Eine der wichtigsten Komponenten einer containerbasierten Architektur ist die Sicherheit.
Dieser Bereich hat viele Facetten (werfen Sie hier einen Blick in die Themenliste in der offiziellen OpenShift-Dokumentation), aber zwei der grundlegendsten Anforderungen sind Authentifizierung und Autorisierung. In diesem Artikel erläutere ich, wie Authentifizierung und Autorisierung in Kubernetes und Red Hat OpenShift funktionieren. Ich beschreibe die Interaktionen zwischen den verschiedenen Schichten eines Kubernetes-Ökosystems, darunter die Infrastrukturschicht, die Kubernetes-Schicht und die Schicht der containerisierten Anwendungen.
Was ist Authentifizierung und Autorisierung?
Einfach ausgedrückt ist Authentifizierung in einem Computersystem eine Antwort auf die Frage „Wer sind Sie?“. Die Autorisierung lautet hingegen „Jetzt, da ich weiß, dass Sie es sind: Was dürfen Sie tun?“
Meiner Erfahrung nach bestehen die Schwierigkeiten beim Verständnis dieses Themas in Kubernetes vor allem wegen der Anzahl der miteinander interagierenden Komponenten (Nutzende, APIs, Container, Pods). Bei der Authentifizierung müssen Sie zunächst klären, welche Komponenten beteiligt sind. Authentifizieren Sie sich beim Kubernetes-Cluster? Oder sprechen Sie von einem Microservice, der versucht, auf einen anderen Microservice in der Umgebung zuzugreifen? Oder vielleicht von einer Cloud-Ressource außerhalb des Kubernetes-Clusters? Oder einem Endpunkt (eine Cloud-Ressource, ein System oder eine Person), der versucht, auf eine der auf dem Cluster ausgeführten Anwendungen zuzugreifen und diese zu verwenden?
Authentifizierung und Autorisierung mit OAuth 2.0 und OIDC
Angenommen, ein Nutzender versucht, auf einen Endpunkt zuzugreifen. Der Nutzende könnte sein:
- Eine echte Person
- Ein nicht menschliches Account (ein Anwendungs-Pod, eine Systemkomponente, eine Software-Pipeline oder eine physische oder logische Entität)
Der Endpunkt könnte sein:
- Eine API
- Software (wie eine Datenbank)
- Ein physischer oder virtueller Server

Wenn der Endpunkt eine Anforderung vom Nutzenden empfängt, muss er Folgendes verstehen:
- Wer sendet diese Anfrage (Authentifizierung)?
- Wozu ist dieser Nutzende berechtigt (Autorisierung)?
Die offizielle Kubernetes-Dokumentation enthält ein komplettes Kapitel über die Authentifizierung. Die Hauptaussage dieser Dokumentation ist, dass sich Authentifizierung in Kubernetes auf den Prozess der Authentifizierung einer API-Anforderung an den Kubernetes-API-Server bezieht. Diese Anfragen können über die Befehle kubectl oder oc in einem Terminal, einer grafischen Benutzeroberfläche (GUI) oder über API-Aufrufe gestellt werden, aber letztlich wird alles an den API-Server gesendet.
Es gibt viele Authentifizierungstechnologien und -protokolle (LDAP, SAML, Kerberos und weitere). Die erfolgreicheste und häufigste API-Authentifizierungsmethode ist jedoch die Kombination aus OAuth 2.0 und OpenID Connect (OIDC).
OAuth 2.0 ist ein Autorisierungsprotokoll (kein Authentifizierungsprotokoll), das den Zugriff auf eine Reihe von Ressourcen (wie eine Remote-API oder Benutzerdaten) gewährt. Um dies zu erreichen, verwendet OAuth 2.0 ein Zugriffstoken. Hierbei handelt es sich um Datenelemente, die die Autorisierung für den Zugriff auf eine Ressource im Namen des Endnutzenden darstellen.
OpenID Connect (OIDC) ist ein Authentifizierungsprotokoll, das das OAuth 2.0-Framework erweitert, indem es eine Identitätsschicht darüber bereitstellt. Es bietet einen Mechanismus für die Anforderung bestimmter Benutzerinformationen, wie Name oder E-Mail-Adresse, und ermöglicht Nutzenden, den Zugriff auf diese Informationen zu gewähren oder zu verweigern. Die wichtigste Erweiterung des OAuth2-Protokolls ist ein zusätzliches Feld, das mit dem Zugriffstoken zurückgegeben wird und als ID-Token bezeichnet wird. Dieses Token ist ein JSON Web Token (JWT) mit bestimmten Feldern, wie der E-Mail-Adresse eines Nutzenden, die vom Server signiert werden.
Die folgende Darstellung zeigt die Schritte, die ausgeführt werden, wenn ein Nutzender eine Reihe von Aktionen in einem Kubernetes-Cluster mit dem Befehl kubectl konfiguriert. Der gesamte Prozess ist komplexer, aber in der offiziellen Dokumentation ausführlich aufgeführt.

Bildunterschrift: Ein Flussdiagramm aus der Kubernetes-Dokumentation zum Prozess der Authentifizierung
- Melden Sie sich zunächst bei einem Identity Provider an.
- Der Identity Provider stellt Ihnen ein
access_token, id_tokenund einRefresh_tokenbereit. - Verwenden Sie für
kubectlIhrid_tokenmit dem--token-Parameter, oder fügen Sie das Token zukubeconfighinzu. -
kubectlsendet denid_tokenin einem Header mit dem Namen „Authorization“ an den API-Server. - Der API-Server überprüft, ob die JWT-Signatur gültig ist, dass das
id_tokennicht abgelaufen ist und dass der Nutzende für diese Transaktion autorisiert ist. - Der API-Server gibt eine Antwort an
kubectlzurück, das Ihnen eine Rückmeldung gibt.
Da Ihr id_token alle Daten enthält, die zur Validierung Ihrer Identität erforderlich sind, benötigt Kubernetes keine weitere Interaktion mit dem Identity Provider. Das ist eine hochgradig skalierbare Lösung für die Authentifizierung, insbesondere wenn jede Anfrage zustandslos ist.
Was ist Role-based Access Control (RBAC)?
RBAC ist eine Methode zur Regulierung des Zugriffs auf Computer- oder Netzwerkressourcen auf der Basis der Rollen einzelner Nutzender innerhalb einer Organisation. Beispielsweise könnte ein Systemadministrator auf einer Plattform berechtigt sein, Änderungen an der gesamten Umgebung vorzunehmen (die sich möglicherweise auf sämtliche Anwendungen im Cluster auswirken). Wenn Sie jedoch nur eine Anwendung im Cluster verwalten, dürfen Sie wahrscheinlich nur Änderungen an dieser Anwendung vornehmen.
Die folgende Abbildung zeigt diese beiden Beispielnutzenden. Das grüne Symbol steht für einen Nutzenden, der zum HR-Team gehört, während das schwarze Symbol einen Plattform-Administrator darstellt. Der HR-Nutzende kann nur auf die Ressourcen unter der Gruppe „HR apps“ zugreifen, aber der Plattformadministrator kann auf alles innerhalb der Plattform zugreifen.
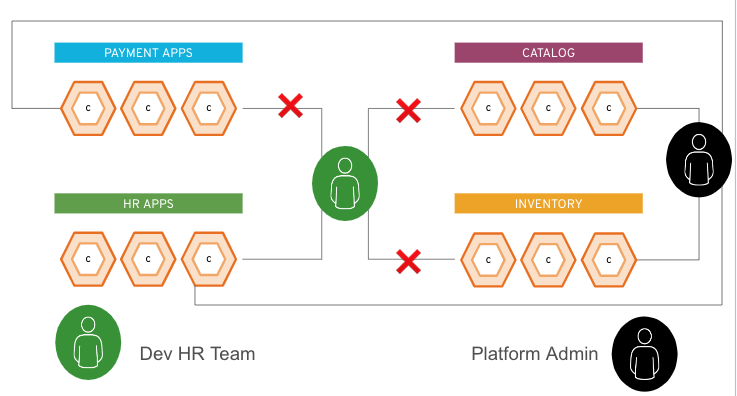
Dem HR-Nutzenden wird während des Autorisierungsschritts ein grünes Token gewährt, und dem Administrator ein schwarzes. Im Rahmen der Interaktion mit dem Endpunkt (dem Kubernetes-Cluster oder OpenShift-API) fügt jeder der Nutzenden seinen Token (grün oder schwarz) zu seinen Anforderungen hinzu. Anhand dieses Tokens erkennt der Cluster, auf welche Anwendungen die Nutzenden zugreifen können.
Transport-Layer und Endpunkte
Der gebräuchlichste Transportmechanismus zum Erreichen eines Kubernetes-Endpunkts ist Transport Layer Security (TLS), womit ein verschlüsselter Tunnel für HTTPS bereitgestellt wird.
Wenn Sie ein Systemadministrator für eine virtuelle Linux- oder Windows-Maschine sind, ist Ihre Zugriffsmethode für diese Endpunkte wahrscheinlich SSH oder RDP. Diese Protokolle verschlüsseln den Datenverkehr zwischen Ihnen (dem Nutzenden) und dem Endpunkt (dem Linux- oder Windows-Server). Auch bei APIs, Software oder SaaS (Software as a Service) von Drittanbietern ist TLS der häufigste Transportmechanismus.

Das Einrichten einer sicheren und verschlüsselten Session zwischen dem Endpunkt und dem Nutzenden wird in diesem Blog nicht behandelt. Es basiert auf Tunneln und Schlüsseln (oder Zertifikaten), die zur Authentifizierung des Endpunkts verwendet werden (entweder der Nutzende oder der Endpunkt oder beide) und die zwischen den Endpunkten gesendeten Pakete verschlüsseln und entschlüsseln.
Die Schichten des Kubernetes- und OpenShift-Zugriffs
Die drei Konzepte Authentifizierung, Autorisierung und Transport sind relativ einfach, sobald Sie sich ihrer bewusst sind. In jeder IT-Umgebung müssen jedoch mehrere Schichten berücksichtigt werden, und genau hier entsteht ein Großteil der Komplexität und Verwirrung.
Eine Kubernetes-Architektur besteht aus 3 Hauptschichten:
- Infrastrukturschicht: Datenverarbeitungs-, Storage- und Netzwerkschicht. Diese Schicht kann eine Public Cloud, ein On-Premise- oder Colocation-Rechenzentrum oder eine Kombination beidem sein.
- .Kubernetes-Schicht: Verantwortlich für das Hosting und Management sämtlicher containerisierter Anwendungen.
- .Containerisierte Anwendungen: Die Gruppe von Containern, die eine bestimmte Anwendung bilden. Bei diesen Anwendungen kann es sich um kommerzielle Standardanwendungen (COTS), Unabhängige Softwareanbieter (ISV) und intern entwickelte Anwendungen oder eine beliebige Kombination daraus handeln.
Jede Schicht bietet und erfordert sowohl Authentifizierungs- als auch Autorisierungsfunktionen.
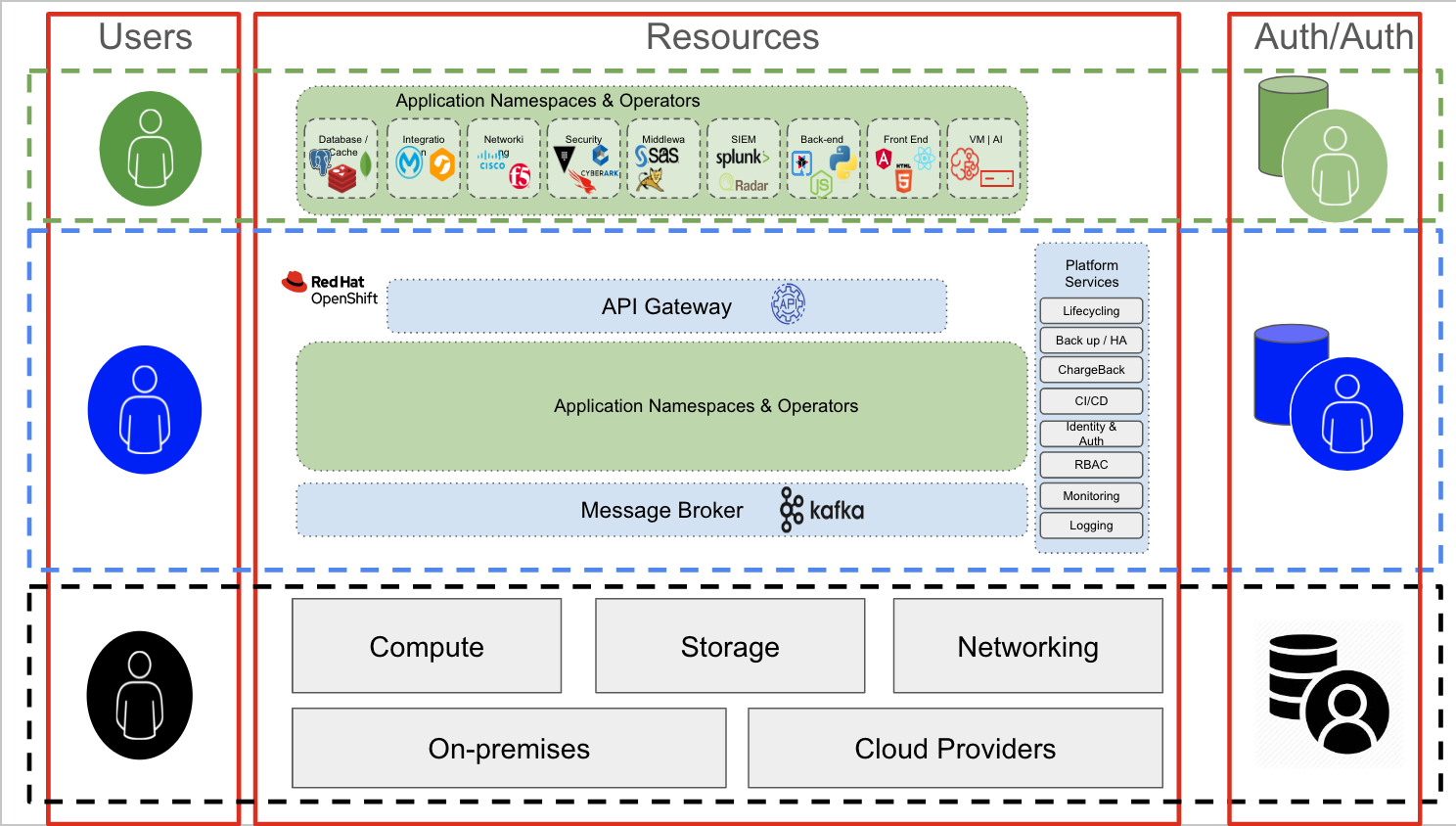
Authentifizierung und Autorisierung in der Infrastrukturschicht
Die Nutzenden der Infrastrukturschicht sind in der Regel Systemadministratoren, die Zugriff auf bestimmte Komponenten (entweder Storage, Netzwerk, Computing oder Virtualisierung) benötigen. Um auf diese Schicht (die unterste Schicht, schwarz in der obigen Abbildung) zuzugreifen, stellt ein Administrator normalerweise über SSH eine Verbindung zu einem Server her und nutzt dabei dedizierte Schnittstellen für die Storage-, Netzwerk- oder Server-Knoten (iLOs, iDRAC usw.). Der Authentifizierungsmechanismus kann eine Kombination aus RADIUS/TACACS (Netzwerk), LDAP oder Kerberos (Server und Storage) oder anderen Domain-spezifischen Authentifizierungsmechanismen sein.
Interessanterweise verwendet derselbe Infrastruktur-Administrator möglicherweise eine Anwendung (in der grünen Schicht), die auf OpenShift (der blauen Schicht) gehostet wird, um sie bei der Durchführung ihrer Aktivitäten zu unterstützen.
Beispielsweise kann es sich bei dem Netzwerkverwaltungs-Stack um eine containerisierte Anwendung handeln, die auf OpenShift ausgeführt wird. In diesem Kontext ist der Admin-Nutzende jedoch funktional ein normaler (grüner) Nutzender, der versucht, auf eine Anwendung zuzugreifen (in diesem Beispiel den Netzwerkverwaltungs-Stack). Die Authentifizierungs- und Autorisierungsmechanismen auf dieser Ebene sind anders beschaffen. Beispielsweise erfolgt die Verbindung zur Anwendung wahrscheinlich über eine TLS/SSL-Verbindung und es sind möglicherweise Zugangsdaten für den Zugriff auf die Konsole des Netzwerkverwaltungs-Stacks erforderlich.
Authentifizierung und Autorisierung in OpenShift
Wenn Sie die Ebenen nach oben verschieben und die blaue Ebene anzeigen (also Interaktion mit OpenShift oder Kubernetes im Allgemeinen), bedeutet dies, dass mit dem Kubernetes-API-Server kommuniziert wird. Dies gilt sowohl für menschliche als auch für nicht menschliche Nutzende, unabhängig davon, ob sie eine GUI-Konsole oder ein Terminal verwenden. Letztendlich laufen alle Interaktionen mit OpenShift oder Kubernetes über den API-Server ab.
Die OAuth2/OIDC-Kombination ist sinnvoll für die API-Authentifizierung und -Autorisierung, daher bietet OpenShift einen integrierten OAuth2-Server. Im Rahmen der Konfiguration dieses OAuth2-Servers muss ein unterstützter Identity Provider hinzugefügt werden. Der Identity Provider unterstützt den OAuth2-Server bei der Bestätigung der Identität des Nutzenden. Nach der Konfiguration dieses Teils ist OpenShift bereit, Nutzende zu authentifizieren.
Für einen authentifizierten Nutzenden erstellt OpenShift ein Zugriffstoken und gibt dieses Token an den Nutzenden zurück. Dieses Token wird als OAuth-Zugriffstoken bezeichnet.Ein Nutzender kann diese OAuth-Zugriffstoken bei jeder Interaktion mit der OpenShift-API verwenden, bis sie abläuft oder widerrufen wird.
Nutzende und Service Accounts
Ein Nutzender kann menschlich oder nicht menschlich sein. In OpenShift gibt es konzeptionell unterschiedliche Rollen, die ein bestimmter Nutzender übernehmen kann:
- Reguläre Nutzende: Menschen, die mit einem Kubernetes-Cluster interagieren.
- Systemnutzende: Menschliche (wie ein Plattform-Administrator) und nicht menschliche Cluster-Komponenten (wie die Registry, verschiedene Control-Plane-Knoten und Anwendungsknoten).
- Andere nicht menschliche Nutzende: Dazu gehören auch Service Accounts. Sie repräsentieren in der Regel Anwendungen (innerhalb oder außerhalb des Clusters), die mit der Kubernetes-API interagieren müssen. Beispielsweise würde eine Pipeline, die GitLab, GitHub und Tekton verwendet, ein Servicekonto nutzen, um mit OpenShift zu interagieren.
Nutzende und Service Accounts können in OpenShift in Gruppen organisiert werden. Gruppen sind nützlich bei der Verwaltung von Autorisierungsrichtlinien, um mehreren Nutzenden gleichzeitig Berechtigungen zu erteilen. Beispielsweise können Sie einer Gruppe den Zugriff auf Objekte in einem Projekt erlauben, anstatt jedem Nutzenden den Zugriff einzeln zu gewähren.
Ein Nutzender kann einer oder mehreren Gruppen zugewiesen werden, wobei jede Gruppe einen bestimmten Satz von Nutzenden repräsentiert. Die meisten Organisationen verfügen bereits über Benutzergruppen (wie auf einem Active Directory-Server). Es ist möglich, LDAP-Datensätze mit internen OpenShift-Gruppeneinträgen zu synchronisieren.
Role-based Access Control (RBAC) und Autorisierung
Hat sich ein Nutzender erfolgreich authentifiziert und ein OAuth2-Zugriffstoken erhalten, wird diesem Nutzenden ein Satz an Zugriffsberechtigungen auf Basis von RBAC gewährt. Ein RBAC-Objekt bestimmt, ob ein Nutzender berechtigt ist, eine bestimmte Aktion für eine Ressource auszuführen. Eine RBAC-Definition kann cluster- oder projektweit gelten.
Die RBAC wird verwaltet über:
- Regeln: Sätze zulässiger Verben für einen Satz von Objekten. Diese werden kollektiv als CRUD bezeichnet: create, read, update, delete (erstellen, lesen, updaten, löschen). Dies sind die grundlegenden Operationen bei persistentem Storage. Im Kontext einer RESTful-API entsprechen sie POST, GET, PUT oder PATCH und DELETE des HTTP-Protokolls. Beispielsweise kann ein Nutzender oder ein Servicekonto über die Berechtigung zum Erstellen eines Pods verfügen.
- Rollen: Sammlungen von Regeln. Sie können Nutzende und Gruppen mehreren Rollen zuordnen oder sie an diese binden.
- Bindungen: Zuordnungen zwischen Nutzenden und Gruppen mit einer Rolle.
OpenShift bietet vordefinierte Rollen (cluster-admin, basic user und more). Ein Überblick über RBAC mit Regeln, Rollen und Bindungen ist in der folgenden Abbildung (Auszug aus der OpenShift-Dokumentation) enthalten.

Authentifizierung und Autorisierung von Ressourcen innerhalb der OpenShift-Schicht
Eine Ressource innerhalb der Kubernetes-Schicht (in der Regel ein Pod) benötigt möglicherweise Zugriff, um eine der folgenden Aktionen auszuführen:
- Interagieren mit der Kubernetes-API
- Interagieren mit dem Host (der Infrastrukturschicht), auf dem die Ressource gehostet wird
- Interaktion mit Ressourcen außerhalb des Clusters (wie einer Cloud-Ressource)

Interaktion mit der Kubernetes-API
Jede Interaktion mit der Kubernetes-API erfordert eine Art Authentifizierung mit OAuth. Ein Pod repräsentiert einen nicht menschlichen Nutzenden. Daher ist ein Servicekonto erforderlich, um mit dem API-Server zu interagieren.
Standardmäßig ist ein Pod mit einem Servicekonto verknüpft, und eine Zugriffsberechtigung (Token) für dieses Servicekonto wird im Dateisystem jedes Containers in diesem Pod platziert, und zwar unter /var/run/secrets/kubernetes.io/serviceaccount/token. Es wird darüber diskutiert, ob dieses Modell eine gute Idee ist oder nicht. Es ist in OpenShift konfigurierbar und kann mithilfe von Richtlinien mit Tools wie ACS durchgesetzt werden.
Interaktion mit der Host-/Kubernetes-Infrastrukturschicht
Diese Art der Interaktion basiert nicht auf Kubernetes-API-Aufrufen. Sie hängt tatsächlich mit der Verwaltung der Berechtigungen auf Prozessebene (Berechtigungen auf Linux-Ebene) des zugrunde liegenden Hosts zusammen.
Das Mapping der Aktionen (Berechtigungen), die ein Pod mit der zugrunde liegenden Infrastruktur ausführen kann, und der Ressourcen, auf die er zugreifen kann, erfolgt mithilfe von Sicherheitskontextbeschränkungen (Security Context Constraints, SCC). Eine Sicherheitskontextbeschränkung ist eine OpenShift-Ressource, die einen Pod auf eine Gruppe von Ressourcen beschränkt. Sie ähnelt der Kubernetes-Sicherheitskontextressource.
Beispielsweise kann ein Prozess möglicherweise nicht über die Berechtigung zum Erstellen einer Datei in einem bestimmten Pfad oder nicht über Schreibberechtigungen für eine vorhandene Datei verfügen (möglicherweise hat er nur Leseberechtigungen). Der Hauptzweck besteht jeweils darin, den Zugriff eines Pods auf die Host-Umgebung zu begrenzen. Sie können eine SCC verwenden, um Pod-Berechtigungen zu steuern, ähnlich wie die rollenbasierte Zugriffskontrolle zur Verwaltung von Berechtigungen der Nutzenden eingesetzt wird.
Interaktion mit externen Ressourcen
Manchmal muss ein Pod auf eine Ressource außerhalb des Clusters zugreifen. Beispielsweise ist möglicherweise der Zugriff auf einen Objektspeicher (wie einen S3 Bucket) für Daten- oder Protokolldateien erforderlich. Dazu müssen Sie wissen, wie die Ressource Nutzende authentifiziert und was Sie in den Pod integrieren müssen, der mit dieser Ressource kommuniziert.
Das Identitäts- und Zugriffsmanagement (Identity and Access Management, IAM) von Amazon für Rollen für Service Accounts (IRSA) ist ein Beispiel für ein solches Design zur Bereitstellung von Pods mit einer Reihe von Zugangsdaten für den Zugriff auf Services auf AWS. Wenn ein Pod erstellt wird, fügt ein Webhook Variablen (den Pfad zum Token für den Kubernetes-Service Account und den ARN der übernommenen Rolle) in den Pod ein, der auf den Service Account verweist. Dies wird auch als „Mutieren“ bezeichnet. Verfügt die übernommene IAM-Rolle über die erforderlichen AWS-Berechtigungen, kann der Pod die AWS-SDK-Vorgänge mithilfe temporärer STS-Zugangsdaten ausführen.

Authentifizierung und Autorisierung für containerisierte Anwendungen in OpenShift
Die letzte Schicht bilden containerisierte Anwendungen. Ähnlich wie bei der vorherigen Ebene kann jeder Container versuchen, auf Folgendes zuzugreifen:
- Kubernetes-API
- Eine weitere API, die von einem anderen Container innerhalb des Clusters oder einer Ressource außerhalb des Clusters bereitgestellt wird
- Eine Nicht-API-Verbindung, wie die Kontaktaufnahme mit einem bestimmten Port für den Datenbankzugriff

Wie die obige Abbildung zeigt, ist ein Container, der auf eine API zugreift, zu Folgendem in der Lage:
- Direktes Zugreifen auf eine andere API mit Zugangsdaten für die Authentifizierung, die mit der Anwendung verknüpft sind (wie mit Kubernetes Secrets)
- Direktes Zugreifen auf einen Nicht-API-Endpunkt mithilfe der vom Endpunkt unterstützten Authentifizierungsmechanismen
- Nutzen Sie den Pod-Service Account
Direkter API-Aufruf
Ein Container kann auf die Kubernetes-API zugreifen, indem die Umgebungsvariablen KUBERNETES_SERVICE_HOST und KUBERNETES_SERVICE_PORT_HTTPS abgerufen werden. Für nicht unter die Kubernetes-API fallenden Datenverkehr kann eine Anwendung entweder eine Client Library (wie eine AWS-API) oder eine vom Entwickler erstellte benutzerdefinierte Integration verwenden.
Nicht API-basierte Kommunikation:
Eine Anwendung muss möglicherweise eine Verbindung mit einer Datenbank herstellen, um Daten abzurufen oder zu übertragen. In solchen Fällen wird die Authentifizierung in der Regel als Teil des Codes im Container gehandhabt und kann in der Regel mithilfe von Umgebungsvariablen, Secrets, ConfigMaps usw. zur Laufzeit aktualisiert werden.
Verwendung des Service Accounts
Die empfohlene Methode zur Authentifizierung beim Kubernetes-API-Server ist die Verwendung von Zugangsdaten für ein Service Account. Die meisten Programmiersprachen verfügen über einen Satz von unterstützten Kubernetes-Client Libraries. Auf Grundlage dieser Libraries werden die Zugangsdaten für den Service Account eines Pods für die Kommunikation mit dem API-Server verwendet. OpenShift stellt automatisch einen Service Account in den Pods bereit, was den Zugriff auf das gültige Token erlaubt.
Für nicht Kubernetes-API-Aufrufe kann ein Container bei der Authentifizierung bei einem externen API-Service auch den Service Account für den Pod verwenden.
Authentifizierung und Autorisierung
Ein Computer muss wissen, wer ein Nutzender ist und was dieser Nutzende tun darf. Dies ist der Bereich der Authentifizierung und Autorisierung, und Sie wissen jetzt, wie er in Kubernetes und OpenShift verwaltet wird.
Vielen Dank an Shane Boulden und Derek Waters für die sorgfältige Prüfung und das Feedback zu diesem Artikel.
Über den Autor

Simon Delord is a Solution Architect at Red Hat. He works with enterprises on their container/Kubernetes practices and driving business value from open source technology. The majority of his time is spent on introducing OpenShift Container Platform (OCP) to teams and helping break down silos to create cultures of collaboration.Prior to Red Hat, Simon worked with many Telco carriers and vendors in Europe and APAC specializing in networking, data-centres and hybrid cloud architectures.Simon is also a regular speaker at public conferences and has co-authored multiple RFCs in the IETF and other standard bodies.
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen
Virtualisierung
Erfahren Sie das Neueste über die Virtualisierung von Workloads in Cloud- oder On-Premise-Umgebungen