Gerenciar a capacidade e a superalocação no Red Hat OpenShift pode parecer complexo, mas entender alguns conceitos importantes simplifica o processo. Veja a seguir um detalhamento do que você precisa saber sobre solicitações de pod, limites e práticas recomendadas para configuração, além de como cada tópico contribui para o gerenciamento eficaz da capacidade e superalocação.
Solicitação de pod
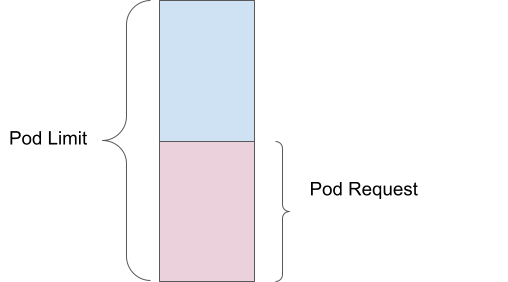
Uma solicitação de pod define a quantidade mínima de recursos de computação (como memória ou CPU) necessária para seu container funcionar. Por exemplo, se você definir uma solicitação de memória de 1 Gi, o scheduler garantirá que pelo menos 1 Gi esteja disponível para seu pod antes de colocá-lo em um nó.
Benefício do gerenciamento de capacidade: garante que recursos essenciais fiquem reservados para cada pod, evitando a escassez de recursos e garantindo que todos os pods tenham o mínimo de recursos necessários para operar com eficiência.
Limite de pod
Por outro lado, um limite de pod é a quantidade máxima de recursos que seu pod pode usar. Se você definir um limite de 2 Gi, o pod só poderá usar até 2 Gi de memória. Isso é aplicado pelo kernel por meio de cGroups, ajudando a impedir que um único pod consuma muitos recursos e afete outros pods.
Benefício do gerenciamento de capacidade: protege contra o uso excessivo de recursos por pods individuais, garantindo uma distribuição justa de recursos a todos os pods em execução.
Superalocação
A superalocação acontece quando o limite excede a solicitação. Por exemplo, se um pod tiver uma solicitação de memória de 1 Gi e um limite de 2 Gi, ele será agendado com base na solicitação de 1 Gi, mas poderá usar até 2 Gi. Isso significa que o pod está superalocado em 200%, pois pode usar o dobro da quantidade de memória garantida.
Benefício do gerenciamento de capacidade: permite uma utilização mais eficiente dos recursos do cluster ao possibilitar que os pods usem recursos adicionais quando disponíveis, sem garantir esses recursos.
Consequências de não definir solicitações e limites
As solicitações e os limites ajudam sua instância do Red Hat OpenShift a ser executada com eficiência e previsibilidade. Quando eles não são definidos, há consequências.
Sem recursos garantidos
Se você não definir solicitações de recurso, o scheduler não garantirá nenhuma quantidade específica de CPU ou memória para seus pods. Isso pode levar a um desempenho ruim ou, até mesmo, à falha do pod quando o nó estiver sob carga pesada.
Sem limite mais alto no uso de recursos
Sem limites, um container pode usar a quantidade de CPU e memória que precisar. Isso pode levar à escassez de recursos, onde um container usa todos os recursos disponíveis, fazendo com que outros containers falhem ou sejam removidos.
Benefício do gerenciamento de capacidade: definir solicitações e limites garante uma alocação de recursos equilibrada, evitando o provisionamento insuficiente (privação de recursos) e o excessivo (acúmulo de recursos).
Práticas recomendadas para definir solicitações e limites
Em geral, há cinco práticas recomendadas para definir solicitações e limites:
- Sempre defina solicitações de CPU e memória.
- Evite definir limites de CPU, já que isso pode levar a limitações.
- Monitore sua carga de trabalho. Defina solicitações com base na média de uso ao longo do tempo.
- Defina limites de memória para um fator de escala da solicitação.
- Use o Vertical Pod Autoscaler (VPA) para ajustar esses valores ao longo do tempo.
Benefício do gerenciamento de capacidade: essas práticas garantem que cada pod receba os recursos necessários enquanto evita a superalocação, levando à utilização eficiente de recursos e ao desempenho aprimorado do cluster.
Uso do Vertical Pod Autoscaler (VPA) para dimensionamento correto
O componente Vertical Pod Autoscaler (VPA) do Red Hat OpenShift ajusta a quantidade de CPU e memória atribuída a um pod quando este exige mais recursos. Ao usar o VPA, tenha em mente o seguinte:
- Instale e configure o VPA somente no modo de recomendação.
- Execute simulações de carga reais em seus pods.
- Observe os valores recomendados e ajuste os recursos do pod devidamente.
Por que somente no modo de recomendação?
Se você definir o VPA no modo automático, os pods serão reiniciados para se ajustarem aos valores recomendados. O VPA local (sem reinicializações) está em Alfa, a partir do Red Hat OpenShift 4.16.
Ajuste do tempo de exibição para recomendadores
O VPA tem suporte para recomendadores personalizados, permitindo que você defina tempos de exibição para um dia, uma semana ou um mês, conforme suas necessidades. Para mais detalhes, leia Automatically adjust pod resource levels with the vertical pod autoscaler.
Benefício do gerenciamento de capacidade: o VPA auxilia ajustando dinamicamente as solicitações e os limites de recursos com base em padrões reais de uso. Isso garante uma alocação ideal de recursos e minimiza a superalocação.
Recursos reservados do sistema no Red Hat OpenShift
Um recurso pode ser designado como reservado do sistema. Isso significa que o Red Hat OpenShift aloca uma parte dos recursos de nós (CPU e memória) para processos no nível do sistema, como o kubelet e o runtime de containers. Há muitos benefícios nisso:
- Garante recursos dedicados para os processos do sistema, evitando a contenção com cargas de trabalho de aplicações.
- Melhora a estabilidade e o desempenho dos nós ao evitar a escassez de recursos para serviços essenciais do sistema.
- Mantém a operação confiável e o desempenho previsível do cluster.
Você pode habilitar a alocação automática de recursos para nós seguindo as instruções para clusters autogerenciados do OpenShift nesta documentação. Uma instância gerenciada do OpenShift, como o Red Hat OpenShift Service on AWS (ROSA), cuida disso para você.
Benefício do gerenciamento de capacidade: com a alocação de recursos para processos do sistema, os serviços essenciais são executados sem problemas. Isso evita interrupções no desempenho das aplicações devido à contenção de recursos no nível do sistema.
Autoscaler de clusters
Um autoscaler de clusters adiciona ou remove nós automaticamente conforme necessário. Ele e o Horizontal Pod Autoscaler (HPA) funcionam em conjunto. Para mais detalhes, leia o guia do autoscaler de clusters do OpenShift e a documentação do OpenShift sobre escalabilidade automática (páginas em inglês).
Benefício do gerenciamento de capacidade: o autoscaler de clusters garante que seu cluster tenha o número certo de nós para lidar com a carga de trabalho atual, escalando automaticamente vertical ou horizontalmente conforme necessário. Isso ajuda a manter a economia e a utilização ideal de recursos.
Operador ClusterResourceOverride (CRO)
O operador ClusterResourceOverride ajuda a otimizar a alocação de recursos para garantir um uso eficiente e equilibrado em todo o cluster.
Exemplo de configuração:
- CPU solicitada: 100 milinúcleos (0,1 núcleo)
- Memória solicitada: 200 MiB (megabytes)
- Limite de CPU: 200 milinúcleos (0,2 núcleo)
- Limite de memória: 400 MiB
Substituições:
- Substituição da solicitação de CPU: 50% do que é solicitado
- Substituição da solicitação de memória: 75% do que é solicitado
- Substituição do limite de CPU: o dobro da solicitação
- Substituição do limite de memória: o dobro da solicitação
Recursos ajustados:
- CPU solicitada: 100 milinúcleos × 50% = 50 milinúcleos (0,05 núcleo)
- Memória solicitada: 200 MiB × 75% = 150 MiB
- Limite de CPU: 50 milinúcleos × 2 = 100 milinúcleos (0,1 núcleo)
- Limite de memória: 150 MiB × 2 = 300 MiB
Para mais detalhes, leia Cluster-level overcommit using the Cluster Resource Override Operator.
Benefício do gerenciamento de capacidade: ao substituir solicitações e limites padrão de recursos, você garante que estes sejam alocados com eficiência, evitando a subutilização e a superalocação.
Limites de escalabilidade
Penso nos limites de escalabilidade como um cubo de maior dimensão. Se você ficar dentro dos limites, seus objetivos de nível de serviço (SLO) de desempenho serão alcançados e seu cluster do Red Hat OpenShift funcionará sem problemas. Conforme você se move em uma dimensão, sua capacidade em outras dimensões diminui. Você pode usar o dashboard do OpenShift para monitorar suas zonas verdes (onde você está em segurança na zona de conforto para escalar os objetos do seu cluster) e vermelha (para além da qual você não deve escalar os objetos do cluster).
Para mais detalhes, leia Node metrics dashboard.
Benefício do gerenciamento de capacidade: entender e operar dentro dos limites de escalabilidade ajuda a garantir que seu cluster tenha um desempenho confiável sob cargas variadas, evitando gargalos de recursos e garantindo um desempenho consistente.
Escalabilidade automática de pods
Há vários métodos de escalabilidade automática de pods no Red Hat OpenShift. Já discutimos o Vertical Pod Autoscaling (VPA), mas também existem outras estratégias.
Horizontal Pod Autoscaling (HPA)
O HPA escala os pods horizontalmente adicionando mais réplicas. Isso é útil para aplicações stateless em ambientes de produção, melhorando o desempenho e o tempo de atividade da aplicação ao lidar melhor com a carga e evitar interrupções por falta de memória (OOM). Para mais detalhes, leia Automatically scaling pods with the horizontal pod autoscaler.
Custom Metric Autoscaler
Escala seus pods com base em métricas definidas pelo usuário, sendo adequado para vários ambientes, como, por exemplo, produção, teste e desenvolvimento. Ele melhora o tempo de atividade e o desempenho das aplicações ao monitorar e escalar com base em pontos de pressão específicos. Para mais detalhes, leia a visão geral do operador Custom Metrics Autoscaler (em inglês).
Benefício do gerenciamento de capacidade: a escalabilidade automática baseada na demanda da carga de trabalho garante que suas aplicações sempre tenham os recursos necessários para lidar com cargas variadas, melhorando o desempenho e a eficiência dos recursos.
Scheduler do OpenShift
O perfil LowNodeUtilization do scheduler do OpenShift distribui os pods uniformemente entre os nós para conseguir um baixo uso de recursos em cada nó. Os benefícios incluem:
- Economia de custos em ambientes de nuvem devido à redução do número de nós necessários
- Alocação de recursos aprimorada no cluster
- Eficiência energética em data centers
- Desempenho aprimorado ao evitar a sobrecarga de nós
- Prevenção da escassez de recursos com o balanceamento de cargas de trabalho
Para mais detalhes, leia Scheduling pods using a scheduler profile.
Benefício do gerenciamento de capacidade: ao garantir uma distribuição uniforme dos recursos, o scheduler ajuda a evitar pontos de acesso e nós subutilizados, resultando em um cluster mais equilibrado e eficiente.
Descheduler do OpenShift
O perfil AffinityAndTaints remove pods que violam a antiafinidade entre pods, a afinidade entre nós e os taints de nós. Os benefícios incluem:
- Correção do posicionamento de pods abaixo do ideal
- Aplicação de afinidades e antiafinidades de nós
- Resposta a alterações em taints de nós para garantir que somente pods compatíveis permaneçam no nó
Para mais detalhes, leia Evicting pods using the descheduler.
Benefício do gerenciamento de capacidade: o descheduler ajuda a manter o posicionamento ideal do pod ao longo do tempo, adaptando-se às mudanças no cluster e garantindo o uso eficiente dos recursos sem desrespeitar as restrições de taint e afinidade.
Ao seguir essas práticas recomendadas e usar as ferramentas disponíveis no OpenShift, você pode gerenciar a capacidade e a superalocação, garantindo que suas aplicações sejam executadas sem problemas e com eficiência.
Red Hat Advanced Cluster Management — Right Sizing
O Red Hat Advanced Cluster Management for Kubernetes — Right Sizing agora está disponível como uma prévia aprimorada do desenvolvedor. O objetivo do RHACM Right Sizing é fornecer às equipes de engenharia de plataforma recomendações baseadas em CPU e memória no nível do namespace. Atualmente, o RHACM Right Sizing se baseia nas regras de gravação do Prometheus, permitindo que você aplique a lógica de valor máximo e de pico em diferentes períodos de agregação (1, 2, 5, 10, 30, 60 e 90 dias).
Os benefícios de usar o RHACM Right Sizing incluem:
- Identificar os maiores infratores de recursos (por exemplo, áreas que causam subutilização)
- Promover a transparência na organização e iniciar conversas relevantes
- Melhorar o gerenciamento de frotas pelo RHACM, gerando economia e otimização de recursos, não importa quantos clusters gerenciados você tiver que implantar
- Ter uma navegação de usuário simplificada fornecida em um dashboard dedicado do Grafana, como parte do console do RHACM
Benefício do gerenciamento de capacidade: os recursos do RHACM Right Sizing permitem que os engenheiros da plataforma acessem recomendações de dimensionamento corretas, baseadas em CPU e memória, exibidas em um dashboard dedicado do Grafana que faz parte do console do Red Hat Advanced Cluster Management for Kubernetes. Com isso, os usuários podem acessar as principais recomendações baseadas em vários períodos de agregação, inclusive períodos mais longos, já que a utilização varia ao longo do tempo. Dessa forma, essas recomendações se tornam fáceis de usar e consumir (confira as imagens abaixo).
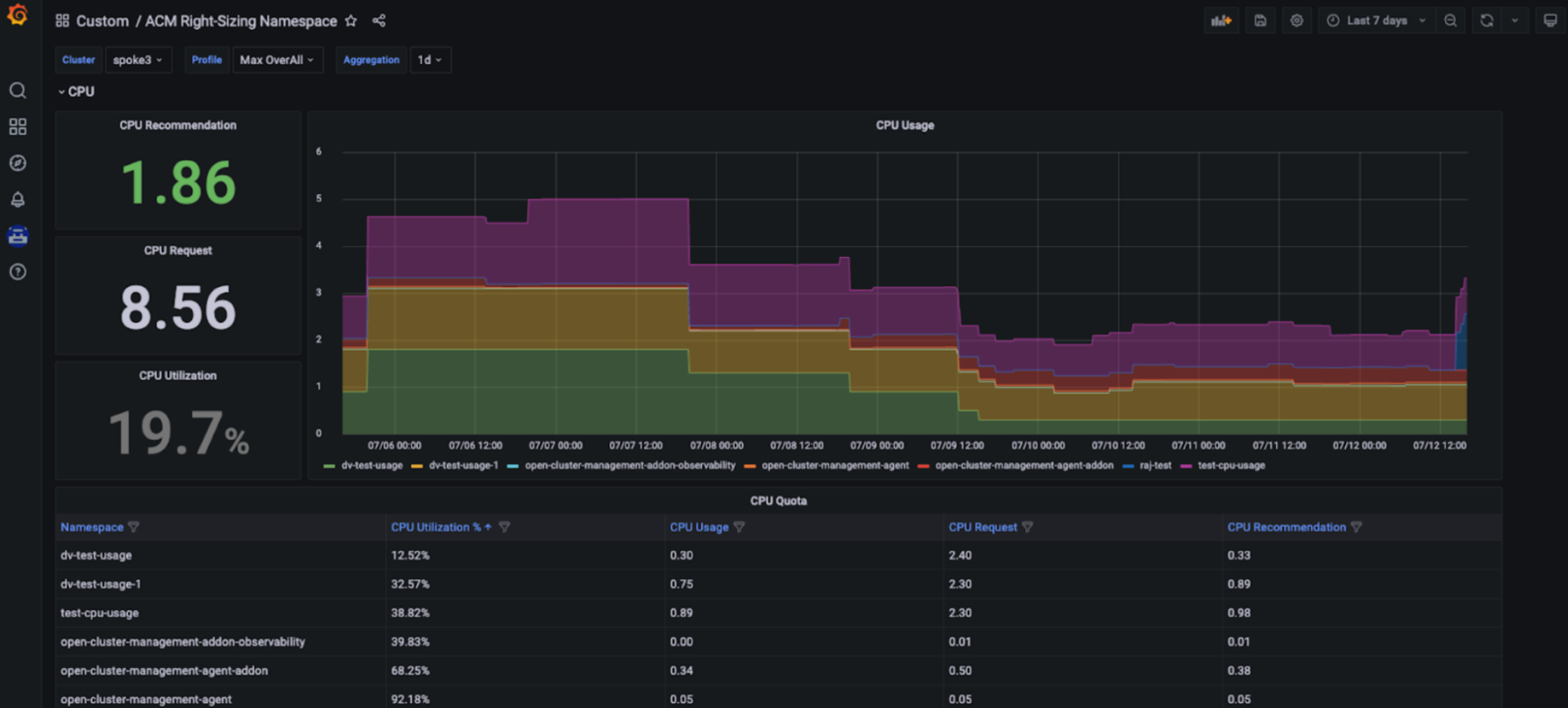
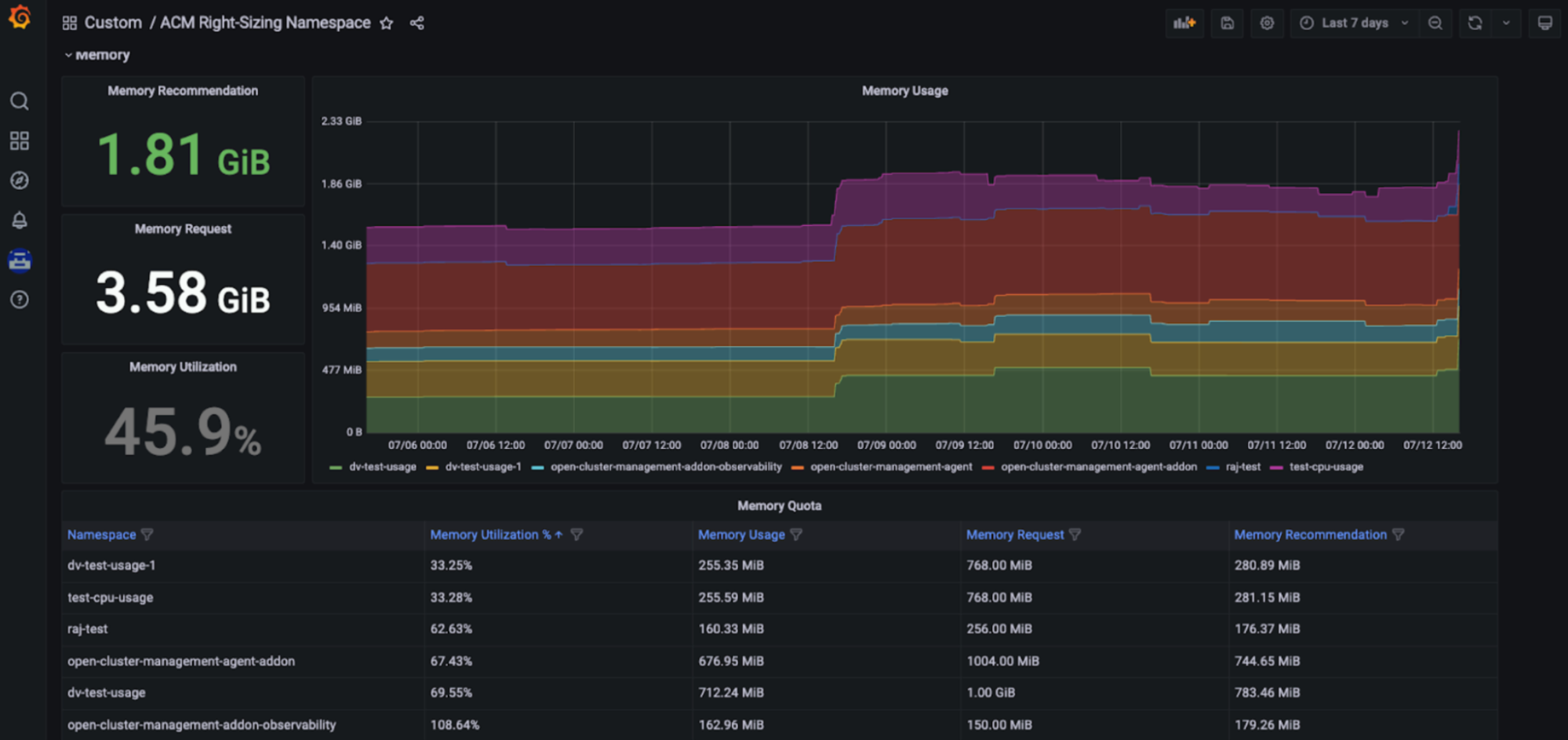
Como configurar
Para mais detalhes sobre os pré-requisitos e as etapas de instalação, confira nosso blog. O repositório do GitHub a seguir também pode ser consultado. À medida que trabalhamos para lançar uma apresentação prévia da tecnologia, também avaliamos a possibilidade de oferecer recomendações em diferentes níveis. Ao contrário da função de otimização de recursos de gerenciamento de custos do Insights (veja abaixo), o RHACM Right Sizing é uma solução que não exige o compartilhamento de dados de análise com a Red Hat.
Otimização de recursos do OpenShift usando o gerenciamento de custos do Red Hat Insights
Definição
O gerenciamento de custos do Red Hat Insights é a nossa solução de SaaS que fornece apenas um painel de controle para todos os seus gastos com a nuvem e o OpenShift, inclusive on-premise.
A otimização de recursos do OpenShift, parte do gerenciamento de custos do Red Hat Insights, chegou recentemente à disponibilidade geral. O objetivo da funcionalidade de otimização de recursos no Red Hat Insights é fornecer às equipes de desenvolvimento recomendações de CPU e memória práticas e específicas. Essa funcionalidade se baseia no projeto open source Kruize.
Benefícios
A otimização de recursos do OpenShift oferece aos desenvolvedores recomendações no nível de containers, como containers, deployments, deploymentconfigs, statefulsets e replicasets.
Dois conjuntos de recomendações são gerados:
- Recomendações de custo: consulte essas quando quiser economizar dinheiro ou maximizar o uso dos clusters ajustando as cotas de namespace, os tamanhos dos nós ou o número de nós.
- Recomendações de desempenho: confira essas quando sua principal prioridade for fazer suas aplicações terem o melhor desempenho possível no hardware.
Atualmente, os dois tipos de recomendações são gerados com base em três períodos de tempo: 24 horas, 7 dias e 15 dias de observação.
O gerenciamento de custos do Red Hat Insights faz recomendações para otimização dos recursos do OpenShift, ajudando você a economizar dinheiro e melhorar o desempenho da sua aplicação. Você também pode ver essas recomendações e o custo monetário da carga de trabalho em contexto.
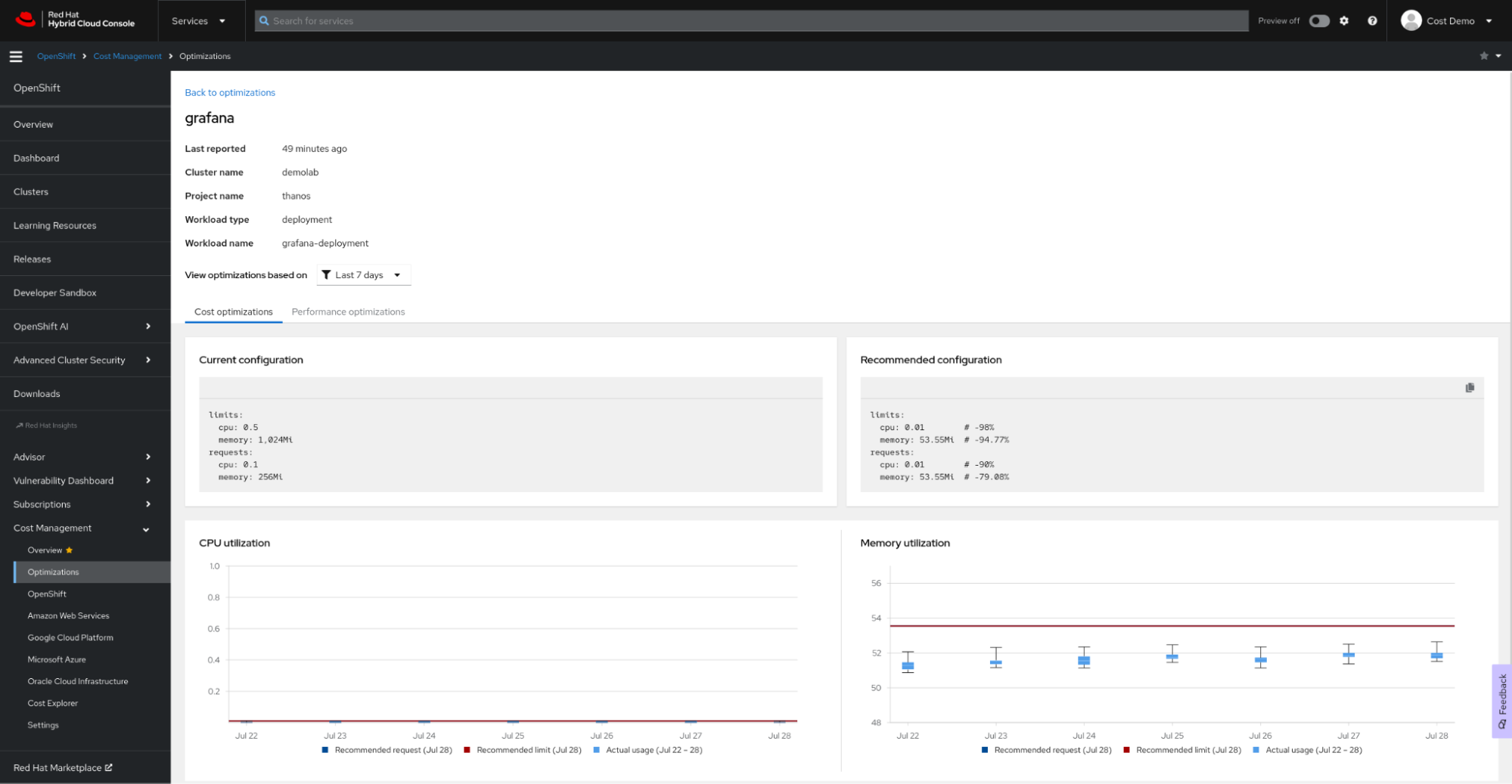
Como configurar
A otimização de recursos para recomendações do OpenShift é mais uma funcionalidade do gerenciamento de custos do Red Hat Insights. Siga as orientações do documento de gerenciamento de custos do Red Hat Insights para configurá-lo e use nossa avançada API de gerenciamento de custos para criar um dashboard próprio na sua ferramenta de visualização ou business intelligence preferida, como Microsoft Excel, Power BI ou Grafana. Não há necessidade de configurações complexas ou alocação de recursos caros para processamento: o operador Cost Management Metrics enviará seus dados de uso ao Red Hat Hybrid Cloud Console para análise e produzirá insights de custos e recursos para você (se seus clusters não estiverem conectados à internet, consulte nossa documentação sobre o modo desconectado).
Sobre os autores


Vanessa is a Senior Product Manager in the Observability group at Red Hat, focusing on both OpenShift Analytics and Observability UI. She is particularly interested in turning observability signals into answers. She loves to combine her passions: data and languages.

Pau Garcia Quiles joined Red Hat in 2021 as Principal Product Manager. He has 20 years of experience in IT in various roles, both as a vendor and as a customer, systems administrator, software developer and project manager. He has been involved in open source for more than 15 years, most notably as a Debian maintainer, KDE developer and Uyuni developer.
Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações
Virtualização
O futuro da virtualização empresarial para suas cargas de trabalho on-premise ou na nuvem