Si la gestion de la capacité et de la surallocation dans Red Hat OpenShift peut sembler complexe, il suffit de comprendre quelques concepts clés pour y voir plus clair. Dans cet article, vous en apprendrez plus sur les demandes et les limites de pod, les meilleures pratiques pour les définir et leurs avantages pour une gestion efficace de la capacité et de la surallocation.
Demande de pod
Une demande de pod correspond à la quantité de ressources de calcul (telles que la mémoire ou le processeur) définie comme configuration minimale requise pour l'exécution d'un conteneur. Par exemple, si vous définissez une demande de mémoire de 1 Gio, l'ordonnanceur s'assure qu'au moins 1 Gio de mémoire est disponible pour votre pod avant de le placer sur un nœud.
Avantage pour la gestion de la capacité : garantit que les ressources essentielles sont réservées pour chaque pod, ce qui permet d'éviter les pénuries de ressources et de s'assurer que tous les pods disposent des ressources minimales dont ils ont besoin pour fonctionner efficacement.
Limite de pod
La limite de pod, quant à elle, correspond à la quantité maximale de ressources qu'un pod peut utiliser. Si vous définissez une limite de mémoire de 2 Gio, le pod pourra utiliser jusqu'à 2 Gio de mémoire, pas plus. Le noyau applique cette règle à l'aide des cGroups, ce qui permet d'éviter qu'un pod utilise trop de ressources et affecte d'autres pods.
Avantage pour la gestion de la capacité : protège contre la surutilisation des ressources par chaque pod, ce qui permet d'assurer une répartition équitable des ressources entre tous les pods en cours d'exécution.
Surallocation
La surallocation se produit lorsque la limite dépasse la demande. Par exemple, si un pod présente une demande de mémoire de 1 Gio et une limite de 2 Gio, l'ordonnancement s'effectue sur la base de la demande de 1 Gio de mémoire, mais le pod peut en utiliser jusqu'à 2 Gio. Ce dépassement correspond à une surallocation de 200 %, car le pod peut utiliser deux fois la quantité de mémoire garantie.
Avantage pour la gestion de la capacité : permet d'utiliser plus efficacement les ressources du cluster en autorisant les pods à utiliser des ressources supplémentaires lorsqu'elles sont disponibles, sans qu'elles soient garanties.
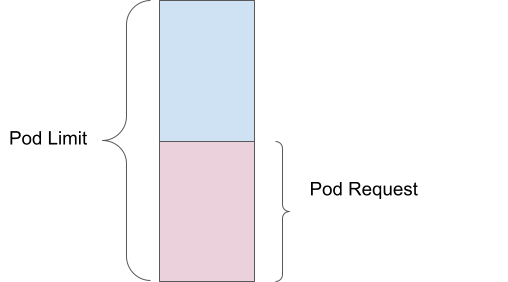
Conséquences de l'absence de configuration des demandes et limites
Les demandes et les limites assurent l'exécution efficace et prévisible des instances Red Hat OpenShift. Si elles ne sont pas définies, alors les conséquences peuvent être nombreuses.
Aucune ressource garantie
Si les demandes de ressources ne sont pas définies, l'ordonnanceur ne garantit aucune quantité spécifique de processeur ou de mémoire pour les pods. Cette situation peut dégrader les performances, voire provoquer la défaillance du pod lorsque le nœud est soumis à une charge élevée.
Aucune limite supérieure d'utilisation des ressources
Sans limites, un conteneur peut utiliser autant de ressources de processeur et de mémoire que nécessaire. Cette situation peut entraîner un manque de ressources, lorsqu'un conteneur utilise toutes les ressources disponibles, entraînant l'échec ou l'éviction d'autres conteneurs.
Avantage pour la gestion de la capacité : la configuration de demandes et de limites garantit une allocation équilibrée des ressources, permettant d'éviter les situations de sous-provisionnement (manque de ressources) ou de surprovisionnement (monopolisation des ressources).
Meilleures pratiques de configuration des demandes et des limites
Il existe cinq meilleures pratiques de base à suivre pour configurer des demandes et des limites :
- Toujours définir des demandes de mémoire et de processeur
- Éviter de définir des limites de processeur, pour ne pas causer une limitation
- Surveiller les charges de travail Définir des demandes en fonction de l'utilisation moyenne sur une période
- Définir des limites de mémoire en fonction du facteur d'échelle de la requête
- Utiliser l'opérateur Vertical Pod Autoscaler (VPA) pour régler et ajuster ces valeurs au fil du temps
Avantage pour la gestion de la capacité : ces pratiques permettent de s'assurer que chaque pod reçoit les ressources dont il a besoin tout en évitant la surallocation, avec à la clé une optimisation de l'utilisation des ressources et une amélioration des performances du cluster.
Opérateur Vertical Pod Autoscaler (VPA) pour le dimensionnement
L'opérateur VPA de Red Hat OpenShift ajuste la quantité de ressources de processeur et de mémoire attribuées à un pod lorsque ce dernier en demande plus. Pour utiliser l'opérateur VPA, appliquez les meilleures pratiques suivantes :
- Installer et configurer l'opérateur VPA en mode recommandation uniquement
- Exécuter des simulations de charges réelles sur les pods
- Respecter les valeurs recommandées et ajuster les ressources des pods en conséquence
Pourquoi utiliser le mode recommandation uniquement ?
Si vous configurez l'opérateur VPA en mode automatique, les pods sont redémarrés pour s'adapter aux valeurs recommandées. Depuis Red Hat OpenShift 4.16, l'opérateur VPA en place (sans redémarrage) est disponible en version alpha.
Ajustement des périodes de surveillance des outils de recommandation
L'opérateur VPA prend en charge la personnalisation des outils de recommandation, ce qui vous permet de définir des périodes de surveillance d'un jour, d'une semaine ou d'un mois, en fonction de vos besoins. Pour en savoir plus, consultez la section relative à l'ajustement automatique des niveaux de ressources des pods à l'aide de l'opérateur VPA dans la documentation d'OpenShift.
Avantage pour la gestion de la capacité : l'opérateur VPA ajuste les demandes et limites de ressources de manière dynamique, en fonction des schémas d'utilisation réels. Cette technique permet de garantir l'allocation optimale des ressources et de limiter la surallocation.
Ressources réservées au système dans Red Hat OpenShift
Une ressource peut être désignée comme étant réservée au système : Red Hat OpenShift alloue une partie des ressources des nœuds (processeur et mémoire) aux processus au niveau du système, tels que l'exécution du kubelet et des conteneurs. Ce mécanisme présente de nombreux avantages :
- Allocation garantie de ressources réservées aux processus système, ce qui évite les conflits avec les charges de travail des applications
- Amélioration de la stabilité et des performances des nœuds en évitant que les services système essentiels ne manquent de ressources
- Fonctionnement fiable et prévisibilité des performances du cluster
Vous pouvez activer l'allocation automatique des ressources pour les nœuds en suivant les consignes relatives aux clusters OpenShift autogérés décrites dans la documentation d'OpenShift. Vous pouvez aussi opter pour une instance OpenShift gérée, telle que Red Hat OpenShift Service on AWS (ROSA), qui se chargera de la gestion des ressources à votre place.
Avantage pour la gestion de la capacité : l'allocation de ressources aux processus système permet de garantir le bon fonctionnement des services essentiels et de préserver le niveau de performances des applications puisqu'il n'y a pas de limites d'utilisation au niveau du système.
Mise à l'échelle automatique du cluster
Le composant Cluster Autoscaler ajoute ou supprime automatiquement des nœuds selon les besoins. Cet outil fonctionne en parallèle du composant Horizontal Pod Autoscaler (HPA). Pour plus d'informations, consultez un article sur Cluster Autoscaler dans OpenShift et la documentation d'OpenShift sur la mise à l'échelle automatique.
Avantage pour la gestion de la capacité : l'utilisation de Cluster Autoscaler permet de s'assurer que le cluster dispose de suffisamment de nœuds pour gérer la charge de travail actuelle, en adaptant automatiquement la quantité selon les besoins. Cette technique favorise l'optimisation de l'utilisation des ressources et la rentabilité.
Opérateur Cluster Resource Override (CRO)
L'opérateur Cluster Resource Override permet d'optimiser l'allocation des ressources afin de garantir leur utilisation efficace et équilibrée au sein du cluster.
Exemple de configuration :
- Demande de processeur : 100 millicœurs (0,1 cœur)
- Demande de mémoire : 200 Mio (mébioctets)
- Limite de processeur : 200 millicœurs (0,2 cœur)
- Limite de mémoire : 400 Mio
Configuration de remplacement :
- Remplacement de la demande de processeur : 50 % de la demande
- Remplacement de la demande de mémoire : 75 % de la demande
- Remplacement de la limite de processeur : 2 fois la demande
- Remplacement de la limite de mémoire : 2 fois la demande
Ressources ajustées :
- Demande de processeur : 100 millicœurs x 50 % = 50 millicœurs (0,05 cœur)
- Demande de mémoire : 200 Mio x 75 % = 150 Mio
- Limite de processeur : 50 millicœurs × 2 = 100 millicœurs (0,1 cœur)
- Limite de mémoire : 150 Mio × 2 = 300 Mio
Pour en savoir plus, consultez la section relative à la surallocation de ressources au niveau du cluster à l'aide de l'opérateur Cluster Resource Override dans la documentation d'OpenShift.
Avantage pour la gestion de la capacité : en remplaçant les demandes et limites de ressources par défaut, vous vous assurez que les ressources sont allouées efficacement tout en évitant les situations de sous-utilisation et de surallocation.
Cadre de mise à l'échelle
J'aime comparer les limites de l'évolutivité à un hypercube : si on reste dans les limites, on atteint les objectifs de niveau de service en matière de performances et le cluster Red Hat OpenShift fonctionne correctement. Mais si on se déplace vers un côté, les capacités situées au niveau des autres côtés diminuent. Vous pouvez utiliser le tableau de bord OpenShift pour surveiller la zone verte (votre zone de confort pour la mise à l'échelle de vos objets de cluster) et la zone rouge (au-delà de laquelle la mise à l'échelle n'est pas souhaitable).
Pour en savoir plus, consultez la documentation sur le tableau de bord des indicateurs de mesure des nœuds.
Avantage pour la gestion de la capacité : la compréhension et le respect du cadre de mise à l'échelle permettent de s'assurer que votre cluster fonctionne de manière fiable quelle que soit la charge. Vous pouvez ainsi éviter les goulets d'étranglement au niveau des ressources et garantir la cohérence des performances.
Mise à l'échelle automatique des pods
Il existe plusieurs méthodes de mise à l'échelle automatique des pods sur Red Hat OpenShift. Nous avons déjà parlé de l'opérateur Vertical Pod Autoscaler (VPA), mais il existe d'autres stratégies.
Opérateur Horizontal Pod Autoscaler (HPA)
Avec l'opérateur Horizontal Pod Autoscaler, les pods sont mis à l'échelle de façon horizontale en ajoutant des réplicas. Cette technique est très utile pour les applications stateless dans les environnements de production, car elle améliore les performances et la disponibilité des applications en gérant mieux la charge et en évitant l'intervention du mécanisme OOM (Out of Memory) Killer. Pour en savoir plus, consultez la section relative à la mise à l'échelle automatique des pods avec l'opérateur Horizontal Pod Autoscaler dans la documentation d'OpenShift.
Opérateur Custom Metrics Autoscaler
Cet opérateur permet la mise à l'échelle de pods en fonction d'indicateurs de mesure définis par l'utilisateur, adaptés à divers environnements (production, test et développement). Il améliore la disponibilité et les performances des applications grâce à la surveillance et à la mise à l'échelle en fonction de contraintes spécifiques. Pour en savoir plus, consultez la section relative à l'opérateur Custom Metrics Autoscaler dans la documentation d'OpenShift.
Avantage pour la gestion de la capacité : la mise à l'échelle automatique basée sur la demande des charges de travail garantit que les applications disposent toujours des ressources nécessaires pour gérer des charges variables, ce qui améliore à la fois les performances et l'efficacité des ressources.
Ordonnancement dans OpenShift
Le profil LowNodeUtilization de l'ordonnanceur d'OpenShift répartit uniformément les pods entre les nœuds pour diminuer l'utilisation des ressources de chaque nœud. Voici quelques-uns des avantages de cette pratique :
- Baisse des coûts dans les environnements cloud grâce à la réduction du nombre de nœuds nécessaires
- Amélioration de l'allocation des ressources dans le cluster
- Efficacité énergétique dans les datacenters
- Amélioration des performances grâce à la prévention de la surcharge des nœuds
- Prévention du manque de ressources grâce à l'équilibrage des charges de travail
Pour en savoir plus, consultez la section relative à l'ordonnancement des pods à l'aide d'un profil dans la documentation d'OpenShift.
Avantage pour la gestion de la capacité : en assurant une distribution équilibrée des ressources, l'ordonnanceur permet d'éviter les zones surutilisées et les nœuds sous-utilisés, avec à la clé un cluster plus équilibré et efficace.
Opérateur Descheduler
Le profil AffinityAndTaints supprime les pods qui enfreignent l'anti-affinité entre les pods, ainsi que l'affinité et les rejets des nœuds. Voici quelques-uns des avantages de cette pratique :
- Correction des placements de pod insatisfaisants
- Mise en application des affinités et anti-affinités des nœuds
- Réponse aux changements de rejet de nœud pour s'assurer que seuls des pods compatibles restent sur le nœud
Pour en savoir plus, consultez la section relative à l'éviction de pods à l'aide de l'opérateur Descheduler dans la documentation d'OpenShift.
Avantage pour la gestion de la capacité : l'opérateur Descheduler permet d'optimiser le placement des pods au fil du temps, en s'adaptant aux changements du cluster et en garantissant une utilisation efficace des ressources tout en respectant les contraintes d'affinité et de rejet.
En suivant ces meilleures pratiques et en utilisant les outils disponibles dans OpenShift, vous pouvez gérer efficacement la capacité et la surallocation pour une exécution efficace et optimale de vos applications.
Outil de dimensionnement de Red Hat Advanced Cluster Management (RHACM)
L'outil de dimensionnement de Red Hat Advanced Cluster Management for Kubernetes est maintenant disponible dans une version améliorée pour les équipes de développement. Il est conçu pour fournir aux équipes d'ingénierie de plateforme des recommandations d'espaces de noms basées sur le processeur et la mémoire. Cet outil est actuellement optimisé par les règles d'enregistrement Prometheus, permettant d'appliquer une logique de valeurs maximales sur différentes périodes d'agrégation (1, 2, 5, 10, 30, 60 et 90 jours).
L'outil offre divers avantages :
- Identification des éléments qui entraînent une utilisation inefficace des ressources (par exemple, les domaines qui provoquent une sous-utilisation)
- Promotion de la transparence au sein de l'entreprise et source de conversations pertinentes
- Amélioration de la gestion de flotte avec RHACM, permettant de réaliser des économies et d'optimiser les ressources, quel que soit le nombre de clusters gérés à déployer
- Simplification de la navigation utilisateur dans un tableau de bord Grafana spécifique et intégré à la console de RHACM
Avantage pour la gestion de la capacité : avec cet outil de dimensionnement, les équipes d'ingénierie de plateforme ont accès à des recommandations en fonction du processeur et de la mémoire, dans un tableau de bord Grafana spécifique et intégré à la console de RHACM. Ces recommandations clés, facilement exploitables, sont basées sur différentes périodes d'agrégation, y compris des périodes plus longues, en fonction de l'évolution de l'utilisation (voir les figures ci-dessous).
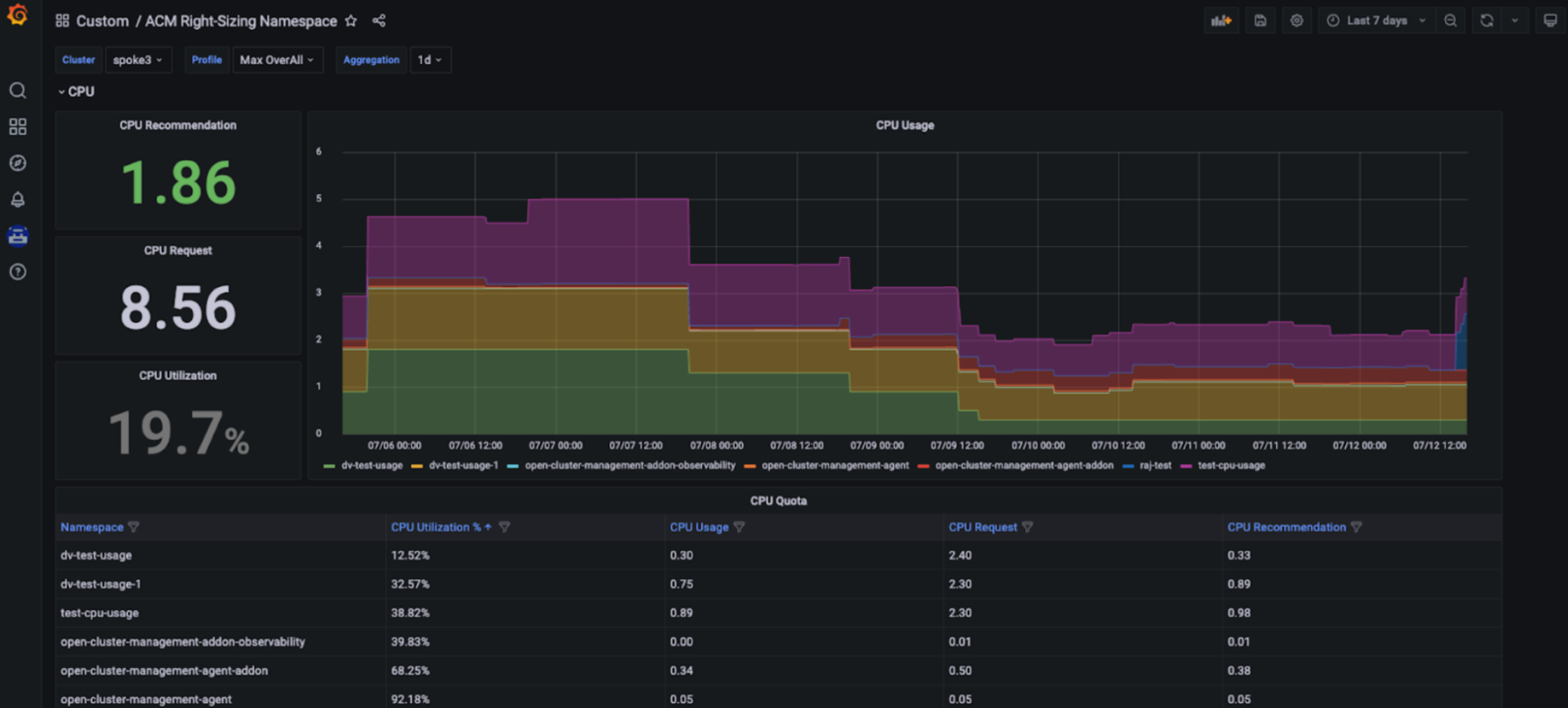
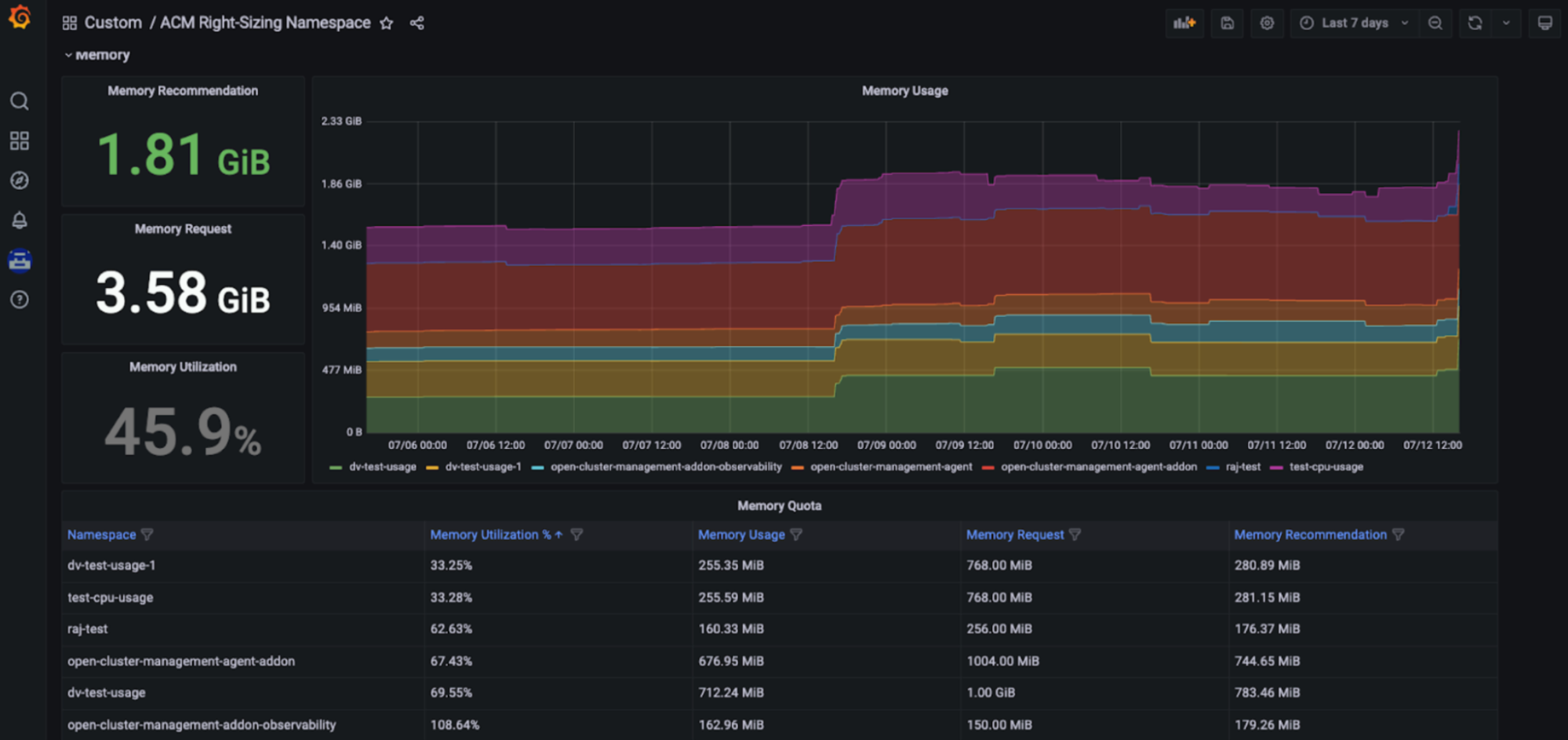
Configuration
Pour en savoir plus sur les conditions préalables et les étapes d'installation, consultez l'article de blog sur cet outil. Vous pouvez également consulter ce référentiel GitHub. Dans la perspective d'une version préliminaire, nous envisageons également de fournir des recommandations à différents niveaux. Contrairement à la fonction d'optimisation des ressources du service de gestion des coûts de Red Hat Insights (voir ci-dessous), cet outil ne nécessite pas de partager des données d'analyse avec Red Hat.
Optimisation des ressources pour OpenShift avec le service de gestion des coûts de Red Hat Insights
Définition
Solution SaaS, le service de gestion des coûts de Red Hat Insights donne un aperçu de toutes vos dépenses liées au cloud et à OpenShift, y compris sur site, dans une interface unifiée.
Composant du service de gestion des coûts de Red Hat Insights, la fonction d'optimisation des ressources pour OpenShift est désormais disponible pour tous les utilisateurs. Cette fonction vise à fournir aux équipes de développement des recommandations spécifiques et exploitables concernant le processeur et la mémoire. Cette fonction est optimisée par le projet Open Source Kruize.
Avantages
La fonction d'optimisation des ressources pour OpenShift fournit aux équipes de développement des recommandations au niveau des conteneurs, notamment concernant les déploiements et les objets DeploymentConfig, StatefulSet et ReplicaSet.
Elle génère deux types de recommandations :
- Des recommandations liées aux coûts, pour réaliser des économies ou optimiser l'utilisation des clusters en ajustant les quotas d'espaces de noms, la taille des nœuds ou leur quantité.
- Des recommandations liées aux performances, pour optimiser les performances des applications.
Actuellement, ces deux types de recommandations sont générées pour trois périodes : 24 heures, 7 jours et 15 jours d'observation.
L'optimisation des ressources selon les recommandations d'OpenShift générées par la fonction de gestion des coûts de Red Hat Insights vous permet de réaliser des économies et d'optimiser les performances de vos applications. Vous pouvez consulter ces recommandations en contexte, ainsi que les coûts associés aux charges de travail.
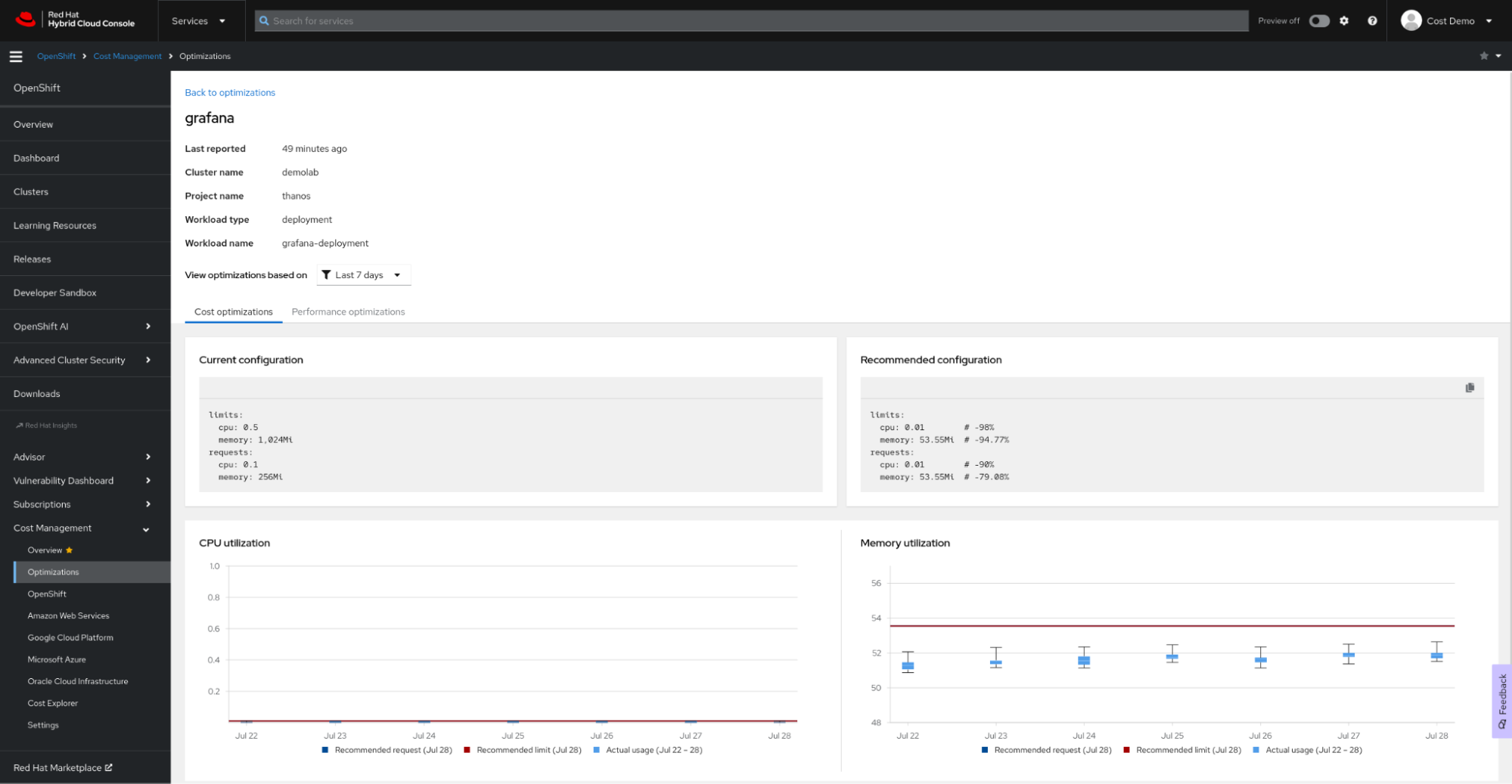
Configuration
L'optimisation des ressources pour OpenShift est une fonction supplémentaire du service de gestion des coûts de Red Hat Insights. Suivez le guide de référence du service de gestion des coûts de Red Hat Insights pour configurer la fonction, et utilisez notre API Cost Management pour créer votre propre tableau de bord dans l'outil d'informatique décisionnelle ou de visualisation de votre choix, tel que Microsoft Excel, Power BI ou Grafana. Pas besoin de configuration complexe ni d'allocation de ressources coûteuses pour le traitement : l'opérateur Cost Management Metrics Operator enverra vos données d'utilisation à l'interface Red Hat Hybrid Cloud Console à des fins d'analyse et vous fournira des informations sur les coûts et les ressources. Si vos clusters ne sont pas connectés à Internet, consultez la documentation sur le mode déconnecté.
À propos des auteurs


Vanessa is a Senior Product Manager in the Observability group at Red Hat, focusing on both OpenShift Analytics and Observability UI. She is particularly interested in turning observability signals into answers. She loves to combine her passions: data and languages.

Pau Garcia Quiles joined Red Hat in 2021 as Principal Product Manager. He has 20 years of experience in IT in various roles, both as a vendor and as a customer, systems administrator, software developer and project manager. He has been involved in open source for more than 15 years, most notably as a Debian maintainer, KDE developer and Uyuni developer.
Parcourir par canal

Automatisation
Les dernières nouveautés en matière d'automatisation informatique pour les technologies, les équipes et les environnements

Intelligence artificielle
Actualité sur les plateformes qui permettent aux clients d'exécuter des charges de travail d'IA sur tout type d'environnement

Cloud hybride ouvert
Découvrez comment créer un avenir flexible grâce au cloud hybride

Sécurité
Les dernières actualités sur la façon dont nous réduisons les risques dans tous les environnements et technologies

Edge computing
Actualité sur les plateformes qui simplifient les opérations en périphérie

Infrastructure
Les dernières nouveautés sur la plateforme Linux d'entreprise leader au monde

Applications
À l’intérieur de nos solutions aux défis d’application les plus difficiles
Virtualisation
L'avenir de la virtualisation d'entreprise pour vos charges de travail sur site ou sur le cloud