_us
echo 990000 > /proc/sys/kernel/sched_rt_runtime_us
echo 0 > /proc/sys/kernel/sched_schedstats
echo 1 > /sys/kernel/debug/sched/tunable_scaling
echo 3000 > /proc/sys/vm/dirty_expire_centisecs
echo 500 > /proc/sys/vm/dirty_writeback_centisecs
echo 40 > /proc/sys/vm/dirty_ratio
echo 10 > /proc/sys/vm/dirty_background_ratio
echo 10 > /proc/sys/vm/swappiness
echo 0 > /proc/sys/kernel/numa_balancing
ulimit -n 1024000
ulimit -v 800000000
ulimit -m 800000000
ulimit -l 800000000
echo 274877906944 > /proc/sys/kernel/shmmax
echo 274877906944 > /proc/sys/kernel/shmall
# Number of Groups (TxInjectors mapped to Backend) to expect
GROUP_COUNT=8
# Number of TxInjector JVMs to expect in each Group
TI_JVM_COUNT=1
# Benchmark options for Controller / TxInjector JVM / Backend
SPEC_OPTS_C="-Dspecjbb.group.count=$GROUP_COUNT -Dspecjbb.txi.pergroup.count=$TI_JVM_COUNT "
SPEC_OPTS_TI=""
SPEC_OPTS_BE=""
Each TxInjector and Backend is pinned to a numa node with "numactl -N $node -m $node"
# Java options for Controller / TxInjector / Backend JVM
JAVA_OPTS_C=" -server -Xms2g -Xmx2g -Xmn1536m -XX:+UseLargePages -XX:LargePageSizeInBytes=1G -XX:+UseParallelGC
-XX:ParallelGCThreads=2"
JAVA_OPTS_TI=" -server -Xms2g -Xmx2g -Xmn1536m -XX:+UseLargePages -XX:LargePageSizeInBytes=1G -XX:+UseParallelGC
-XX:ParallelGCThreads=2 "
JAVA_OPTS_BE=" -XX:+UseParallelGC -XX:+UseLargePages -XX:+AlwaysPreTouch -XX:-UseAdaptiveSizePolicy
-XX:MaxTenuringThreshold=15 -XX:InlineSmallCode=10k -verbose:gc -XX:-UseCountedLoopSafepoints
-XX:LoopUnrollLimit=20 -server -XX:TargetSurvivorRatio=95 -XX:SurvivorRatio=28 -XX:LargePageSizeInBytes=1G
-XX:MaxGCPauseMillis=500 -XX:AdaptiveSizeMajorGCDecayTimeScale=12 -XX:AdaptiveSizeDecrementScaleFactor=2
-XX:AllocatePrefetchLines=3 -XX:AllocateInstancePrefetchLines=2 -XX:AllocatePrefetchStepSize=128
-XX:AllocatePrefetchDistance=384 -Xms29g -Xmx29g -Xmn27g -XX:ParallelGCThreads=32 -XX:+UseHugeTLBFS"
[6] 5th Gen Intel® Xeon® platform SPECjbb®2015 tuning for ServerSide Java throughput under SLA
specjbb.controller.type=HBIR_RT
specjbb.forkjoin.workers.Tier1=124
specjbb.forkjoin.workers.Tier2=1
specjbb.forkjoin.workers.Tier3=8
specjbb.mapreducer.pool.size=64
specjbb.comm.connect.selector.runner.count=16
specjbb.comm.connect.worker.pool.max=256
specjbb.group.count=4
specjbb.comm.connect.client.pool.size=232
specjbb.customerDriver.threads=75
specjbb.customerDriver.threads.probe=69
specjbb.customerDriver.threads.saturate=85
specjbb.comm.connect.worker.pool.min=1
specjbb.comm.connect.timeouts.connect=600000
specjbb.comm.connect.timeouts.read=600000
specjbb.comm.connect.timeouts.write=600000
for file in `ls /sys/devices/system/node/node*/hugepages/hugepages-1048576kB/nr_hugepages`
do
echo 238 > $file
done
cpupower -c all frequency-set -g performance
systemctl stop systemd-update-utmp-runlevel.service
echo always > /sys/kernel/mm/transparent_hugepage/defrag
echo always > /sys/kernel/mm/transparent_hugepage/enabled
echo 56000000 > /sys/kernel/debug/sched/latency_ns
echo 180000 > /sys/kernel/debug/sched/base_slice_ns
echo 750 > /sys/kernel/debug/sched/migration_cost_ns
echo 12 > /sys/kernel/debug/sched/nr_migrate
ulimit -n 1024000
ulimit -v 800000000
ulimit -m 800000000
ulimit -l 800000000
# Number of Groups (TxInjectors mapped to Backend) to expect
GROUP_COUNT=4
# Number of TxInjector JVMs to expect in each Group
TI_JVM_COUNT=1
# Benchmark options for Controller / TxInjector JVM / Backend
SPEC_OPTS_C="-Dspecjbb.group.count=$GROUP_COUNT -Dspecjbb.txi.pergroup.count=$TI_JVM_COUNT "
SPEC_OPTS_TI=""
SPEC_OPTS_BE=""
Each TxInjector and Backend is pinned to a numa node with "numactl -N $node -m $node"
# Java options for Controller / TxInjector / Backend JVM
JAVA_OPTS_C=" -server -Xms2g -Xmx2g -Xmn1536m -XX:+UseLargePages -XX:LargePageSizeInBytes=1G -XX:+UseParallelGC
-XX:ParallelGCThreads=2 "
JAVA_OPTS_TI=" -server -Xms2g -Xmx2g -Xmn1536m -XX:+UseLargePages -XX:LargePageSizeInBytes=1G -XX:+UseParallelGC
-XX:ParallelGCThreads=2"
JAVA_OPTS_BE=" -server -Xms235G -Xmx235G -Xmn232G -XX:+UseLargePages -XX:LargePageSizeInBytes=1G -XX:+UseParallelGC
-XX:ParallelGCThreads=64 -XX:+AlwaysPreTouch -XX:-UseAdaptiveSizePolicy -XX:MaxTenuringThreshold=15
-XX:TargetSurvivorRatio=95 -XX:-UsePerfData -Xnoclassgc -XX:SurvivorRatio=64 -XX:InitialCodeCacheSize=25m
-XX:InlineSmallCode=10k"
[7] Intel® Xeon® 6 platform SPECjbb®2015 tuning for ServerSide Java Throughput
specjbb.group.count=12
specjbb.forkjoin.workers.Tier1=256
specjbb.forkjoin.workers.Tier2=12
specjbb.forkjoin.workers.Tier3=28
specjbb.controller.type = HBIR_RT
specjbb.comm.connect.client.pool.size=232
specjbb.customerDriver.threads=75
specjbb.customerDriver.threads.probe=69
specjbb.customerDriver.threads.saturate=85
specjbb.mapreducer.pool.size=223
specjbb.comm.connect.selector.runner.count=1
specjbb.comm.connect.worker.pool.max=81
specjbb.comm.connect.worker.pool.min=24
specjbb.comm.connect.timeouts.connect=600000
specjbb.comm.connect.timeouts.read=600000
specjbb.comm.connect.timeouts.write=600000
cpupower -c all frequency-set -g performance
systemctl stop systemd-update-utmp-runlevel.service
echo performance | tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor
echo always > /sys/kernel/mm/transparent_hugepage/defrag
echo always > /sys/kernel/mm/transparent_hugepage/enabled
echo 40000 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages
echo 600 > /sys/kernel/mm/hugepages/hugepages-1048576kB/nr_hugepages
echo 10000 > /proc/sys/kernel/sched_cfs_bandwidth_slice_us
echo 1000 > /sys/kernel/debug/sched/migration_cost_ns
echo 28000000 > /sys/kernel/debug/sched/base_slice_ns
echo 100 > /proc/sys/kernel/sched_rr_timeslice_ms
echo 1000000 > /proc/sys/kernel/sched_rt_period_us
echo 990000 > /proc/sys/kernel/sched_rt_runtime_us
echo 0 > /proc/sys/kernel/sched_schedstats
echo 1 > /sys/kernel/debug/sched/tunable_scaling
echo 3000 > /proc/sys/vm/dirty_expire_centisecs
echo 500 > /proc/sys/vm/dirty_writeback_centisecs
echo 40 > /proc/sys/vm/dirty_ratio
echo 10 > /proc/sys/vm/dirty_background_ratio
echo 10 > /proc/sys/vm/swappiness
echo 0 > /proc/sys/kernel/numa_balancing
echo 0 > /proc/sys/kernel/sched_autogroup_enabled
ulimit -n 1024000
ulimit -v 800000000
ulimit -m 800000000
ulimit -l 800000000
echo 274877906944 > /proc/sys/kernel/shmmax
echo 274877906944 > /proc/sys/kernel/shmall
# Number of Groups (TxInjectors mapped to Backend) to expect
GROUP_COUNT=12
# Number of TxInjector JVMs to expect in each Group
TI_JVM_COUNT=1
# Benchmark options for Controller / TxInjector JVM / Backend
SPEC_OPTS_C="-Dspecjbb.group.count=$GROUP_COUNT -Dspecjbb.txi.pergroup.count=$TI_JVM_COUNT "
SPEC_OPTS_TI=""
SPEC_OPTS_BE=""
Each TxInjector and Backend is pinned to a numa node with "numactl -N $node -m $node"
# Java options for Controller / TxInjector / Backend JVM
JAVA_OPTS_C=" -server -Xms2g -Xmx2g -Xmn1536m -XX:+UseLargePages -XX:LargePageSizeInBytes=1G -XX:+UseParallelGC
-XX:ParallelGCThreads=2 "
JAVA_OPTS_TI=" -server -Xms2g -Xmx2g -Xmn1536m -XX:+UseLargePages -XX:LargePageSizeInBytes=1G -XX:+UseParallelGC
-XX:ParallelGCThreads=2"
JAVA_OPTS_BE=" -XX:+UseParallelGC -XX:+UseLargePages -XX:+AlwaysPreTouch -XX:-UseAdaptiveSizePolicy -XX:MaxTenuringThreshold=15
-XX:InlineSmallCode=10k -verbose:gc -XX:-UseCountedLoopSafepoints -XX:LoopUnrollLimit=20 -server
-XX:TargetSurvivorRatio=95 -XX:SurvivorRatio=28 -XX:LargePageSizeInBytes=1G -XX:MaxGCPauseMillis=500
-XX:AdaptiveSizeMajorGCDecayTimeScale=12 -XX:AdaptiveSizeDecrementScaleFactor=2 -XX:AllocatePrefetchLines=3
-XX:AllocateInstancePrefetchLines=2 -XX:AllocatePrefetchStepSize=128 -XX:AllocatePrefetchDistance=384 -Xms31744m
-Xmx31744m -Xmn29696m -XX:UseAVX=0 -XX:ParallelGCThreads=32 -XX:+UseHugeTLBFS -Xlog:pagesize=trace"
[8] Intel® Xeon® 6 platform SPECjbb®2015 tuning for ServerSide Java throughput under SLA
specjbb.forkjoin.workers.Tier1=124
specjbb.forkjoin.workers.Tier2=1
specjbb.forkjoin.workers.Tier3=8
specjbb.mapreducer.pool.size=64
specjbb.comm.connect.selector.runner.count=16
specjbb.group.count=6
specjbb.controller.type=HBIR_RT
specjbb.comm.connect.client.pool.size=232
specjbb.customerDriver.threads=75
specjbb.customerDriver.threads.probe=69
specjbb.customerDriver.threads.saturate=85
specjbb.comm.connect.worker.pool.min=1
specjbb.comm.connect.worker.pool.max=384
specjbb.comm.connect.timeouts.connect=600000
specjbb.comm.connect.timeouts.read=600000
specjbb.comm.connect.timeouts.write=600000
for file in `ls /sys/devices/system/node/node*/hugepages/hugepages-1048576kB/nr_hugepages`
do
echo 240 > $file
done
cpupower -c all frequency-set -g performance
systemctl stop systemd-update-utmp-runlevel.service
echo always > /sys/kernel/mm/transparent_hugepage/defrag
echo always > /sys/kernel/mm/transparent_hugepage/enabled
echo 180000 > /sys/kernel/debug/sched/base_slice_ns
echo 750 > /sys/kernel/debug/sched/migration_cost_ns
echo 12 > /sys/kernel/debug/sched/nr_migrate
ulimit -n 1024000
ulimit -v 800000000
ulimit -m 800000000
ulimit -l 800000000
# Number of Groups (TxInjectors mapped to Backend) to expect
GROUP_COUNT=6
# Number of TxInjector JVMs to expect in each Group
TI_JVM_COUNT=1
# Benchmark options for Controller / TxInjector JVM / Backend
SPEC_OPTS_C="-Dspecjbb.group.count=$GROUP_COUNT -Dspecjbb.txi.pergroup.count=$TI_JVM_COUNT "
SPEC_OPTS_TI=""
SPEC_OPTS_BE=""
Each TxInjector and Backend is pinned to a numa node with "numactl -N $node -m $node"
# Java options for Controller / TxInjector / Backend JVM
JAVA_OPTS_C=" -server -Xms2g -Xmx2g -Xmn1536m -XX:+UseLargePages -XX:LargePageSizeInBytes=1g -XX:+UseParallelGC
-XX:ParallelGCThreads=2"
JAVA_OPTS_TI=" -server -Xms2g -Xmx2g -Xmn1536m -XX:+UseLargePages -XX:LargePageSizeInBytes=1g -XX:+UseParallelGC
-XX:ParallelGCThreads=2"
JAVA_OPTS_BE=" -server -Xms235G -Xmx235G -Xmn232G -XX:+UseLargePages -XX:LargePageSizeInBytes=1g -XX:+UseParallelGC
-XX:ParallelGCThreads=64 -XX:+AlwaysPreTouch -XX:-UseAdaptiveSizePolicy -XX:MaxTenuringThreshold=15
-XX:TargetSurvivorRatio=95 -XX:-UsePerfData -Xnoclassgc -XX:SurvivorRatio=64 -XX:InitialCodeCacheSize=25m
-XX:InlineSmallCode=10k"[9] Intel® Xeon® 6 Processors with Performance-Cores (P-Cores):
https://www.intel.com/content/www/us/en/products/details/processors/xeon/xeon6-p-cores.html
[10] Intel® Advanced Matrix Extensions (Intel® AMX):
Sobre os autores

Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações
Virtualização
O futuro da virtualização empresarial para suas cargas de trabalho on-premise ou na nuvem