先進的な IT 運用の領域において最も重要なのは、可観測性ツールと自動化の統合です。これによって可視性と効率の共存関係が促進されるからです。可観測性ツールは、複雑なシステムのパフォーマンス、健全性、動作に関する詳細な知見を提供してくれるため、組織は問題が拡大する前にプロアクティブに特定して修正できるようになります。
これらのツールを自動化フレームワークとシームレスに統合することで、企業は動的な変化をリアルタイムで監視するだけでなく、リアルタイムに対応することもできます。この可観測性と自動化の相乗効果により、IT チームは進化する状況に迅速に適応し、ダウンタイムを最小限に抑え、リソース使用率を最適化できます。また、可観測性データに基づいて応答を自動化することで、組織はアジリティを高め、手作業による介入を減らし、堅牢で回復力のあるインフラストラクチャを維持できます。要するに、最新のテクノロジーを取り巻くペースの速い、複雑な状況において、プロアクティブで応答性が高く、最適化された運用環境を実現するには、可観測性と自動化を活用することが不可欠なのです。
このブログ記事では、ベアメタルと仮想マシンの両方でプロセスを監視する一般的なユースケースを取り上げます。ここでは Dynatrace OneAgent の使用に焦点を当てます。これは、ホスト上にデプロイされるバイナリーファイルであり、環境の監視に特化され、 綿密に設定された一連のサービスが含まれています。これらのサービスは Telemetry メトリクスを能動的に収集し、ハードウェア、オペレーティングシステム、アプリケーションプロセスなど、ホストのさまざまな側面に関する知見を取得します。
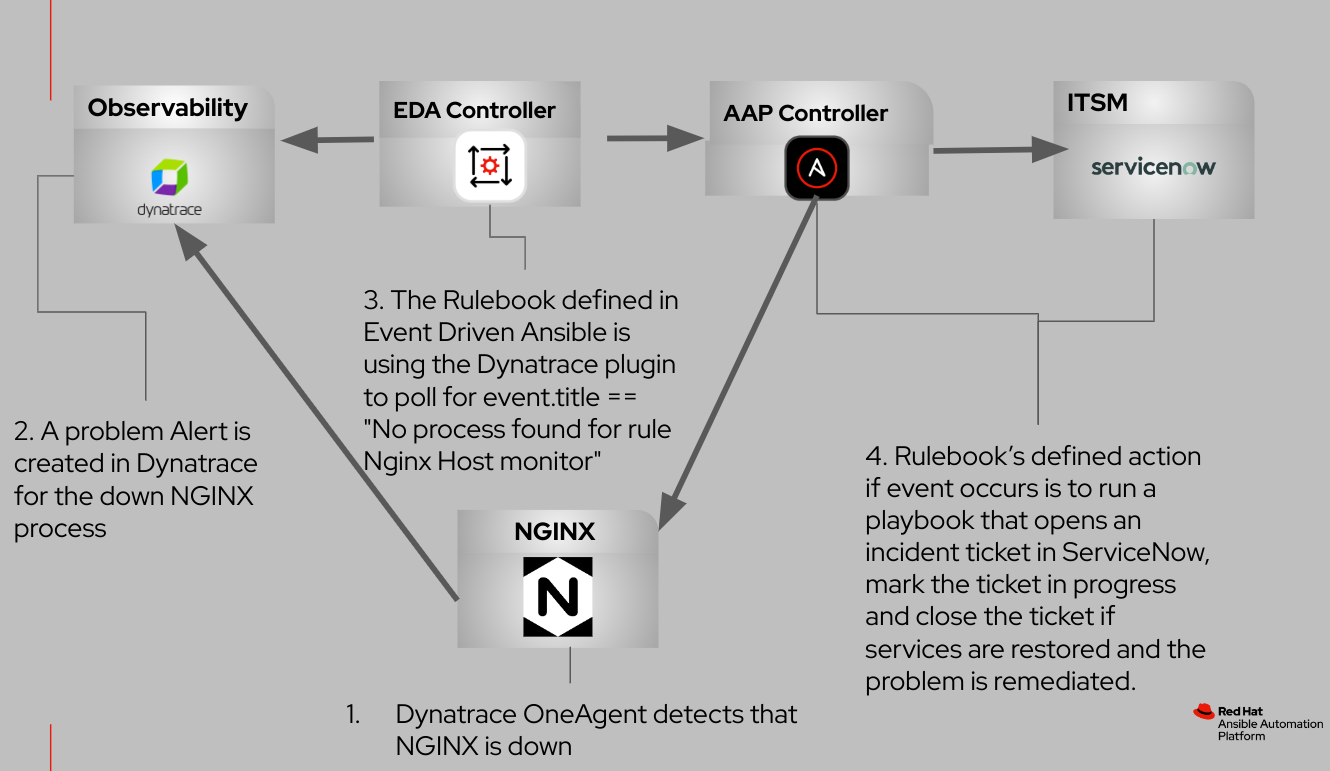
今回のユースケースにおける目的は、NGINX Web サーバープロセス専用のホストレベルの監視を確立することです。ここでは Event-Driven Ansible の実装について説明します。これは、定義済みのルールによってイベントソースと対応するアクションをリンクさせるフレームワークです。このインスタンスでは、イベントソースは Dynatrace です。
設定が完了したら、次のシナリオをシミュレーションします。
- NGINX Web サーバーで予定外のダウンタイムが発生した場合。
- Dynatrace OneAgent が管理するプロセスモニターが、失敗した NGINX プロセスを即座に検出し、Dynatrace プラットフォームに問題のアラートを生成した場合。
- Dynatrace ソースプラグインが、Event-Driven Ansible が採用するルールブックで定義されているとおりに、障害イベントをアクティブにポーリングした場合。
- Event-Driven Ansible がイベントに応答して、次のアクションを担うジョブテンプレートを実行した場合。
- ServiceNow インシデントチケットの作成を開始。
- NGINX プロセスの再起動を試行。
- インシデントチケットのステータスを「進行中」に更新。
- NGINX プロセスが正常に復元された場合にのみ、チケットをクローズ。
以下のフローチャートは、これらの統合コンポーネント間のやり取りを示しています。
それでは、開始する前に Event-Driven Ansible のコアコンセプトに関するいくつかの用語を確認しましょう。
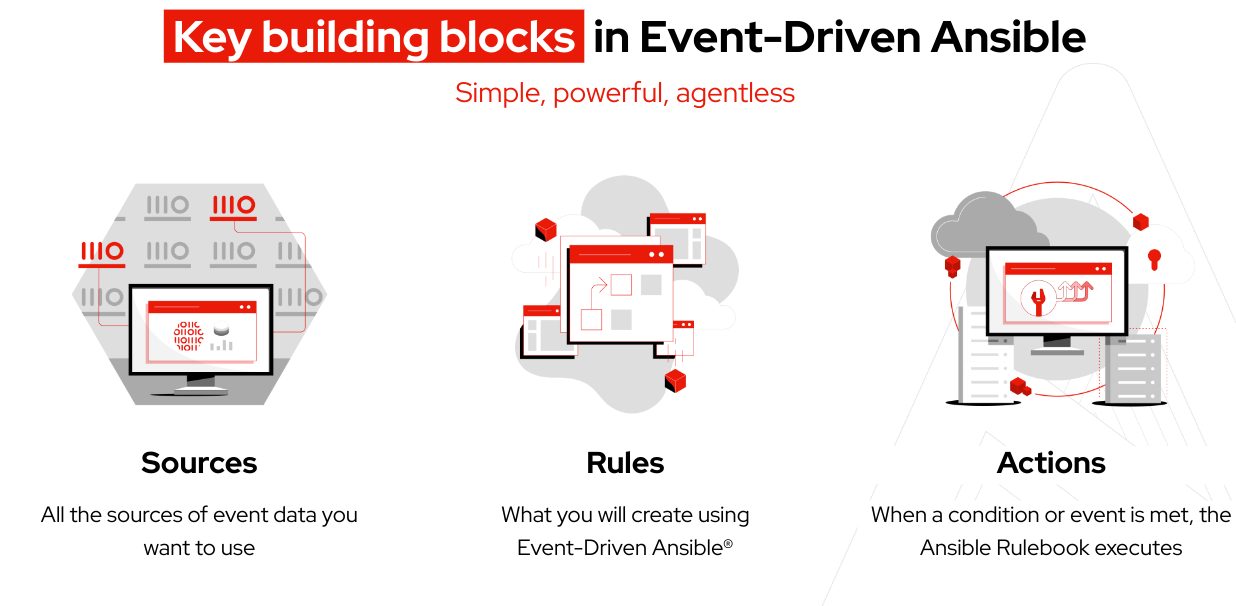
用語:
Ansible Rulebook には、イベントソースと、特定の条件が満たされたときに実行するアクションに関するルールベースの詳細な指示の両方が含まれており、高い柔軟性を提供します。
決定環境は、Event-Driven Ansible コントローラーで使用される Ansible Rulebook を実行するために作成されたコンテナイメージです。
イベントソースプラグインは、一般的に Python で構築され、指定したイベントソースからのイベントの収集に対応します。また、プラグインは Red Hat Ansible Certified Content Collection を通じて配布されます。
決定のための環境を構築する必要があります。 以下のビルドファイルの例を参照してください。
---
version: 3
images:
base_image:
name: registry.redhat.io/ansible-automation-platform-24/de-minimal-rhel8:latest
dependencies:
galaxy:
collections:
- ansible.eda
- dynatrace.event_driven_ansible
system:
- pkgconf-pkg-config [platform:rpm]
- systemd-devel [platform:rpm]
- gcc [platform:rpm]
- python39-devel [platform:rpm]
options:
package_manager_path: /usr/bin/microdnf決定環境の構築に関する追加のガイダンスについては、提供されているドキュメントを参照してください。決定環境を作成した後、指定したイメージリポジトリにコンテナイメージをプッシュし、次にそのイメージを Event-Driven Ansible コントローラーにプルします。
決定環境を確立したので、次は Event-Driven Ansible コントローラーでルールアクティベーションを作成します。このアクティベーションによってルールブックがカプセル化され、イベントソースが定義されるとともに、特定の条件下で実行されるアクションに関する詳細な指示が定義されます。Automation Controller のプロジェクト内での Playbook の編成と同様に、Event-Driven Ansible コントローラーはプロジェクトを使用してルールブックを管理し、格納します。
以下は、Git リポジトリでルールブックと Playbook を整理し、保存するための標準的なディレクトリ階層です。
Event-Driven Ansible コントローラーでプロジェクトを作成したら、ルールブックのアクティベーションを作成する必要があります。これは、決定環境で実行されるルールブックによって定義されたバックグラウンドプロセスです。
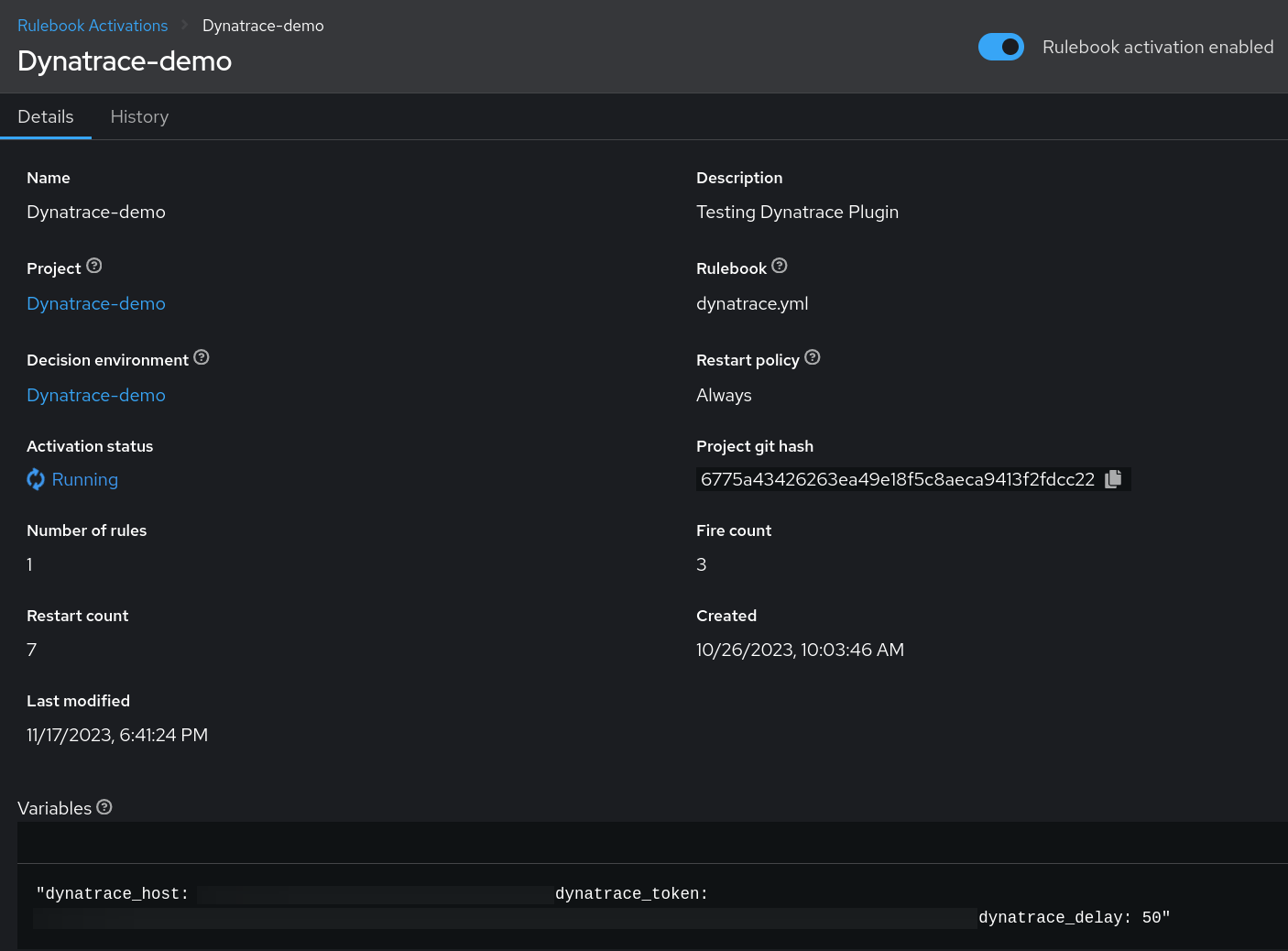
このユースケースでは、Ansible イベントソースとして Dynatrace プラグインを使用するルールブックを作成し、条件を満たしたときに実行したい動作を指定します。
一般的に、ソースプラグインには 3 つの統合パターンがあります。
- ポーリング
- Webhook
- メッセージング
このユースケースのコンテキストでは、Dynatrace ソースプラグインはルールブックで説明されている指定条件に従ってアクティブにポーリングすることで、イベントを効率的に取得します。このポーリング・メカニズムは、ルールブックで説明されているように、Dynatrace プラグインに固有の delay 変数を導入します (delay 変数の設定を参照してください)。
この delay 変数は、スロットリングメカニズムを実装することにより、プラグインの動作の調整に重要な役割を果たします。これは基本的に、事前定義された間隔での API 呼び出しの実行をオーケストレーションし、受信した応答に基づいてプラグインが新しいイベントを生成できるようにします。このように API 呼び出しのペースを意図的に調整することは、ワークフロー全体の管理と最適化に役立ち、レート制限に関連するリスクを軽減して、システムがシームレスに運用されるようになります。
以下のルールブックを参照してください。
---
- name: Watching for Problems on Dynatrace
hosts: all
sources:
- dynatrace.event_driven_ansible.dt_esa_api:
dt_api_host: "{{ dynatrace_host }}"
dt_api_token: "{{ dynatrace_token }}"
delay: "{{ dynatrace_delay }}"
rules:
- name: Look for open Process monitor problem
condition: event.title == "No process found for rule Nginx Host monitor"
action:
run_job_template:
name: Fix Nginx and update all
organization: "Default"
job_args:
extra_vars:
problemID: "{{ event.displayId }}"
reporting_host: "{{ event.impactedEntities[0].name }}"注:Red Hat は、このコードの正確性について、いかなる明示的なサポートも行っていません。特に指定がない限り、すべてのコンテンツはサポートされていないものとみなされます。
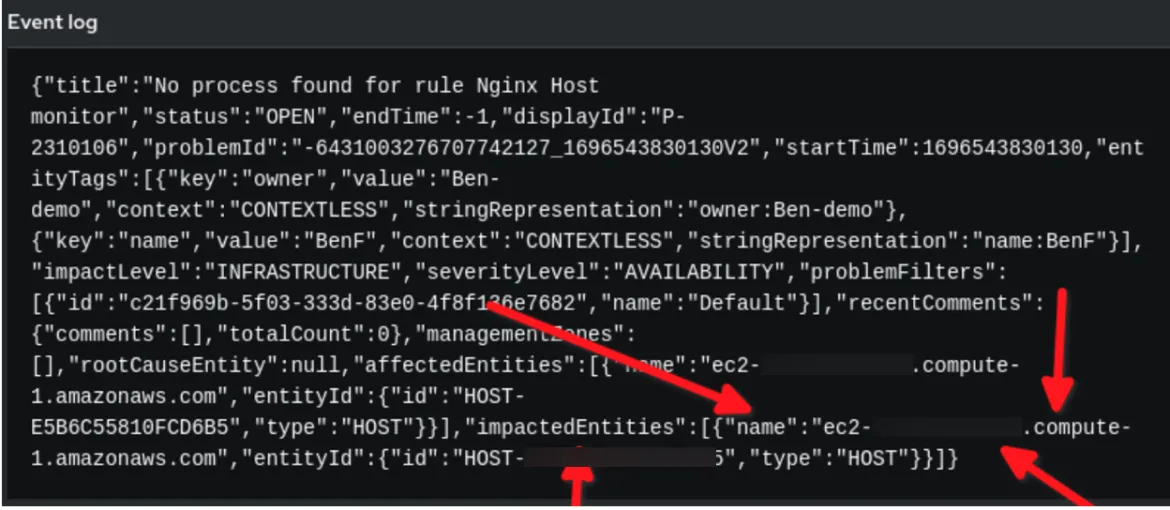
上記のルールブックでは、注意を要する 2 つのキーが YAML にあります。1 つは、rules セクションの condition キーです。event.title が「No process found for rule Nginx Host monitor」となっていることに注目してください。この文字列はどのようにして得たのでしょうか。
次に、Automation Controller で実行されるジョブテンプレートを呼び出す action セクションの report_host 変数を確認します。どのようにして event.impactedEntities[0].name となったのでしょうか。
ここでは、Red Hat のイベント駆動型自動化プロセスにおけるこれらのキーの定義と使用法について説明します。
Dynatrace OneAgent をターゲットホストにインストールした後、アクセストークンを作成する必要があります。トークンが次のパーミッションを持つようにします。
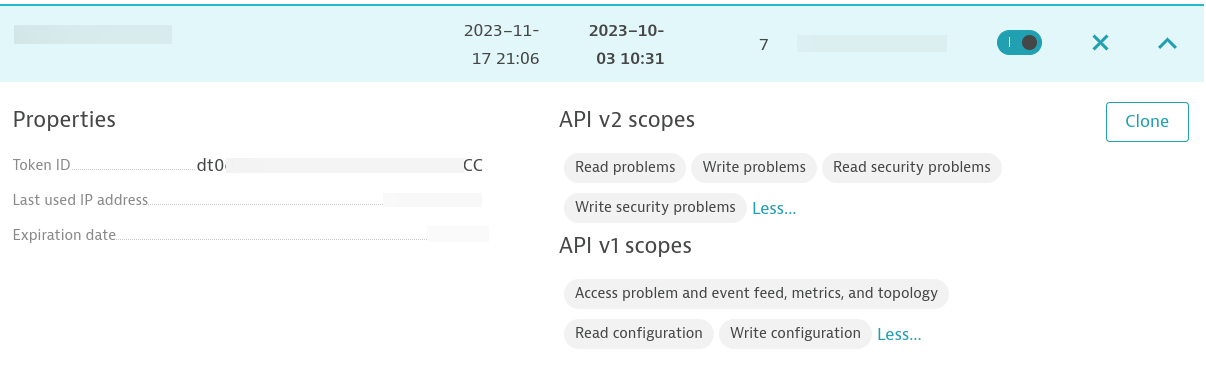
NGINX プロセス用にホストレベルのプロセス可用性の監視ルールを設定する必要があります。NGINX を実行するホスト名が、Automation Controller 内のインベントリーで指定されたホスト名と一致していることを確認します。
モニターの設定が完了したら、管理ホスト上の NGINX プロセスを強制終了することで、Event-Driven Ansible のルールブックのアクティベーションによってポーリングされるペイロードをテストできます。
ルール監査の例をご覧ください。ペイロードが Event-Driven Ansible でどのように表示されるかがわかります。
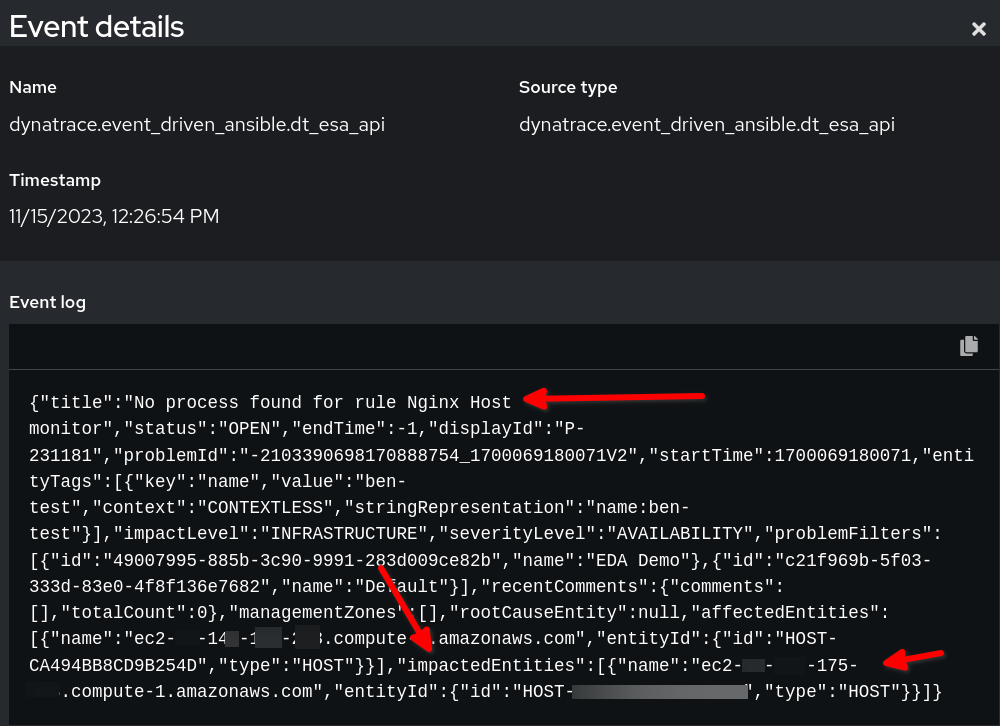
上記の例では、Dynatrace のペイロード・イベントデータが JSON 形式であることがわかります。event.title に設定された文字列を条件に使用します。report_host 変数は、event.impactedEntities[0].name 値によって動的に設定されます。impactedEntities.name[0].name は複数のホストになる可能性があります。
condition キーの値と reporting_host 変数がどのように設定されるかがわかったところで、次は何をすればよいでしょうか。
これは、Automation Controller での実行を目的とした Playbook をジョブテンプレートとして評価する良い機会となります。この Playbook は、イベントペイロード (Event-Driven Ansible によってトリガーされ、NGINX プロセスの停止が報告される) が Dynatrace によって検出された場合に使用されます。
---
- name: Restore nginx service create, update and close ServiceNow ticket after Ansible restores services
hosts: "{{ reporting_host }}"
gather_facts: false
become: true
vars:
incident_description: Nginx Web Server is down
sn_impact: medium
sn_urgency: medium
tasks:
- name: Create an incident in ServiceNow
servicenow.itsm.incident:
state: new
description: " Dynatrace reported {{ problemID }}"
short_description: "Nginx is down per {{ problemID }} on {{ reporting_host }} reported by Dynatrace nginix monitor."
caller: admin
urgency: "{{ sn_urgency }}"
impact: "{{ sn_impact }}"
register: new_incident
delegate_to: localhost
- name: Display incident number
ansible.builtin.debug:
var: new_incident.record.number
- name: Pass incident number
ansible.builtin.set_fact:
ticket_number: "{{ new_incident.record.number }}"
- name: Try to restart nginx
ansible.builtin.service:
name: nginx
state: restarted
register: chksrvc
- name: Update incident in ServiceNow
servicenow.itsm.incident:
state: in_progress
number: "{{ ticket_number }}"
other:
comments: "Ansible automation is working on {{ problemID }}. on host {{ reporting_host }}"
delegate_to: localhost
- name: Validate service is up and update/close SNOW ticket
block:
- name: Close incident in ServiceNow
servicenow.itsm.incident:
state: closed
number: "{{ ticket_number }}"
close_code: "Solved (Permanently)"
close_notes: "Go back to bed. Ansible fixed problem {{ problemID }} on host {{ reporting_host }} reported by Dynatrace."
delegate_to: localhost
when: chksrvc.state == "started"「Red Hat は、このコードの正確性について、いかなる明示的なサポートも行っていません。特に指定がない限り、すべてのコンテンツはサポートされていないものとみなされます」
Automation Controller で確立されるジョブテンプレートの名前、ルールブックの run_job_template セクションで指定される名前と一致する必要があります。このユースケース例では、ジョブテンプレート内に survey を組み込み、ルールブックから渡される problemID および porting_host 変数の起動時にプロンプトを表示できるようにしました。
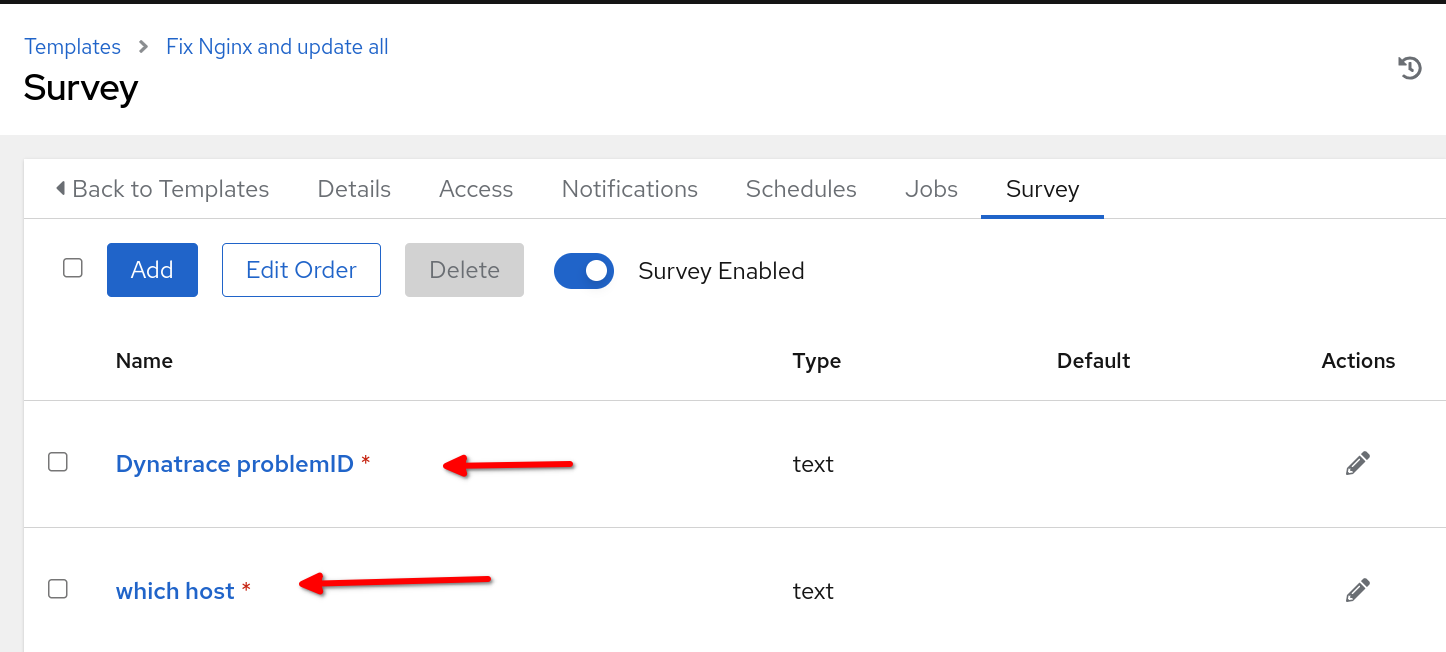


このユースケースを機能させるには、Automation Controller を ServiceNow と統合し、また、ジョブテンプレートで使用するために Automation Controller で構成される ITSM ServiceNow コレクションを備えた自動化実行環境を用意する必要があります。さらに、修正 Playbook を格納する Automation Controller でプロジェクトを作成し、NGINX Web サーバーをホストするホスト名が Automation Controller のインベントリーに含まれていることを確認します。最後に、Event-Driven Ansible コントローラーが Automation Controller と正常に統合されていることを確認します。
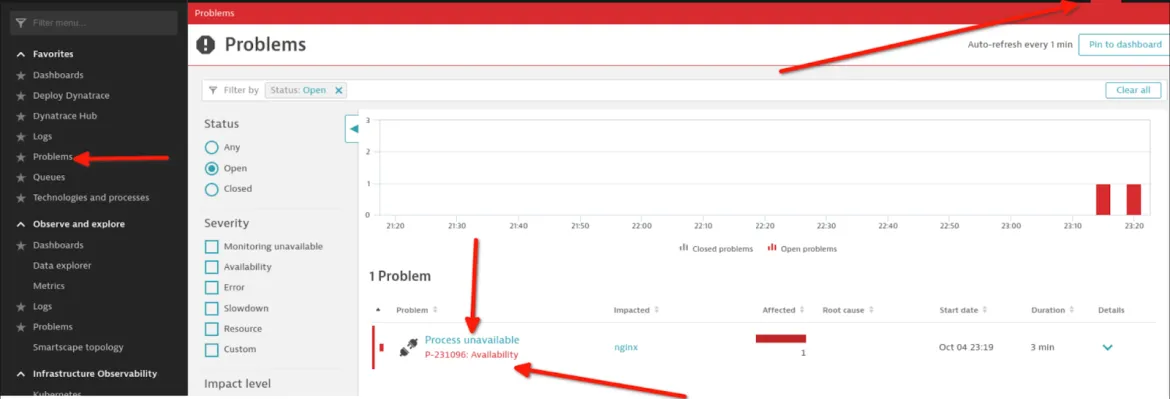
これですべてが適切に設定されたので、ホストで NGINX プロセスを強制終了してテストし、次の内容を確認します。
Dynatrace で生成されたアラート:
Event-Driven Ansible のルール監査イベント:
修正ジョブテンプレートが Automation Controller で実行されるジョブイベント

Dynatrace によって報告された問題ホストで NGINX プロセスが復元されると、インシデントチケットが作成され、更新され、クローズされます。





このユースケース例では、 Dynatrace プラグインと決定環境を導入し、ソースからのペイロードイベントのサンプルデータを調べて、変数を動的に入力する方法を示しました。Dynatrace に NGINX プロセスのホストレベルのプロセスモニターを実装しましたが、アプリケーションレベルの監視に Dynatrace の合成モニターを採用することも可能です。
Red Hat の修復 Playbook は、適応性の重要性を重視し、動的性を維持しているため、Dynatrace によって問題があると報告されたホストでのみ実行されるようにスコープ指定されています。この例では幅広いトピックを取り上げていますが、複雑なタスクを自動化するために最初から包括的なアプローチが必要な訳ではないことを理解する必要があります。むしろ、修正を自動化する方法を学習する過程で、修正タスクを Playbook に徐々に統合していくことを検討することをお勧めします。まずは、修正アクションを実装する前にインシデントチケットを提出することを選択し、徐々に一般的な問題の自動化を実行していくことができます。標準的なアジャイルの原則を自動化プロセスに適用すると、反復的で柔軟なアプローチが可能になります。午前 3 時に一般的な問題に手動で対処していた時代は過去のものとなっています。エンタープライズレベルの効果的な自動化を実装することで、睡眠を取り戻す機会ともなっています。
ハッピー・オートメーティング! (自動化で毎日を快適にしましょう!)
その他の資料と次のステップ
Event-Driven Ansible の詳細については以下をご覧ください。
執筆者紹介

チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細
仮想化
オンプレミスまたは複数クラウドでのワークロードに対応するエンタープライズ仮想化の将来についてご覧ください