在红帽 OpenShift 中实现容量管理和过量使用看似复杂,但了解几个关键概念后,一切都会变得很简单。下面将详细介绍您需要了解的 Pod 请求、限制和设置方面的最佳实践,以及各个主题如何推动实现有效的容量管理和过量使用。
Pod 请求
Pod 请求是指您指定的容器运行所需的最小计算资源量(如内存或 CPU)。例如,如果您将内存请求设置为 1Gi,则调度程序会先确保至少有 1Gi 的内存可用于您的 Pod,然后再将该 Pod 放置到节点上。
容量管理优势:确保为每个 Pod 预留必要的资源,防止资源短缺,并确保所有 Pod 都具备有效运维所需的最低资源保障。
Pod 限制
另一方面,Pod 限制是指您的 Pod 可使用的资源量上限。如果您将内存限制值设置为 2Gi,则 Pod 最多可以使用 2Gi 的内存,但不能超过。这项规定由内核通过 cGroups 强制执行,有助于防止任何单个 Pod 消耗过多资源并影响其他 Pod。
容量管理优势:防止单个 Pod 过度使用资源,确保资源在所有运行中的 Pod 之间公平分配。
过量使用
当限制值超过请求值时,即会触发过量使用。例如,如果 Pod 的内存请求值为 1Gi,限制值为 2Gi,则系统会根据 1Gi 的请求量进行调度,但该 Pod 实际可使用多达 2Gi 的内存。这意味着 Pod 存在 200% 的内存资源过量使用,因为它可以使用的内存量是所保证的内存量的两倍。
容量管理优势:通过允许 Pod 在资源可用时使用额外资源(但不保证这些资源),从而更高效地利用集群资源
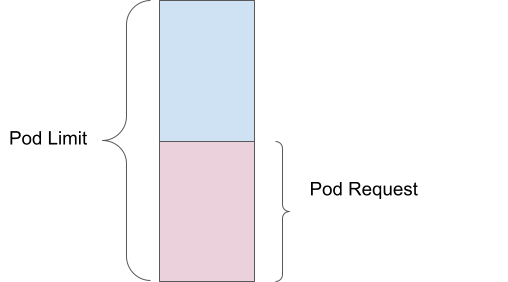
不设置请求值和限制值的后果
请求值和限制值可帮助您的红帽 OpenShift 实例以可预测的方式高效运行。如果未定义请求值和限制值,将会产生一些后果。
不保证资源
如果您未设置资源请求值,则调度程序无法保证为您的 Pod 提供任何特定数量的 CPU 或内存。这可能会导致性能欠佳,甚至在节点负载较重时出现 Pod 故障。
资源使用量无上限
如果未设置限制值,这意味着容器可以根据需要使用任意数量的 CPU 和内存。这样有可能会导致资源匮乏,即一个容器使用所有可用资源,导致其他容器失败或被驱逐。
容量管理优势:设置请求值和限制值可确保资源分配平衡,防止出现置备不足(资源匮乏)和过度置备(资源占用)。
设置请求值和限制值的最佳实践
通常情况下,在设置请求值和限制值时,可以遵循以下五项最佳实践:
- 始终设置内存和 CPU 请求值
- 避免设置 CPU 限制值,因为这可能会导致资源占用
- 监控您的工作负载。根据一段时间内的平均使用量设置请求值
- 根据请求值按比例设置内存限制值
- 使用垂直 Pod 自动缩放器(VPA),不断动态调优和调整这些值
容量管理优势:这些实践可确保每个 Pod 获得所需的资源,同时避免过度分配,从而实现高效的资源利用并提高集群性能。
使用垂直 Pod 自动缩放器(VPA)合理调整大小
当 Pod 需要更多资源时,红帽 OpenShift 的垂直 Pod 自动缩放器(VPA)组件会调整分配给 Pod 的 CPU 和内存量。在使用 VPA 时,请记住以下准则:
- 仅在推荐模式下安装和配置 VPA
- 在您的 Pod 上运行真实负载模拟
- 观察推荐值,并相应地调整 Pod 资源
为什么仅限推荐模式?
如果您将 VPA 设置为自动模式,Pod 会重新启动以调整为推荐值。截至红帽 OpenShift 4.16,就地 VPA(无需重新启动)仍处于 Alpha 阶段。
调整推荐系统的观察时间
VPA 支持自定义推荐系统,允许您根据自己的需求将观察时间设置为 1 天、1 周或 1 个月。有关更多详细信息,请阅读使用垂直 Pod 自动缩放器自动调整 Pod 资源级别。
容量管理优势:VPA 可根据实际使用模式来动态调整资源请求值和限制值,从而提供帮助。这可确保最佳的资源分配,并最大限度地减少过量使用。
红帽 OpenShift 中的系统预留资源
在红帽 OpenShift 中,可以将部分资源指定为系统预留资源。这意味着红帽 OpenShift 会将部分节点资源(CPU 和内存)分配给系统级进程,如 kubelet 和容器运行时。这种做法具有诸多优势:
- 确保为系统进程预留专用资源,避免与应用工作负载争用
- 通过防止基本系统服务资源匮乏,提高节点稳定性和性能
- 保障集群的可靠运维和可预测性能
您可以按照 OpenShift 文档中有关自助式 OpenShift 集群的说明,为节点启用自动资源分配。托管式 OpenShift 实例(如 AWS 上的红帽 OpenShift 服务(ROSA))可以为您管理这些内容。
容量管理优势:通过为系统进程分配资源,可确保基础服务平稳运行,防止因系统级资源争用而导致应用性能中断。
集群自动缩放器
集群自动缩放器可根据需要自动添加或删除节点,并与横向 Pod 自动缩放器(HPA)协同工作。如需了解更多详细信息,请参阅 OpenShift 集群自动缩放器指南和关于自动扩展的 OpenShift 文档。
容量管理优势:集群自动缩放器可确保您的集群具有处理当前工作负载所需的正确节点数量,并根据需要自动扩展或缩减。这有助于保持最佳的资源利用率和成本效益。
ClusterResourceOverride Operator(CRO)
ClusterResourceOverride Operator 有助于优化资源分配,确保整个集群的资源使用高效且均衡。
配置示例:
- 请求的 CPU:100 毫核(0.1 个核心)
- 请求的内存:200MiB(兆字节)
- CPU 限制:200 毫核(0.2 个核心)
- 内存限制:400MiB
覆写:
- CPU 请求值覆写:请求值的 50%
- 内存请求值覆写:请求值的 75%
- CPU 限制值覆写:请求值的 2 倍
- 内存限制值覆写:请求值的 2 倍
调整后的资源:
- 请求的 CPU:100 毫核 × 50% = 50 毫核(0.05 个核心)
- 请求的内存:200MiB × 75% = 150MiB
- CPU 限制值:50 毫核 × 2 = 100 毫核(0.1 个核心)
- 内存限制值:150MiB × 2 = 300MiB
有关更多详细信息,请参阅使用集群资源覆写 Operator 实现集群级过量使用。
容量管理优势:通过覆写默认的资源请求值和限制值,可确保高效地分配资源,防止资源利用率不足和过量使用。
可扩展性范围
我将可扩展性范围想象成一个高维立方体。只要保持在该范围内,您的性能服务级别目标(SLO)就能达成,红帽 OpenShift 集群也能平稳运行。当您沿某一维度扩展时,其他维度的容量就会相应缩减。您可以使用 OpenShift 信息面板来监控绿色区域(处于舒适区域内,可安全地扩展集群对象)和红色区域(若超出此范围,则不应继续扩展集群对象)。
有关更多详细信息,请参阅节点指标信息面板。
容量管理优势:了解可扩展性范围并在该范围内运维,有助于确保集群在不同负载下稳定运行,避免资源瓶颈并确保性能一致性。
Pod 自动扩展
在红帽 OpenShift 上自动扩展 Pod 的方法有很多种。我们已经讨论了垂直 Pod 自动扩展(VPA),但还有其他策略。
横向 Pod 自动扩展(HPA)
HPA 通过添加更多副本来横向扩展 Pod。这对于生产环境中的无状态应用非常有用,可以通过更好地处理负载并避免内存不足(OOM)终止,提高应用性能并延长正常运行时间。有关更多详细信息,请阅读使用横向 Pod 自动缩放器来自动扩展 Pod。
自定义指标自动缩放器
该工具将根据用户定义的指标来扩展您的 Pod,适用于生产、测试和开发等多种环境。它可以根据特定的压力点进行监控和扩展,从而延长应用的正常运行时间并提升性能。有关更多详细信息,请参阅自定义指标自动缩放器概述。
容量管理优势:基于工作负载需求自动扩展,这种方法可确保您的应用始终拥有处理不同负载所需的资源,从而提高性能和资源效率。
OpenShift 调度程序
OpenShift 调度程序的 LowNodeUtilization 配置文件会将 Pod 均匀地分配到各个节点,以降低每个节点的资源使用量。该方法的优势包括:
- 通过最大限度减少所需的节点数量,确保云环境中的成本效益
- 优化集群资源分配
- 提高数据中心能效
- 增强性能,防止出现节点过载
- 通过平衡工作负载防止资源匮乏
有关更多详细信息,请阅读使用调度程序配置文件调度 Pod。
容量管理优势:调度程序通过确保资源均匀分配,有助于避免出现热点和未充分利用的节点,从而实现更均衡、高效的集群运行。
OpenShift 反调度程序
AffinityAndTaints 配置文件驱逐违反 Pod 间反关联性、节点关联性和节点污点的 Pod。该方法的优势包括:
- 优化欠佳的 Pod 放置策略
- 实施节点关联性和反关联性
- 响应节点污点更改,以确保节点上仅保留兼容的 Pod
有关更多详细信息,请阅读使用反调度程序驱逐 Pod
容量管理优势:反调度程序有助于持续维护最佳的 Pod 放置策略,适应集群的变化,并在尊重关联性和污点约束的前提下,确保有效利用资源。
通过遵循这些最佳实践并使用 OpenShift 中提供的工具,您可以有效地管理容量和过量使用,确保应用平稳高效地运行。
红帽高级集群管理合理调整大小功能
红帽 Kubernetes 高级集群管理 — 合理调整大小功能现已推出增强型开发人员预览版。RHACM 合理调整大小的目标是为平台工程团队提供基于 CPU 和内存的命名空间级别建议。RHACM 正确调整大小功能目前由 Prometheus 记录规则提供支持,允许您在不同的聚合周期(1、2、5、10、30、60 和 90 天)内应用最大值和峰值逻辑。
使用 RHACM 合理调整大小功能的优势包括:
- 识别主要的资源不合理使用场景(例如,导致资源利用率低下的区域)
- 提高整个企业组织的透明度并引发相关对话
- 通过 RHACM 改进集群管理,无论您需要部署多少个托管集群,都能实现成本效益和资源优化
- 作为 RHACM 控制台的一部分,在专用的 Grafana 信息面板中提供简化的用户导航体验
容量管理优势:借助 RHACM 合理调整大小功能,平台工程师可访问专用 Grafana 信息面板(红帽 Kubernetes 高级集群管理控制台的一部分)中显示的基于 CPU 和内存的合理调整大小建议,并且用户可访问基于不同聚合周期(包括更长的时间范围)的关键建议,因为利用率会随时间而变化。因此,这些建议对用户友好且易于实施(参见下图)。
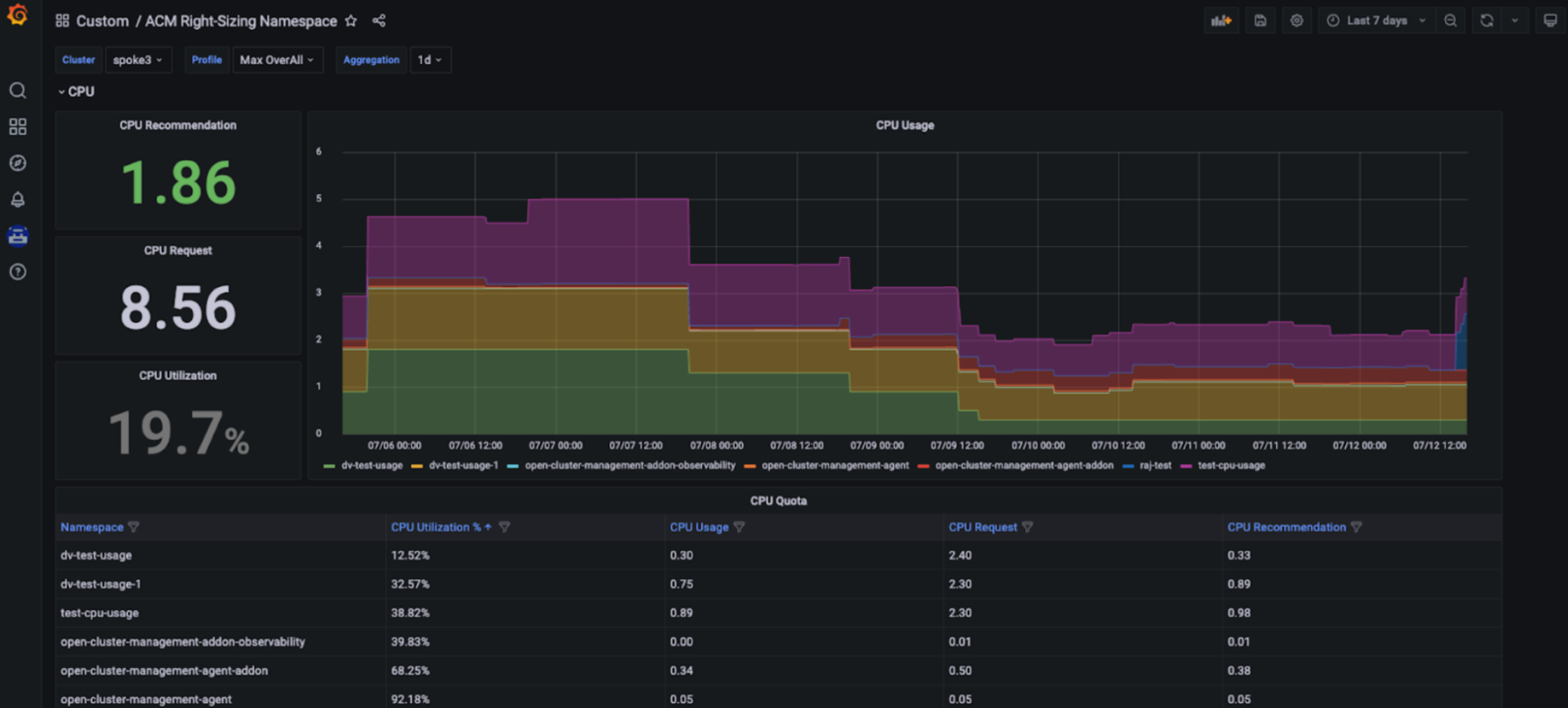
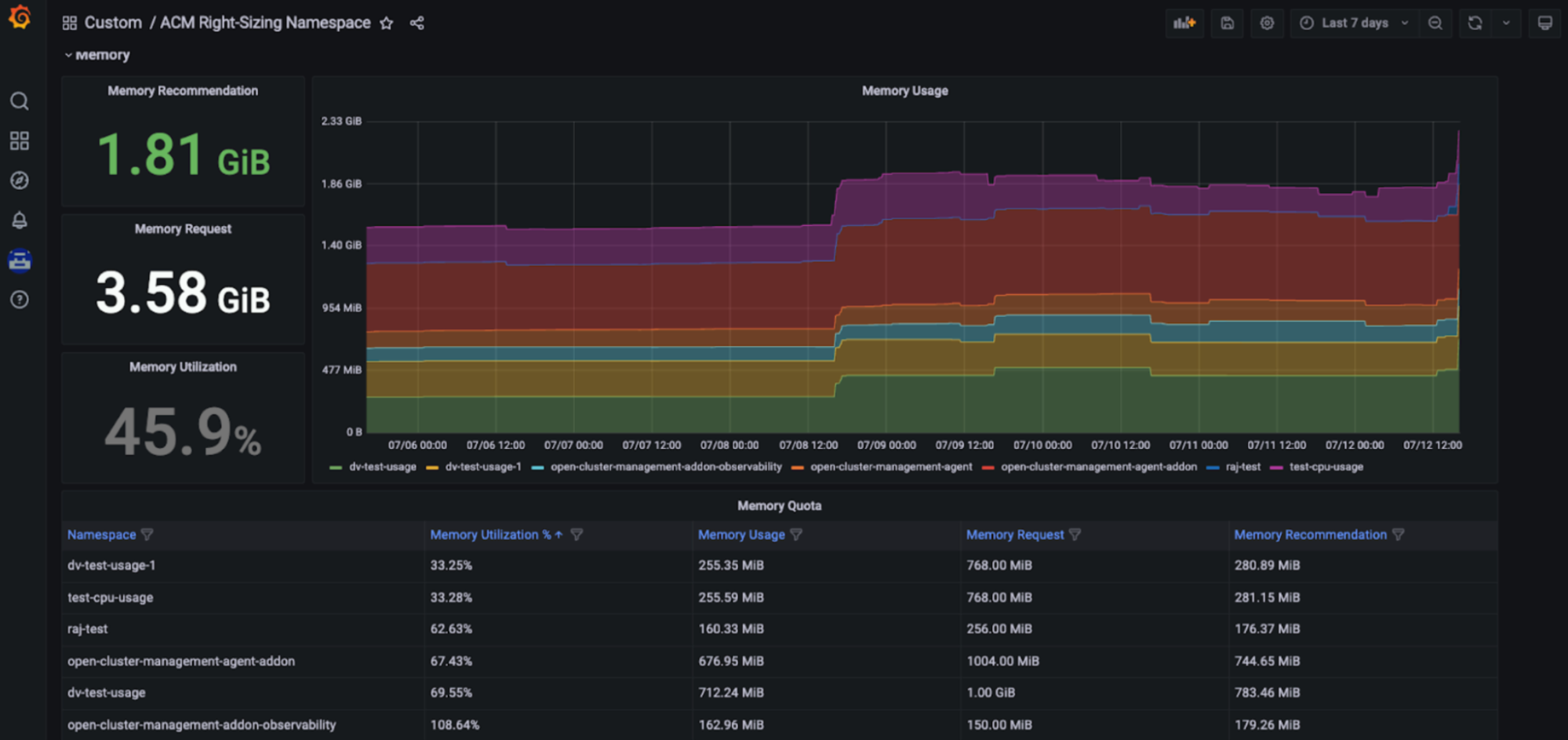
如何设置
有关前提条件和安装步骤的更多详细信息,请查看我们专门的博客。或者,您也可参考以下 GitHub 存储库。在努力发布技术预览版的同时,我们也在评估提供不同级别建议的可行性。与智能分析成本管理资源优化功能(参见下文)不同,RHACM 合理调整大小是一种不需要与红帽共享分析数据的解决方案。
使用红帽智能分析成本管理对 OpenShift 进行资源优化
定义
红帽智能分析成本管理是我们的 SaaS 解决方案,为您的所有云和 OpenShift 支出(包括本地部署)提供单一界面。
OpenShift 资源优化是红帽智能分析成本管理的一部分,这项功能已于近期正式发布。红帽智能分析中的资源优化功能旨在为开发团队提供具体的、切实可行的 CPU 和内存建议。此功能由 Kruize 开源项目提供支持。
优势
OpenShift 资源优化功能为开发人员提供容器级建议,包括容器、部署、部署配置、有状态集和副本集。
此功能会生成以下两组建议:
- 成本建议。如果您想要节省资金,或者通过调整命名空间配额、节点大小或节点数量来最大限度地提高集群利用率,可查看此类建议
- 性能建议。如果您的首要任务是让应用性能达到硬件所能支持的极限水平,可查看此类建议
目前,这两种类型的建议都是基于三个时间范围内的观察数据生成的,即:基于 24 小时的观察数据、基于 7 天的观察数据和基于 15 天的观察数据。
借助红帽智能分析成本管理生成的 OpenShift 资源优化建议,您能够节省资金并使应用发挥最佳性能,并且您可以查看这些建议的上下文以及工作负载的货币成本。
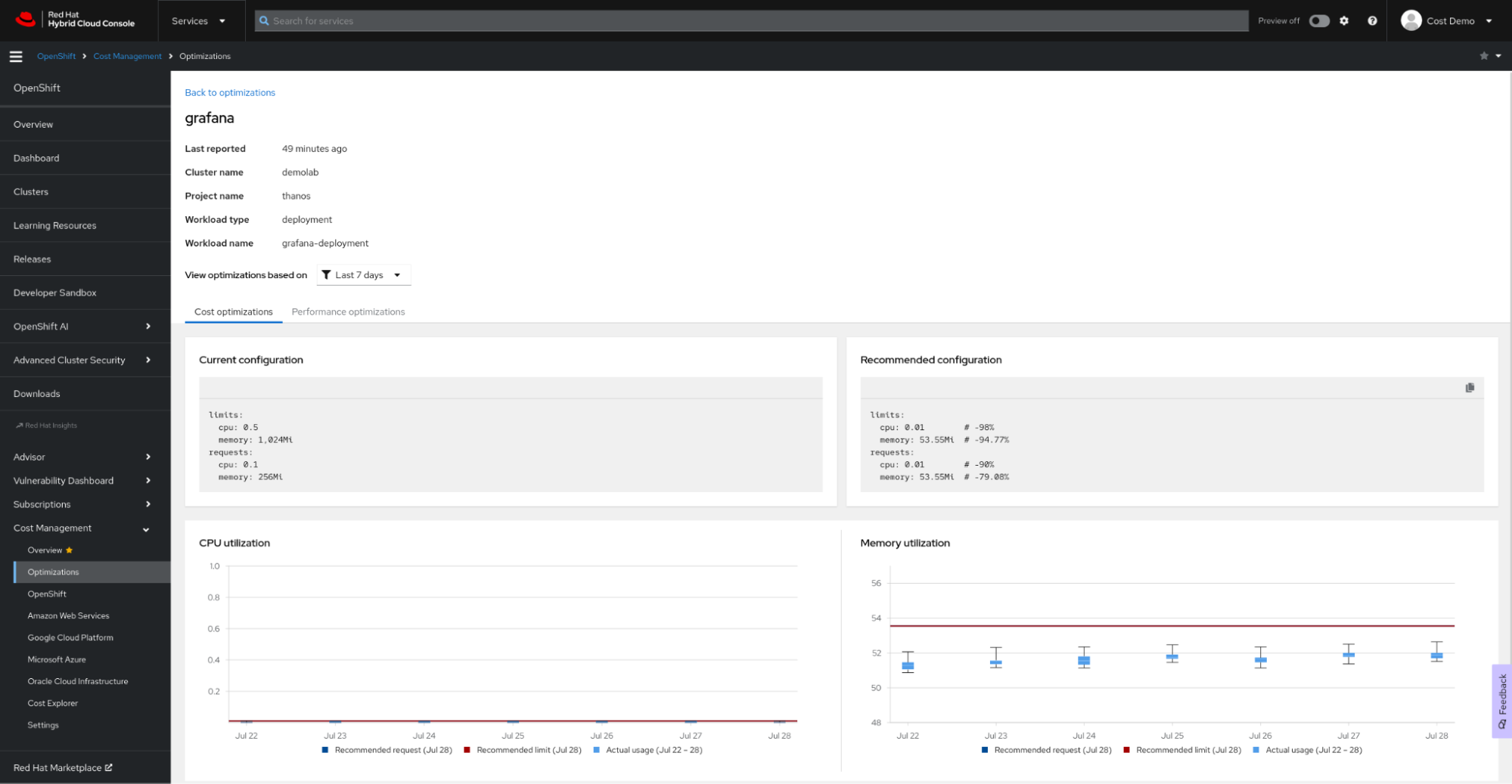
如何设置
OpenShift 资源优化建议是红帽智能分析成本管理中的另一项功能。按照红帽智能分析成本管理备忘单进行设置,并使用我们功能丰富的成本管理 API 在您首选的商业智能或可视化工具(如 Microsoft Excel、Power BI 或 Grafana)中创建自己的信息面板。无需进行复杂配置或分配昂贵的资源即可进行处理:成本管理指标 Operator 会将您的使用情况数据提交到红帽混合云控制台进行分析,并为您生成成本和资源智能分析(如果您的集群未连接到互联网,请查看我们的断开连接模式相关文档)。
关于作者


Vanessa is a Senior Product Manager in the Observability group at Red Hat, focusing on both OpenShift Analytics and Observability UI. She is particularly interested in turning observability signals into answers. She loves to combine her passions: data and languages.

Pau Garcia Quiles joined Red Hat in 2021 as Principal Product Manager. He has 20 years of experience in IT in various roles, both as a vendor and as a customer, systems administrator, software developer and project manager. He has been involved in open source for more than 15 years, most notably as a Debian maintainer, KDE developer and Uyuni developer.






