하이브리드 클라우드의 AI 모델을 위한 개방형 플랫폼
지능형 애플리케이션 및 생성형 AI 수용
AI(인공지능), ML(머신 러닝), DL(딥러닝)은 다양한 비즈니스와 산업 전반에서 애플리케이션 현대화 노력에 크게 영향을 미치고 있습니다. 데이터에서 전략적 가치와 새로운 인사이트를 이끌어내고 혁신해야 한다는 필요성으로 인해 AI 지원 클라우드 네이티브 애플리케이션과 DevOps 방법론 사용이 확장되고 있습니다. 동시에 이처럼 새로운 환경은 복잡할 수 있으며 개발자부터 데이터 사이언티스트, 운영 인력까지 모두에게 영향을 미칠 수 있습니다. AI/ML을 실무에 적용하기란 간단하지 않습니다. 일반적으로 몇 달이 걸리는 반면, Gen AI(생성형 AI)는 하루가 다르게 혁신되고 있습니다. 이러한 속도 차이로 인해 프로젝트가 실패할 수 있으며, 수많은 과제 안에서 다음과 같이 비즈니스에 위험 요소가 될 수 있습니다.
- AI 발전 속도에 맞추는 것이 쉽지 않을 수 있습니다. 빠르게 진화하는 툴과 애플리케이션 서비스를 최신 상태로 일관되게 유지하고, GPU(그래픽 처리 장치)와 같은 하드웨어 리소스를 프로비저닝하고, AI 기반 애플리케이션의 규모를 확장하는 것까지 여러 어려움이 있습니다.
- 기업은 특히 민감한 데이터를 사용하여 모델과 애플리케이션을 개발할 때 AI에 투자하면서도 리스크를 줄이고 실질적인 가치를 창출해야 합니다.
- 애플리케이션 개발자와 데이터 사이언티스트를 위해 서로 다른 플랫폼을 유지 관리하는 것 역시 협업을 복잡하게 만들고 개발 속도를 저하시킬 수 있습니다.
- AI 기반 애플리케이션은 데이터가 생성되는 지점 가까이에 대규모로 배포해야 합니다.
Red Hat OpenShift AI는 Red Hat® OpenShift®를 기반으로 구축된 선도적인 하이브리드 클라우드 애플리케이션 플랫폼이자 Red Hat AI 포트폴리오의 일부로, 데이터 사이언티스트와 개발자에게 지능형 애플리케이션을 빌드하고 배포할 수 있는 강력한 AI/ML 플랫폼을 제공합니다. 기업은 하나의 공통된 플랫폼에서 원하는 툴을 실험하고, 협업하고, 시장 출시 속도를 가속화할 수 있습니다. Red Hat OpenShift AI는 데이터 사이언티스트와 개발자가 원하는 셀프 서비스 환경과 엔터프라이즈 IT 팀이 요구하는 신뢰성을 결합합니다.
신뢰할 수 있는 기반을 갖추게 되면 라이프사이클 전반에서 마찰이 줄어들게 됩니다. Red Hat OpenShift AI는 강력한 플랫폼, 널리 사용되는 인증 툴을 갖춘 광범위한 에코시스템, 그리고 모델을 프로덕션에 배포하기 위한 익숙한 워크플로우를 제공합니다. 이러한 장점 덕분에 팀은 협업 시 마찰을 줄이고 AI 기반 애플리케이션을 더욱 효율적으로 시장에 출시하여 궁극적으로 비즈니스에 더 큰 가치를 제공할 수 있습니다.
주요 내용
인프라를 확장하고 자동화하여 실험 단계에서 프로덕션 단계로 전환할 때 비용을 절감합니다.
데이터 사이언티스트, 데이터 엔지니어, 애플리케이션 개발자, DevOps 팀의 역량을 강화하는 일관된 사용자 환경으로 팀 간 AI/ML 운영 효율성을 높입니다.
온프레미스, 클라우드 또는 엣지에서 AI/ML 워크로드를 구축, 학습, 배포, 모니터링함으로써 하이브리드 클라우드의 유연성을 제공합니다.
신속한 개발, 교육, 테스트, 배포
Red Hat OpenShift AI는 유연하고 확장 가능한 AI 플랫폼으로, AI 지원 애플리케이션을 빌드, 배포, 관리할 수 있는 툴을 제공합니다. 오픈소스 기술을 사용하여 구축한 이 플랫폼은 팀이 실험하고, 모델을 서빙하고, 혁신적인 애플리케이션을 제공할 수 있도록 일관된 운영을 지원하는 신뢰할 수 있는 기능을 제공합니다. Red Hat OpenShift AI는 지능형 애플리케이션의 제공을 가속화하여 일관된 공유 플랫폼에서 초기 파일럿 단계의 ML(머신 러닝) 모델을 지능형 애플리케이션으로 더욱 빠르게 전환할 수 있도록 지원합니다.
Red Hat OpenShift AI는 예측 AI 모델과 생성형 AI 모델을 빌드하고, 학습시키고, 튜닝, 배포, 모니터링하는 툴을 갖춘 통합 UI(사용자 인터페이스) 환경을 제공합니다. 온프레미스 또는 모든 주요 퍼블릭 클라우드에 모델을 배포하여 필요한 모든 위치에서 상용 클라우드 종속성(Lock-In) 없이 워크로드를 실행하는 유연성을 확보할 수 있습니다. Red Hat OpenShift AI는 커뮤니티 Open Data Hub 프로젝트와 Jupyter, Pytorch, vLLM, Kubeflow와 같은 일반적인 오픈소스 프로젝트를 기반으로 합니다.
프로덕션 환경의 확장 비용 절감
OpenShift AI는 Red Hat OpenShift의 애드온으로, 가장 까다로운 워크로드도 처리할 수 있도록 설계된 플랫폼을 제공합니다. OpenShift AI는 데이터 파이프라인을 통해 리소스 프로비저닝을 간소화하고 많은 태스크를 자동화함으로써 실험 단계에서 프로덕션 단계로 전환하는 과정에서 생성형 AI 프로젝트와 예측 AI 프로젝트를 위한 지속적인 학습, 서빙, 인프라에 필요한 비용을 절감해 줍니다. OpenShift AI는 vLLM과 같은 최적화된 서빙 엔진과 런타임을 사용하고 워크로드 요구 사항에 따라 기반 인프라를 확장함으로써 모델 추론 비용을 절감합니다.
데이터 사이언티스트는 규범적인 툴체인으로 인한 부담에서 벗어나 익숙한 툴과 프레임워크를 사용하거나 점차 성장하는 기술 파트너 에코시스템에 액세스하여 더욱 심층적인 AI/ML 전문성을 쌓을 수 있습니다. IT 팀이 필요한 리소스를 프로비저닝할 때까지 기다리지 않아도 IT 티켓 대신 클릭 한 번으로 온디맨드 인프라를 확보할 수 있습니다.
운영 복잡성 감소
Red Hat OpenShift AI는 데이터 사이언티스트, 데이터 엔지니어, 애플리케이션 엔지니어, DevOps 팀이 협업하여 AI 솔루션을 적시에 효과적으로 제공할 수 있도록 지원하는 일관된 사용자 환경을 제공합니다. 이 애드온은 협업 워크플로우에 대한 셀프 서비스 액세스, GPU 액세스를 통한 가속화, 간소화된 운영을 제공합니다. 기업은 하이브리드 클라우드 환경과 엣지에서 대규모 AI 솔루션을 일관되게 제공할 수 있습니다.
OpenShift AI는 Red Hat OpenShift의 애드온으로 제공되기 때문에 IT 운영 팀은 안정적이고 검증된 플랫폼에서 데이터 사이언티스트와 애플리케이션 개발자에게 더 간편한 구성을 제공할 수 있습니다. 데이터 사이언티스트와 애플리케이션 개발자는 이러한 구성을 손쉽게 확장하거나 축소할 수 있습니다. IT 팀은 악성 클라우드 플랫폼 계정을 추적할 필요가 없어 거버넌스와 보안에 대해 크게 우려하지 않아도 됩니다.
하이브리드 클라우드의 유연성 확보
Red Hat OpenShift AI는 클라우드 환경, 온프레미스 데이터센터 또는 데이터가 생성되거나 배치된 곳과 가까운 네트워크 엣지에서 AI/ML 워크로드를 학습, 배포, 모니터링할 수 있는 기능을 제공합니다. 이러한 유연성 덕분에 비즈니스 요구 사항에 따라 클라우드 또는 엣지로 운영을 이전하며 AI 전략이 진화할 수 있습니다. 기업은 에어 갭(air-gap) 환경과 연결되지 않은 환경을 포함하여 관련 규정, 보안, 데이터 요구 사항을 충족하는 데 필요한 모든 위치에서 모델 및 AI 지원 애플리케이션을 학습하고 배포할 수 있습니다.
2025년에 더 많은 예산을 배정할 기술 분야를 묻는 질문에 84%가 AI를 선택했는데, 이는 전년도의 73%보다 증가한 수치입니다.1
Red Hat OpenShift AI
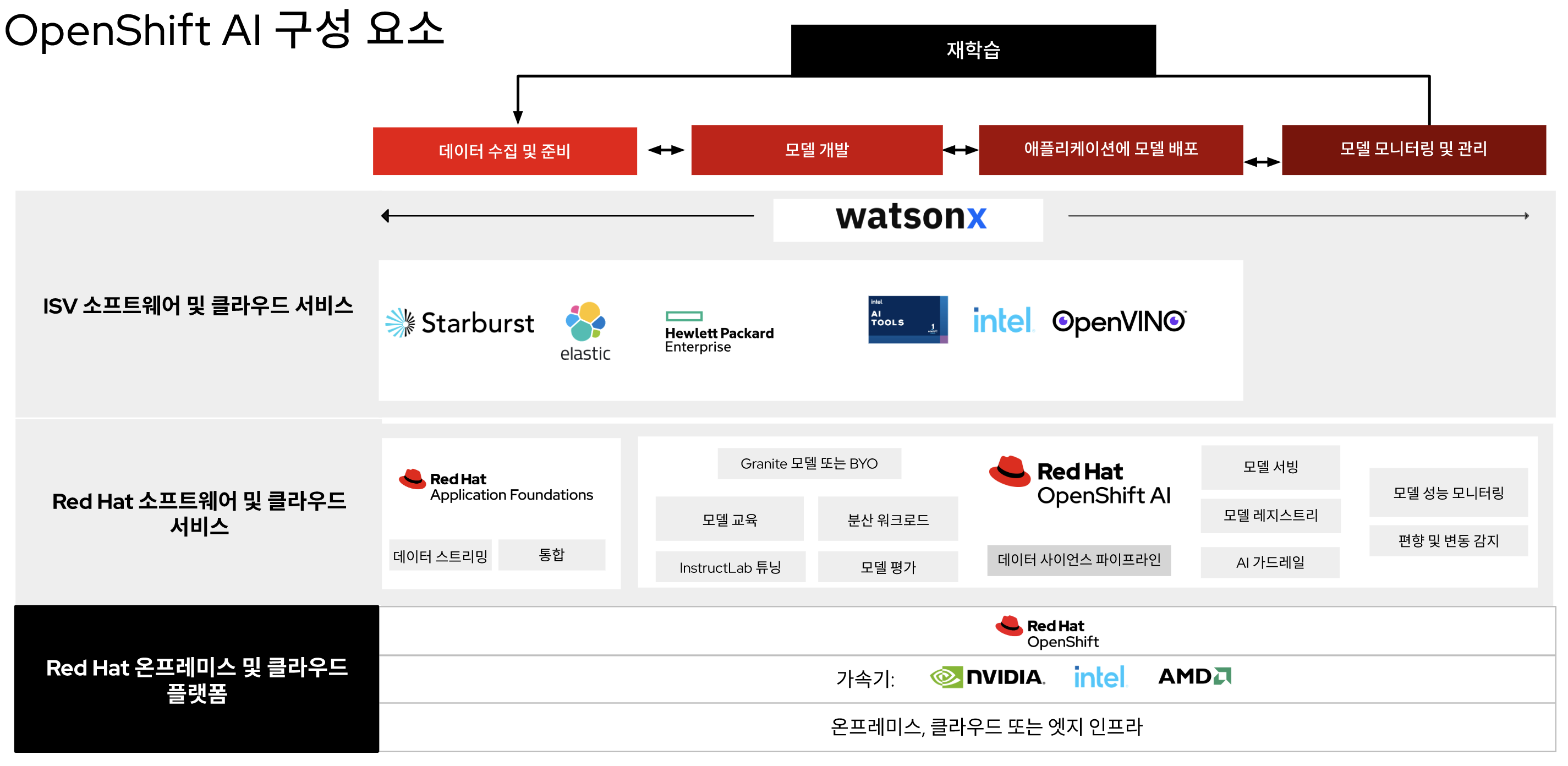
그림 1은 모델 운영 라이프사이클에 OpenShift AI를 공통 플랫폼으로 통합하여 선도적인 애플리케이션 플랫폼인 Red Hat OpenShift의 기능을 확장하는 방식을 보여줍니다. 기업은 기존 소프트웨어처럼 자체 관리형으로 제공되거나 관리형 클라우드 서비스로 제공되는 검증된 하이브리드 클라우드 플랫폼을 기반으로 구축하여 뛰어난 유연성을 제공할 수 있습니다. 자체 관리형 버전은 온프레미스 또는 3대 주요 퍼블릭 클라우드 환경 등 Red Hat OpenShift가 실행되는 모든 곳에서 실행할 수 있습니다. 클라우드 서비스 버전은 (AWS 또는 Google Cloud Platform 환경의) Red Hat OpenShift Service on AWS 및 Red Hat OpenShift Dedicated에서 사용할 수 있습니다.
Red Hat 솔루션을 사용하면 수십 가지 AI 소프트웨어 및 SaaS(Software-as-a-Service) 파트너로 구성된 광범위한 에코시스템과의 협업을 통해 AI 역량을 확장할 수 있습니다. Red Hat OpenShift AI는 유연하고 구성 가능하여 고객이 특정 요구 사항에 맞는 엔드 투 엔드 AI/ML 플랫폼을 구축할 수 있습니다.
생성형 AI 모델을 처음 사용하는 고객을 위해 OpenShift AI에는 Red Hat Enterprise Linux® AI의 구성 요소가 포함되는데, 이 솔루션은 Granite 대규모 언어 모델(LLM) 제품군을 개발, 테스트, 실행하여 엔터프라이즈 애플리케이션의 기능을 강화할 수 있는 파운데이션 모델 플랫폼입니다. 이 프레임워크는 Red Hat OpenShift AI에서 제공하는 Granite 모델 외에도 HuggingFace, Stability AI 및 기타 모델 리포지토리의 모델을 지원합니다.
Red Hat OpenShift AI는 IBM watsonx.ai의 기본 구성 요소로, 생성형 AI 워크로드를 위한 기본적인 AI 툴링과 서비스를 제공합니다. Watsonx는 AI 빌더가 코드 요구 사항이 적거나 코드 요구 사항이 없는 생성형 AI 애플리케이션, 사용하기 편리한 모델 개발 워크플로우, IBM 기반 모델과 큐레이션된 오픈소스 모델로 구성된 라이브러리에 대한 액세스를 구현할 수 있도록 엔터프라이즈 스튜디오를 제공합니다. Red Hat OpenShift 및 OpenShift AI는 watsonx 소프트웨어를 위한 임베디드 기술 전제 조건에 해당합니다.
Red Hat OpenShift AI가 제공하는 다음과 같은 핵심 툴과 기능으로 탄탄한 기반을 구축할 수 있습니다.
- 모델 구축 및 미세 조정. 데이터 사이언티스트는 JupyterLab UI에서 탐색적 데이터 사이언스를 수행할 수 있는데, 이 UI는 TensorFlow, PyTorch, CUDA 등 일반적인 Python 라이브러리 및 패키지를 통해 즉시 사용 가능하고 안전하게 빌드된 노트북 이미지를 제공합니다. 또한 기업은 고유의 사용자 정의 노트북 이미지를 제공함으로써 노트북을 생성하고 협업하는 동시에 프로젝트 및 워크벤치에서 작업을 구성할 수 있습니다.
- 모델 서빙. Red Hat OpenShift AI는 모델 서빙 라우팅에 필요한 다양한 프레임워크를 제공하여 컴퓨팅 리소스 요구 사항에 관계없이 예측 머신 러닝이나 파운데이션 모델을 프로덕션 환경에 배포하는 작업을 간소화합니다. 생성형 AI 워크로드의 경우, OpenShift AI는 vLLM 기반 모델 추론을 제공하여 가장 많이 사용되는 오픈소스 LLM(대규모 언어 모델) 전반에서 업계 최고의 성능과 효율성을 제공합니다. 또한 이 솔루션은 고객이 원하는 런타임을 적용하고 활용할 수 있도록 지원하여 유연성과 제어 권한을 보장합니다.
- 데이터 사이언스 파이프라인. Red Hat OpenShift AI에는 그래픽 프론트엔드를 사용하여 데이터 사이언스 태스크를 파이프라인으로 오케스트레이션하고 파이프라인을 구축할 수 있는 데이터 사이언스 파이프라인 구성 요소도 포함됩니다. 기업은 데이터 준비, 모델 빌드, 모델 서빙과 같은 프로세스를 연결할 수 있습니다.
- 모델 모니터링 Red Hat OpenShift AI는 운영 지향적인 사용자가 모델 서버 및 배포된 모델에 대한 운영 및 성능 메트릭을 모니터링하는 데 도움이 됩니다. 데이터 사이언티스트는 성능 및 운영 메트릭에 즉시 사용 가능한 시각화 기능을 사용하거나 데이터를 기타 관측성 서비스와 통합할 수 있습니다.
- 분산 워크로드. 팀은 분산 워크로드를 통해 모델 학습, 튜닝, 서빙, 데이터 처리 작업을 가속화할 수 있습니다. 이 기능은 작업 실행 우선순위를 지정하고 작업을 분산하며 노드를 최적의 방법으로 활용할 수 있도록 지원합니다. 고급 GPU 지원은 파운데이션 모델의 워크로드 요구 사항을 처리하는 데 도움이 됩니다.
- 편향 및 변동 감지. Red Hat OpenShift AI는 데이터 사이언티스트가 학습 데이터를 기반으로 모델이 공정하고 편향되지 않았는지 모니터링하고 나아가 실제 배포 과정에서도 공정성을 유지하도록 지원하는 툴을 제공합니다. 변동 감지 툴에는 배포된 ML 모델의 입력 데이터 분포 정보가 포함되어 모델 추론에 사용된 실시간 데이터와 모델 학습에 사용된 데이터 사이에 큰 차이가 있는 경우를 감지합니다.
- AI 가드레일(기술 프리뷰). AI 가드레일은 사용자가 요청할 수 있는 상호작용 유형을 보호하는 입력 감지기와 모델 출력의 안전을 점검하는 출력 감지기를 지원합니다. AI 가드레일은 혐오 표현, 욕설 또는 비속어, 개인 식별 정보, 경쟁 관련 기밀 정보 또는 기타 도메인별 제약 조건을 필터링하는 데 도움이 됩니다. Red Hat은 다양한 감지기를 제공하며, 고객은 원하는 감지기를 직접 추가할 수 있습니다.
- 모델 평가. 모델 탐색 및 개발 단계에서 LM-Eval(LM 평가) 구성 요소는 모델 품질에 대한 중요한 정보를 제공합니다. 데이터 사이언티스트는 LM-Eval을 통해 논리적 추론, 수학적 추론, 적대적 자연어 등 다양한 태스크에서 LLM 모델의 성능을 벤치마킹할 수 있습니다. Red Hat이 제공하는 벤치마크는 업계 표준을 기반으로 합니다.
- 모델 레지스트리. Red Hat OpenShift AI는 등록된 모델을 확인하고 관리할 수 있는 중앙 위치를 제공하여 데이터 사이언티스트가 예측 AI 및 생성형 AI 모델, 메타데이터, 모델 아티팩트를 공유, 버전 관리, 배포, 추적할 수 있도록 지원합니다.
OpenShift AI에는 Jupyter Notebook 이미지와 사전 패키징된 이미지나 기업의 사용자 정의 이미지를 데이터 사이언스 팀에 배포할 수 있는 Jupyter Spawner 외에도, JupyterLab에 대한 Git 플러그인이 포함되어 있어 사용자 인터페이스에서 Git과 신속하게 통합할 수 있습니다. 제품의 일환으로 제공되는 기타 공통 분석 패키지는 운영을 간소화하고 Pandas, scikit-learn, NumPy와 같이 프로젝트에 적합한 툴로 더욱 쉽게 시작할 수 있도록 도와줍니다. 또한 RStudio 서버(테스트 및 검증됨)와 VS Code 서버가 JupyterLab의 대체 IDE로 제공되어 데이터 사이언티스트에게 더 많은 선택권을 제공합니다. 데이터 사이언티스트는 프로젝트의 UI를 통해 자신만의 작업 공간을 생성하여 노트북 이미지와 아티팩트를 프로젝트로 구성 및 공유하고 다른 사용자와 협업할 수 있습니다.
생성형 AI 프로젝트의 경우, OpenShift AI는 분산형 InstructLab 학습을 프리뷰 기능으로 제공합니다. InstructLab은 Red Hat Enterprise Linux AI의 핵심 구성 요소로, 팀에 AI 전문 지식이 부족하더라도 비공개 데이터를 사용하여 소규모 언어 모델을 효율적으로 튜닝할 수 있도록 모델 정렬 툴을 제공합니다. 또한 Red Hat OpenShift AI는 LoRa/QLoRA를 사용하여 LLM(대규모 언어 모델)을 효율적으로 미세 조정(줄바꿈 없는 공백)할 수 있도록 지원하여 컴퓨팅 오버헤드와 메모리 사용량을 줄일 수 있고, 임베딩 기능을 지원하여 RAG에 필요한 벡터 데이터베이스와 텍스트 정보를 더 쉽게 통합할 수 있습니다.
예측 AI 모델과 생성형 AI 모델을 모두 서빙하기 위해서는 유연한 모델 서빙 방식이 필요합니다. Red Hat OpenShift AI는 다양한 모델 서빙 프레임워크를 지원하며, 제공된 다중 모델 및 단일 모델 추론 서버나 사용자 정의 추론 서버 중에서 선택할 수 있습니다. 모델 서빙 UI는 Red Hat OpenShift AI 대시보드 및 프로젝트 작업 공간에 직접 통합되어 있습니다. 기반 클러스터 리소스는 워크로드 요구 사항에 따라 확장 또는 축소할 수 있습니다. 최대 확장성이 필요한 LLM의 경우, Red Hat OpenShift AI는 vLLM 런타임을 통해 다양한 노드에서 병렬 방식으로 서빙을 제공하여 여러 요청을 실시간으로 처리할 수 있는 기능을 제공합니다.
전체 AI 라이프사이클을 위한 툴
Red Hat OpenShift는 기업이 성공적으로 모델을 학습시켜 배포하고 이를 프로덕션 단계로 전환할 수 있도록 지원하는 서비스와 소프트웨어를 제공합니다(그림 2). 이 프로세스는 OpenShift AI 외에도 Red Hat Application Foundations와 통합됩니다. 여기에는 실시간 데이터 및 이벤트 스트리밍을 위한 Apache Kafka 스트림, API 관리를 위한 Red Hat 3scale, 데이터 통합을 위한 Apache Camel의 Red Hat 빌드가 포함됩니다.
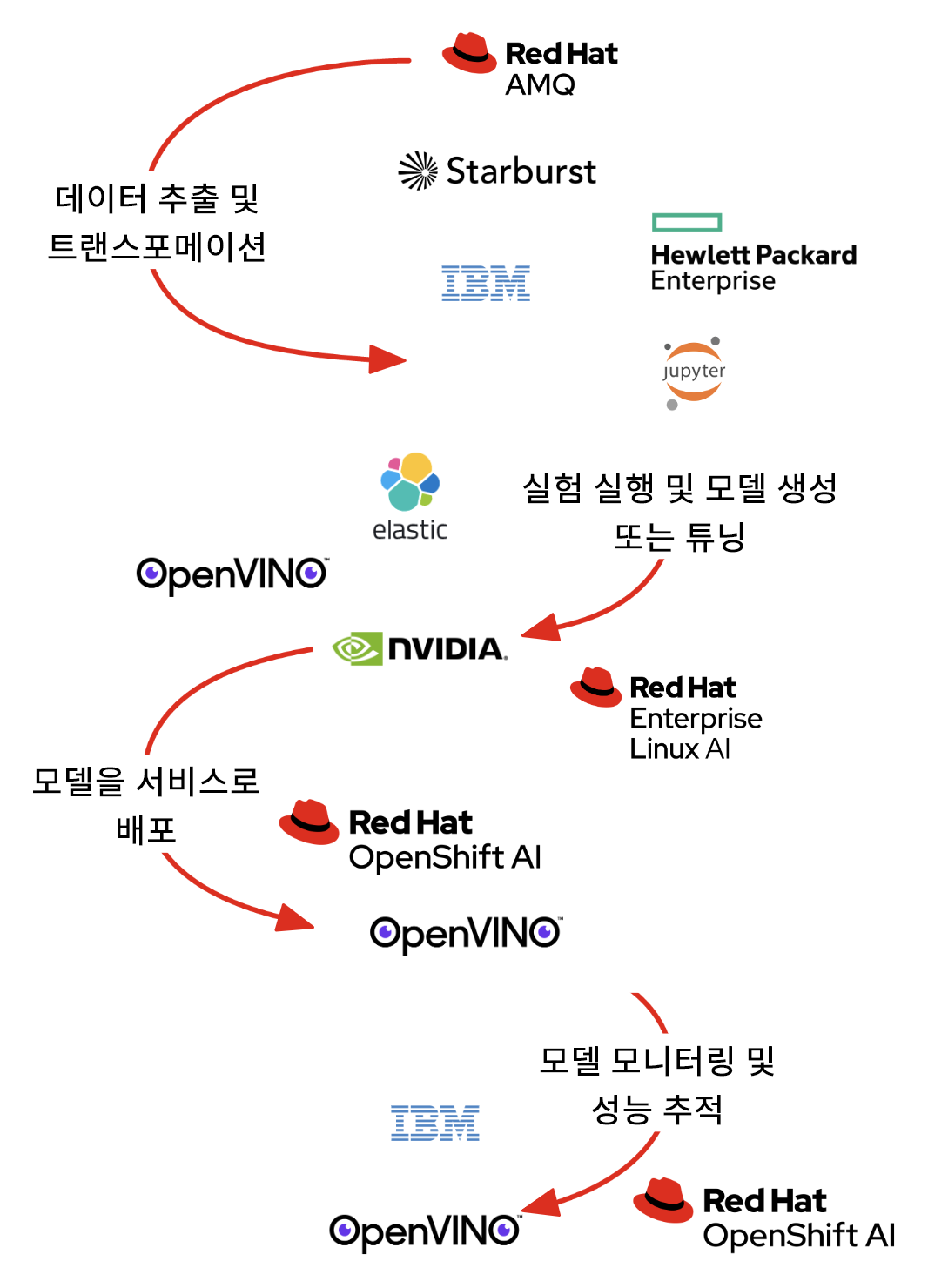
Red Hat OpenShift AI 대시보드는 원활한 도입을 위해 모든 애플리케이션과 도큐멘테이션을 찾고 액세스할 수 있는 중앙 위치를 제공합니다. 시작하는 방법에 관한 스마트 튜토리얼은 공통 구성 요소와 통합 파트너 소프트웨어에 대한 모범 사례 가이드를 제공하며, 이는 대시보드에서 직접 이용할 수 있어 데이터 사이언티스트가 더욱 빠르게 학습하고 시작할 수 있도록 도와줍니다. 다음 섹션에서는 Red Hat OpenShift AI에 통합된 기술 파트너 툴에 대해 설명합니다. 일부 툴에는 기술 파트너의 추가 라이센스가 필요합니다.
Starburst
Starburst는 팀이 데이터를 활용하여 쉽고 빠르게 비즈니스 기능을 개선하도록 하여 분석을 가속화합니다. 셀프 관리형 제품 또는 전체 관리형 서비스로 제공되는 Starburst는 데이터 액세스를 대중화하여 데이터 소비자에게 더욱 포괄적인 인사이트를 제공합니다. Starburst는 주요 대량 병렬 처리(Massively Parallel Processing, MPP) SQL 엔진인 오픈소스 Trino(이전 명칭: PrestoSQL)를 기반으로 구축되었습니다. Trino 전문가들과 Presto 창시자들이 구축하고 운영하는 Starburst는 데이터를 이동하지 않고도 위치와 관계없이 다양한 데이터세트를 검토할 수 있는 자유를 제공합니다.
Starburst는 Red Hat OpenShift가 제공하는 확장 가능한 클라우드 스토리지와 컴퓨팅 서비스와 통합되어 더욱 안정적이고 보안에 중점을 둔 효율적이고 경제적인 방법으로 모든 엔터프라이즈 데이터를 쿼리합니다. 장점은 다음과 같습니다.
- Automation. Starburst와 Red Hat OpenShift 오퍼레이터는 클러스터의 자동 구성, 자동 튜닝, 자동 관리 기능을 제공합니다.
- 고가용성 및 단계적 스케일 다운. Red Hat OpenShift 로드 밸런서는 Trino 코디네이터와 같은 서비스를 상시 가동 상태로 유지할 수 있습니다.
- 유연한 확장성. Red Hat OpenShift는 Trino 작업자 클러스터를 쿼리 로드에 따라 자동으로 확장할 수 있습니다.

기업은 노트북 실험부터 중요한 엔터프라이즈 배포까지 모든 것을 용이하게 지원하는 데이터 관리 솔루션을 필요로 합니다. HPE Machine Learning Data Management 소프트웨어(이전의 Pachyderm)를 사용하면 데이터 사이언스 팀이 자동 데이터 버전 관리를 통해 확보한 데이터 계보를 기반으로 컨테이너화된 데이터 중심의 ML 파이프라인을 구축하고 확장할 수 있습니다. 실제 데이터 사이언스 문제를 해결하도록 엔지니어링된 Pachyderm은 팀이 ML 라이프사이클을 자동화하고 확장할 수 있도록 데이터 기반을 제공하는 동시에 재현 가능성을 보장합니다. HPE Machine Learning Data Management 소프트웨어는 비정형 데이터에서 데이터 웨어하우스, 자연어 처리, 동영상 및 이미지 ETL(extract, transform, and load), 금융 서비스, 생명과학에 이르는 광범위한 활용 사례를 통해 다음 기능을 제공합니다.
- 팀이 모든 데이터 변경 사항을 높은 성능으로 추적할 수 있는 방법을 제공하는 자동화된 데이터 버전 관리
- 데이터 처리 속도를 높이는 동시에 컴퓨팅 비용을 낮추는 데이터 중심의 컨테이너화된 파이프라인
- ML 라이프사이클 내 모든 활동과 자산에 대한 고정된 기록을 제공하는 변경 불가능한 데이터 계보
- DAG(방향성 비순환 그래프, Directed Acyclic Graph)의 직관적인 시각화를 제공하고 디버깅과 재현 가능성을 지원하는 콘솔
- JupyterLab Mount Extension을 통해 버전 관리 데이터에 대한 포인트 앤 클릭(point-and-click) 인터페이스를 제공하는 Jupyter Notebook 지원
- 기업 내 다양한 팀 전반에서 HPE Machine Learning Data Management 소프트웨어를 규모에 맞게 배포하고 관리하는 강력한 툴을 통해 엔터프라이즈 관리

새로운 컴퓨팅 시대를 이끄는 NVIDIA의 가속 컴퓨팅 하드웨어 및 소프트웨어 플랫폼
비즈니스 성공에서 AI/ML 애플리케이션이 수행하는 역할이 점점 더 커짐에 따라, 기업은 복잡한 워크로드를 처리하고, 하드웨어 활용도를 최적화하며, 확장성을 제공할 수 있는 플랫폼이 필요하게 되었습니다. 확장 가능한 데이터 처리, 데이터 분석, 머신 러닝 학습 및 추론은 모두 많은 리소스가 필요한 태스크이며, 가속 컴퓨팅에 적합합니다.NVIDIA AI Enterprise 소프트웨어는 프로덕션급 AI 솔루션의 배포와 구축을 간소화합니다. NVIDIA AI Enterprise의 일부인 NVIDIA NIM은 고성능 AI 모델 추론을 안전하고 안정적으로 배포하도록 설계된 사용하기 쉬운 마이크로서비스 세트입니다. NVIDIA NIM을 사용하면 Red Hat OpenShift 환경 내에서 AI 모델의 관리 기능과 성능이 향상되어 AI 애플리케이션이 NVIDIA 가속 컴퓨팅 및 NVIDIA AI Enterprise 소프트웨어의 잠재력을 최대한 활용할 수 있습니다. NVIDIA 가속 컴퓨팅, NVIDIA AI Enterprise, Red Hat OpenShift AI를 함께 사용하면 리소스 할당을 개선하고, 효율성을 높이며, AI 워크로드 실행을 가속화할 수 있습니다.

Intel OpenVINO 툴킷
OpenVINO 툴킷의 Intel 배포판은 Intel 플랫폼상에서 고성능 DL 추론 애플리케이션의 개발과 배포를 가속화합니다. 이 툴킷을 사용하면 사실상 모든 신경망 모델을 도입, 최적화, 튜닝하고 OpenVINO 에코시스템의 개발 툴을 사용하여 포괄적인 AI 추론을 실행할 수 있습니다.
- 모델. 소프트웨어 개발자는 자체 DL 모델을 유연하게 사용할 수 있습니다. 또한 시장 출시를 앞당기기 위해 Intel이 Hugging Face와 협업하여 제공하는 OpenVINO 툴킷을 통해 사전 학습 및 최적화된 모델을 사용할 수도 있습니다.
- 최적화. OpenVINO 툴킷은 모델을 변환하여 편의성과 성능을 향상할 수 있는 다양한 방법을 제공하여 소프트웨어 개발자가 AI 모델을 더 빠르고 효율적으로 실행할 수 있도록 돕습니다. 개발자는 모델 변환 단계를 건너뛰고 TensorFlow, TensorFlow Lite, ONNX 또는 PaddlePaddle 형식에서 직접 추론을 실행할 수 있습니다. OpenVINO IR로 변환하면 성능이 최적화되어 첫 번째 추론에 걸리는 시간을 단축하고 저장 공간을 줄일 수 있습니다. Neural Network Compression Framework를 통해 성능을 한층 더 개선할 수 있습니다.
- 배포. OpenVINO Runtime Inference Engine은 추론 프로세스를 가속화하기 위해 애플리케이션에 통합되록 설계된 API(애플리케이션 프로그래밍 인터페이스)입니다. '한 번 작성하여 어디에나 배포'하는 방식을 통해 CPU(중앙 처리 장치), GPU, 가속기 등 다양한 Intel 하드웨어에서 추론 태스크를 효율적으로 실행할 수 있습니다.

Intel®의 AI 툴
Intel의 AI 툴(이전의 Intel AI 분석 툴킷)은 데이터 사이언티스트, AI 개발자, 연구자가 Intel 아키텍처에서 엔드 투 엔드 데이터 사이언스와 분석 파이프라인을 가속화할 수 있도록 익숙한 Python 툴과 프레임워크를 제공합니다. 구성 요소는 낮은 수준의 컴퓨팅 최적화를 위해 Intel의 oneAPI 라이브러리를 사용합니다. 이 툴킷은 ML을 통한 사전 처리 성능을 극대화하고 효율적인 모델 개발을 위해 상호운용성을 제공합니다.
Intel의 AI 툴을 사용하면 다음과 같은 이점이 있습니다.
- Intel XPU에서 고성능 DL 학습을 제공하고, TensorFlow와 PyTorch를 위한 Intel 최적화 DL 프레임워크, 사전 학습된 모델, 저정밀 툴을 통해 AI 개발 워크플로우에 신속한 추론 기능을 통합합니다.
- Intel에 최적화된 컴퓨팅 집약적인 Python 패키지, Modin, scikit-learn, XGBoost로 데이터 사전 처리와 ML 워크플로우에 대한 즉각적인 가속화를 달성합니다.
- Intel에서 직접 분석과 AI 최적화에 액세스하여 소프트웨어가 중단 없이 작동하도록 합니다.

Elastic
Elastic Search AI Platform(ELK Stack 기반)은 정확한 검색 기능과 지능적인 AI를 결합하여 사용자가 LLM을 더욱 빠르게 프로토타입화하고 통합하며, 생성형 AI를 활용하여 확장 가능하고 비용 효율적인 애플리케이션을 빌드할 수 있도록 지원합니다. Elastic Search AI Platform을 사용하면 혁신적인 RAG(검색 증강 생성, Retrieval Augmented Generation) 애플리케이션을 빌드하고, 관측성 문제를 사전에 해결하며, 복잡한 보안 위협에 대처할 수 있습니다. Elasticsearch는 온프레미스, 선택한 클라우드 제공업체 또는 에어 갭 환경 등 애플리케이션이 있는 곳에 배포할 수 있습니다.
Elastic은 Red Hat OpenShift AI, Hugging Face, Cohere, OpenAI 등을 포함한 에코시스템의 임베딩 모델과 단 한 번의 간단한 API 호출을 통해 통합됩니다. 이러한 접근 방식은 RAG 워크로드에 대한 하이브리드 추론 관리 코드를 명확하게 유지하며, 다음과 같은 기능을 제공합니다.
- 청킹, 커넥터, 웹 크롤러: 다양한 데이터세트를 검색 계층으로 수집
- 시멘틱 검색: 기본 제공 ML 모델인 ELSER(Elastic Learned Sparse EncodeR)와 E5 임베딩 모델을 통해 다국어 벡터 검색 지원
- 문서 및 필드 수준 보안: 기업의 역할 기반 액세스 제어에 매핑되는 권한 및 자격 부여 구현
Elastic Search AI Platform을 사용하면 전 세계 개발자가 함께하는 커뮤니티의 구성원이 되어 항상 가까이에서 영감과 지원을 얻을 수 있습니다. Slack, 토론 포럼 또는 소셜 미디어에서 Elastic 커뮤니티를 확인해 보세요.
결론
Red Hat OpenShift AI를 사용하는 기업은 AI 기반 애플리케이션 여정에서 실험하고 협업하며 궁극적으로 여정을 가속화할 수 있습니다. 데이터 사이언티스트는 Red Hat OpenShift AI를 Red Hat에서 관리하는 클라우드 기반 애드온 서비스로 사용하거나 자체 관리형 소프트웨어 솔루션으로 유연하게 사용할 수 있습니다. 이를 통해 모델을 빌드하는 위치에 관계없이 태스크를 간소화할 수 있습니다. IT 운영 팀은 MLOps 기능의 이점을 활용하여 모델을 프로덕션 환경에 더욱 신속하게 배포할 수 있습니다. GPU에 대한 액세스를 포함하여 개발자와 데이터 사이언티스트를 위한 셀프 서비스는 이미 엔터프라이즈 IT에서 사용하고 완전히 신뢰하는 애플리케이션 플랫폼에서의 혁신 속도를 높입니다. 컴퓨팅 접근 방식과는 달리 데이터 사이언티스트가 툴체인이 제한되지 않은 툴링을 선택하여 임의적인 제약 없이 새로운 데이터 인사이트를 도출할 수 있습니다.