Integrar ferramentas de observabilidade com a automação é fundamental nas operações de TI modernas, pois promove uma relação simbiótica entre visibilidade e eficiência. As ferramentas de observabilidade oferecem insights detalhados sobre o desempenho, a integridade e o comportamento de sistemas complexos, permitindo que as organizações sejam proativas na identificação e correção dos problemas, antes que eles se agravem.
Quando integradas fluidamente a frameworks de automação, essas ferramentas dão às empresas a capacidade de não apenas monitorar, mas também responder a mudanças dinâmicas em tempo real. Essa sinergia entre observabilidade e automação permite que equipes de TI se adaptem rápido às mudanças nas condições, minimizem o downtime e otimizem a utilização de recursos. Ao automatizar as respostas com base nos dados da observabilidade, as organizações podem ser mais ágeis, reduzir a intervenção manual e manter uma infraestrutura robusta e resiliente. Em síntese, usar observabilidade com automação é indispensável para ter um ambiente operacional proativo, responsivo e simplificado no cenário tecnológico complexo e acelerado de hoje.
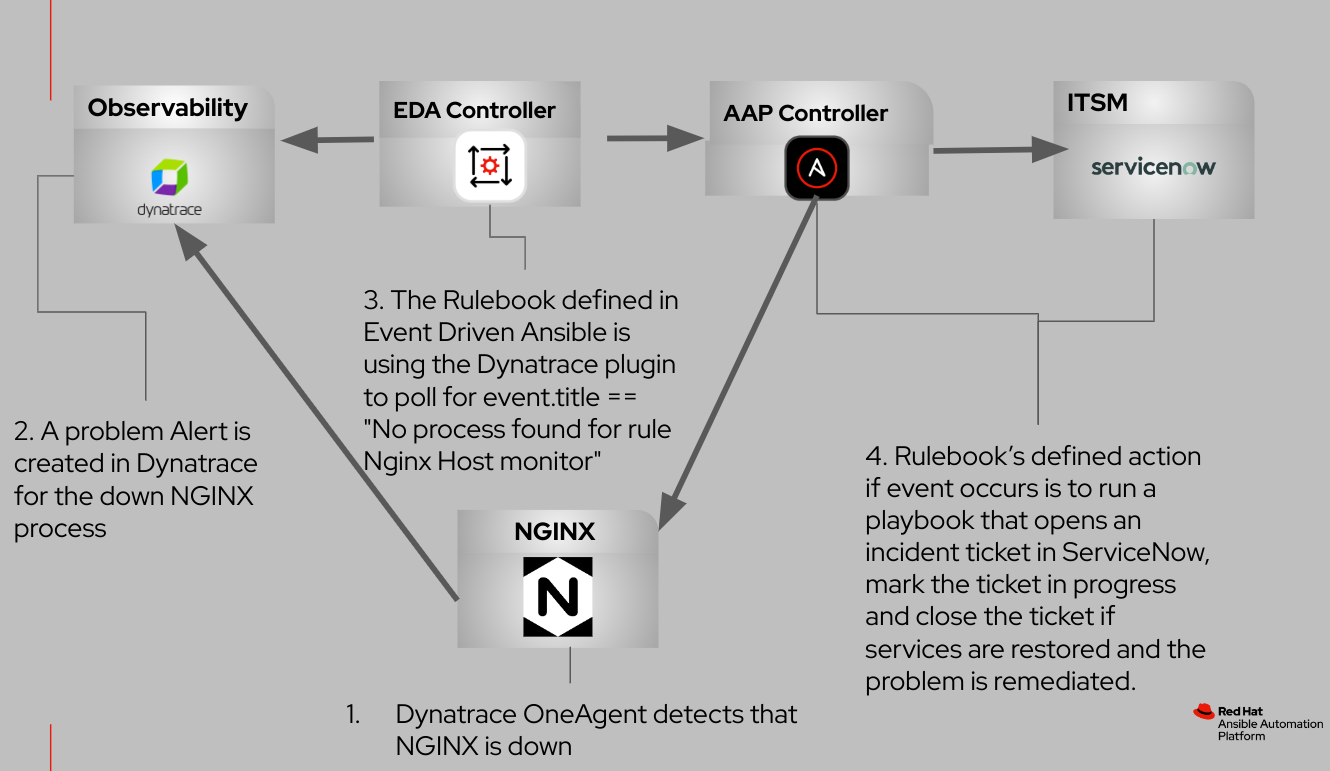
Neste post, analisaremos um caso de uso comum envolvendo o monitoramento de processos em máquinas virtuais e bare metal. Nossa exploração terá como foco a utilização do OneAgent da Dynatrace, um arquivo binário implantado em hosts que abrange um conjunto de serviços especializados, configurados com precisão para o monitoramento de ambientes. Esses serviços coletam ativamente métricas de telemetria, capturando insights sobre várias facetas dos hosts, incluindo hardware, sistemas operacionais e processos de aplicações.
Neste caso de uso, nosso objetivo é estabelecer um monitoramento no nível do host, em específico para o processo do servidor web NGINX. Guiarei você na implementação do Event-Driven Ansible, um framework que vincula fontes de eventos a ações correspondentes usando regras definidas. Desta vez, a fonte de eventos é a Dynatrace.
Quando a configuração for concluída, simularemos o seguinte cenário:
- As experiências do servidor web NGINX passam por um downtime não planejado.
- O monitor de processos, facilitado pelo Dynatrace OneAgent, detecta de imediato o processo NGINX que falhou e gera um alerta de problema na plataforma da Dynatrace.
- O plugin de fonte da Dynatrace, conforme definido no rulebook usado pelo Event-Driven Ansible, pesquisa ativamente eventos de falha.
- Em resposta ao evento, o Event-Driven Ansible executa um template de tarefa que realiza as seguintes ações:
- Inicia a criação de um ticket de incidente do ServiceNow.
- Tenta reiniciar o processo NGINX.
- Atualiza o status do ticket de incidente para "Em andamento".
- Encerra o ticket somente se o processo NGINX for restaurado com sucesso.
O fluxograma abaixo ilustra as interações entre esses componentes integrados.
Antes de começar, vamos nos familiarizar com algumas terminologias que coincidem com os principais conceitos do Event-Driven Ansible:
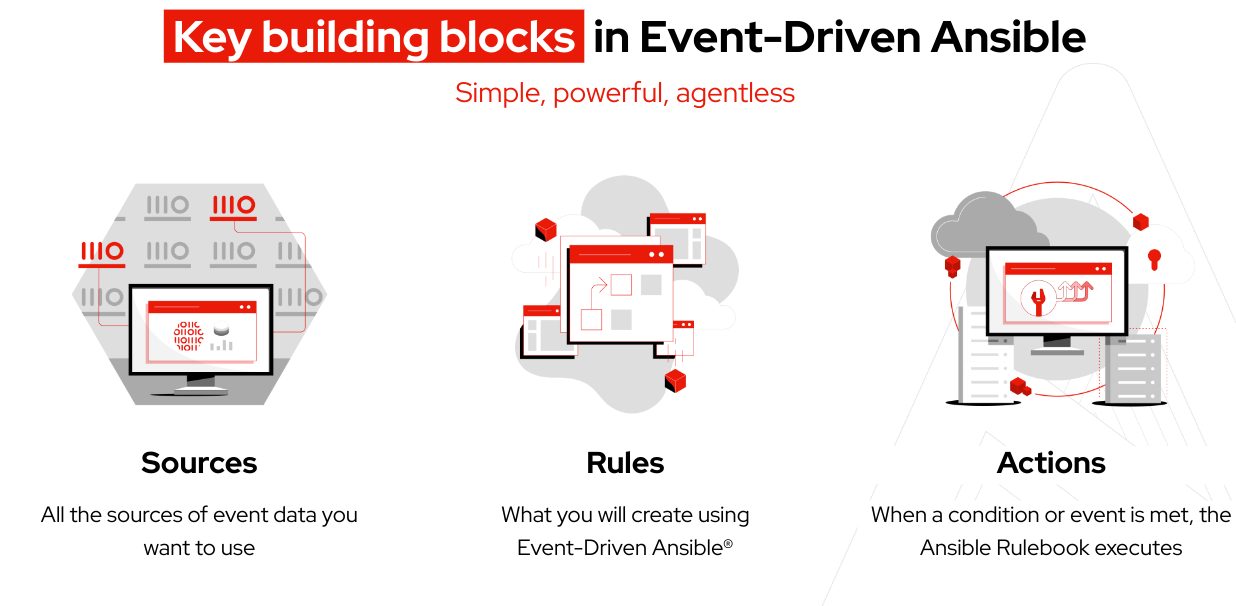
Terminologia:
O Ansible Rulebook inclui a fonte de eventos e as instruções detalhadas baseadas em regras sobre as ações a serem executadas quando condições específicas são atendidas, oferecendo um alto grau de flexibilidade.
Um ambiente de decisão é uma imagem de container criada para executar Ansible Rulebooks usados no controlador do Event-Driven Ansible.
Os plugins de fonte de eventos, em via de regra, são construídos em Python e têm o objetivo de reunir eventos da fonte especificada. Além disso, os plugins são distribuídos pelos Red Hat Ansible Certified Content Collections.
Será necessário criar um ambiente de decisão. Confira abaixo o exemplo do arquivo criado:
---
version: 3
images:
base_image:
name: registry.redhat.io/ansible-automation-platform-24/de-minimal-rhel8:latest
dependencies:
galaxy:
collections:
- ansible.eda
- dynatrace.event_driven_ansible
system:
- pkgconf-pkg-config [platform:rpm]
- systemd-devel [platform:rpm]
- gcc [platform:rpm]
- python39-devel [platform:rpm]
options:
package_manager_path: /usr/bin/microdnfConsulte a documentação disponibilizada para mais orientações sobre a construção de ambientes de decisão. Após a criação do ambiente de decisão, envie a imagem de container para o repositório de imagens designado. Depois, extraia a imagem no controlador do Event-Driven Ansible.
Com a formação do ambiente de decisão, você está prestes a criar uma ativação de regras no controlador do Event-Driven Ansible. Essa ativação encapsulará o rulebook, definindo a fonte dos eventos com instruções detalhadas sobre as ações a serem executadas em condições específicas. Semelhante à organização de playbooks em projetos no automation controller, o controlador do Event-Driven Ansible usa projetos para gerenciar e guardar os rulebooks.
Abaixo, há uma hierarquia de diretórios padrão para organizar e armazenar rulebooks e playbooks no repositório git.
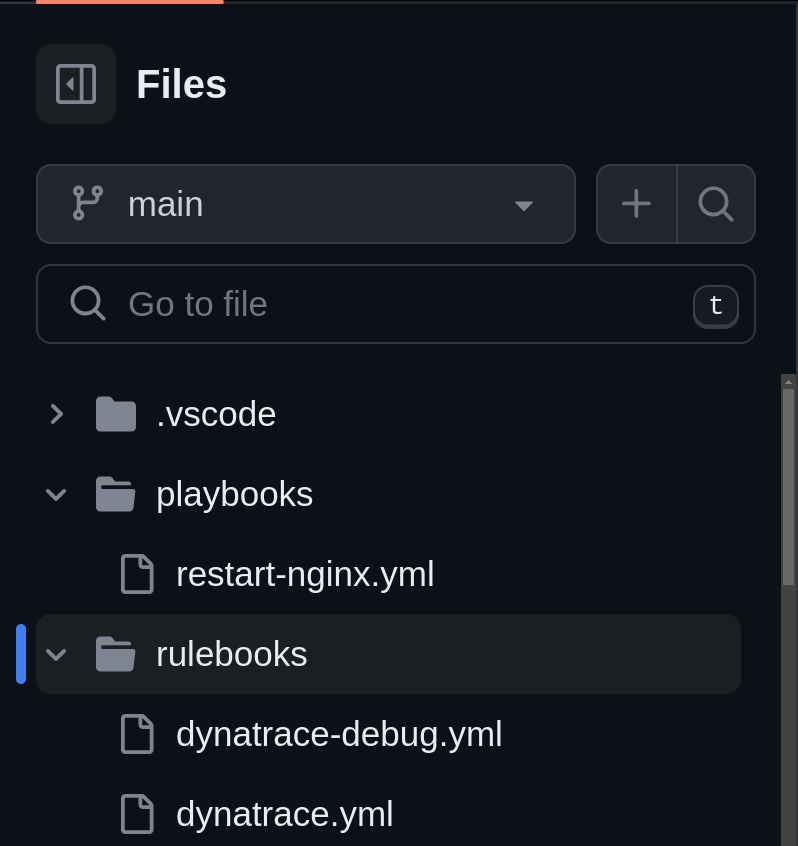
Após criar um projeto no controlador do Event-Driven Ansible, precisaremos criar uma ativação de rulebook, o qual é um processo em segundo plano definido por um rulebook em execução em um ambiente de decisão.
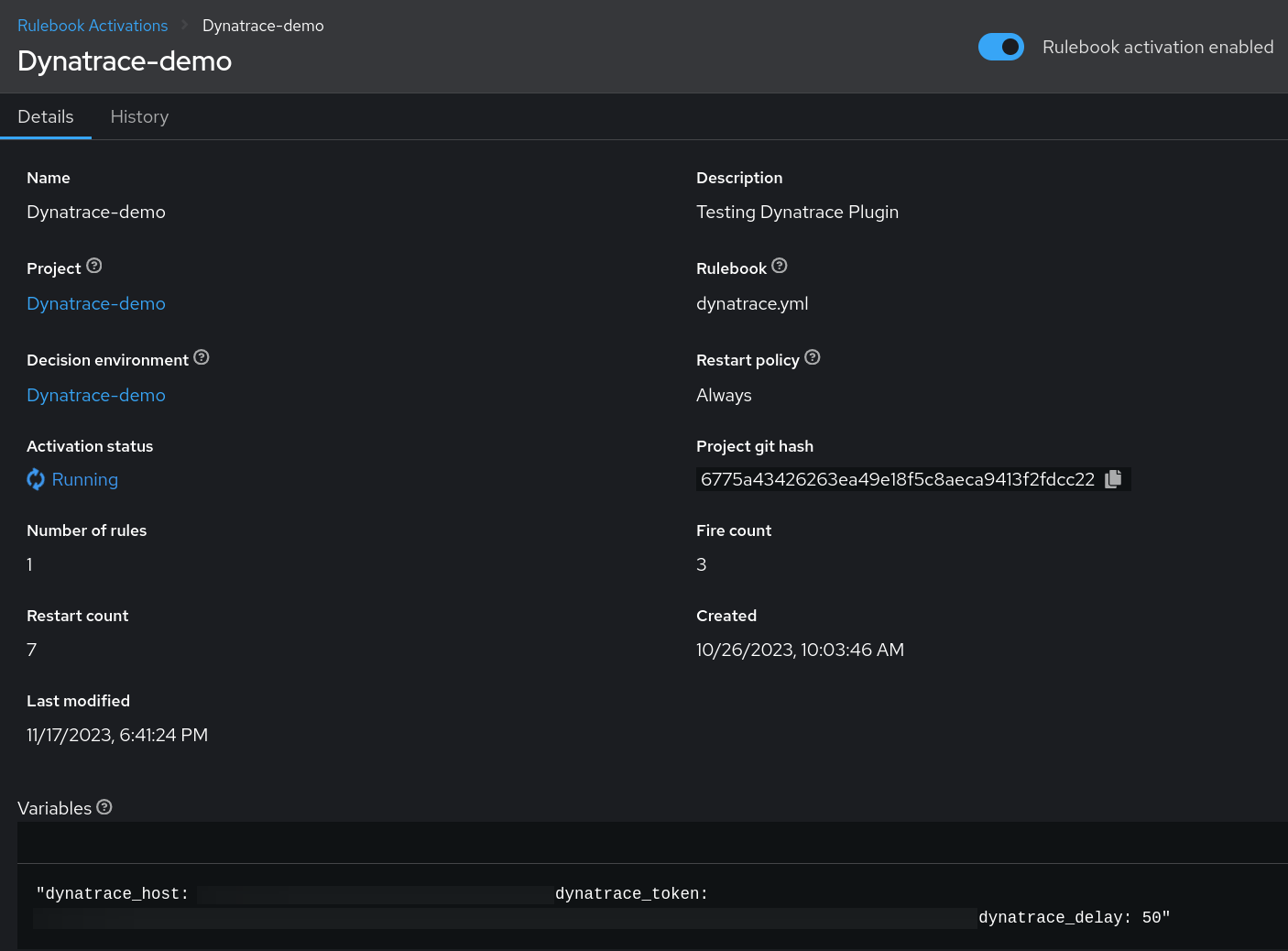
Para este caso de uso, criaremos um rulebook que usa o plugin da Dynatrace como fonte de eventos do Ansible e especificaremos o que queremos que seja feito quando uma condição for atendida.
Em geral, há três padrões de integração para plugins de fonte:
- Pesquisa
- Webhook
- Mensagem
No contexto do nosso caso de uso, o plugin de fonte da Dynatrace recupera eventos com eficiência ao pesquisar ativamente conforme as condições especificadas descritas no rulebook. Esse mecanismo de pesquisa introduz uma variável delay inerente ao plugin da Dynatrace, conforme descrito no rulebook (consulte a configuração da variável delay).
Esse atraso desempenha um papel crucial na regulação do comportamento do plugin, implementando um mecanismo de limitação. Em resumo, ele orquestra a execução de chamadas de API em intervalos predefinidos, permitindo que o plugin gere um novo evento com base na resposta recebida. Esse ritmo intencional das chamadas de API é fundamental para gerenciar e otimizar o fluxo de trabalho geral, mitigando o risco de encontrar limites de taxa e garantindo que o sistema opere de forma fluida.
Confira o rulebook abaixo:
---
- name: Watching for Problems on Dynatrace
hosts: all
sources:
- dynatrace.event_driven_ansible.dt_esa_api:
dt_api_host: "{{ dynatrace_host }}"
dt_api_token: "{{ dynatrace_token }}"
delay: "{{ dynatrace_delay }}"
rules:
- name: Look for open Process monitor problem
condition: event.title == "No process found for rule Nginx Host monitor"
action:
run_job_template:
name: Fix Nginx and update all
organization: "Default"
job_args:
extra_vars:
problemID: "{{ event.displayId }}"
reporting_host: "{{ event.impactedEntities[0].name }}"Observação: a Red Hat não garante a exatidão desse código. Todo o conteúdo é considerado sem suporte, a menos que especificado de outra forma.
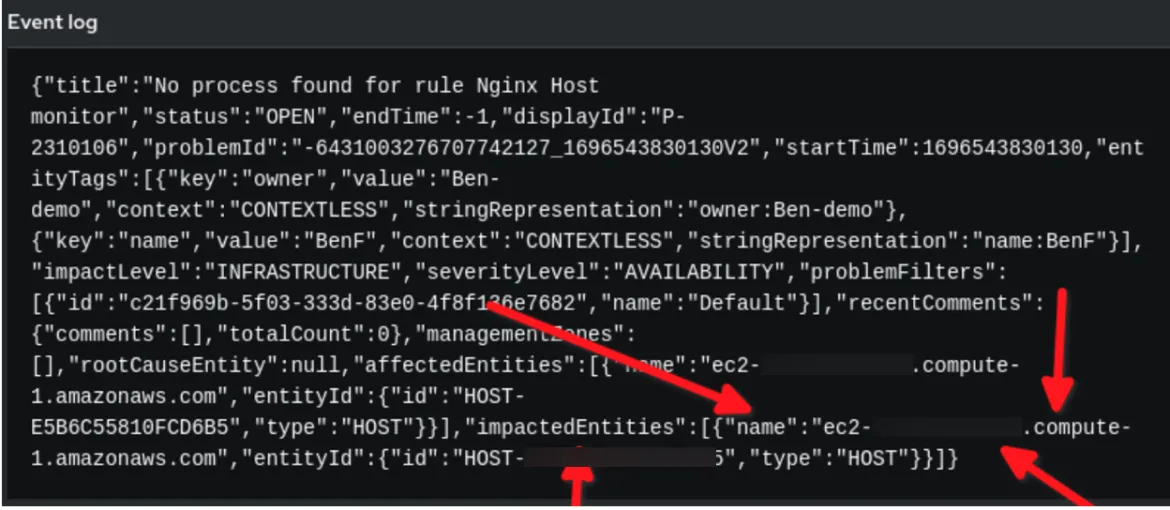
No rulebook acima, há duas chaves no YAML que exigem atenção. A primeira é a chave condition na seção "rules". Observe que event.title é igual a "No process found for rule Nginx Host monitor". Mas de onde tirei essa sequência de caracteres?
Em segundo lugar, observe a variável reporting_host na seção "action", em que chamamos o template da tarefa a ser executada no automation controller. De onde saiu event.impactedEntities[0].name?
Neste post, ainda vamos nos aprofundar para descobrir a definição e a utilização dessas chaves em nossos processos de automação orientados a eventos.
Após instalar o Dynatrace OneAgent no host de destino, você precisará criar um token de acesso. O token precisa ter as seguintes permissões:
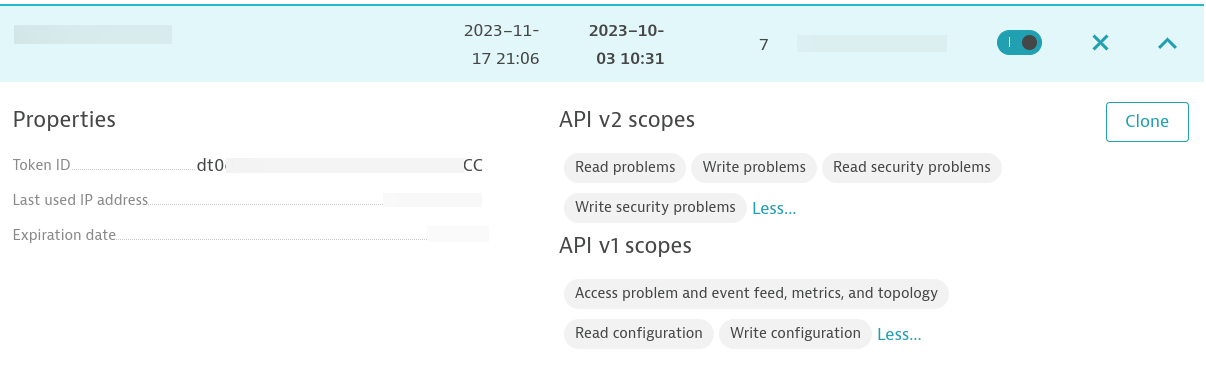
Você precisará configurar uma regra de monitoramento de disponibilidade de processo no nível do host para o processo NGINX. O nome do host que executa o NGINX deve estar alinhado ao nome do host especificado no seu inventário no automation controller.
Após configurar o monitor, você pode testar o payload pesquisado pela ativação do rulebook no Event-Driven Ansible encerrando o processo NGINX no seu host gerenciado.
Confira no exemplo de auditoria de regra como deverá ser o payload no Event-Driven Ansible:
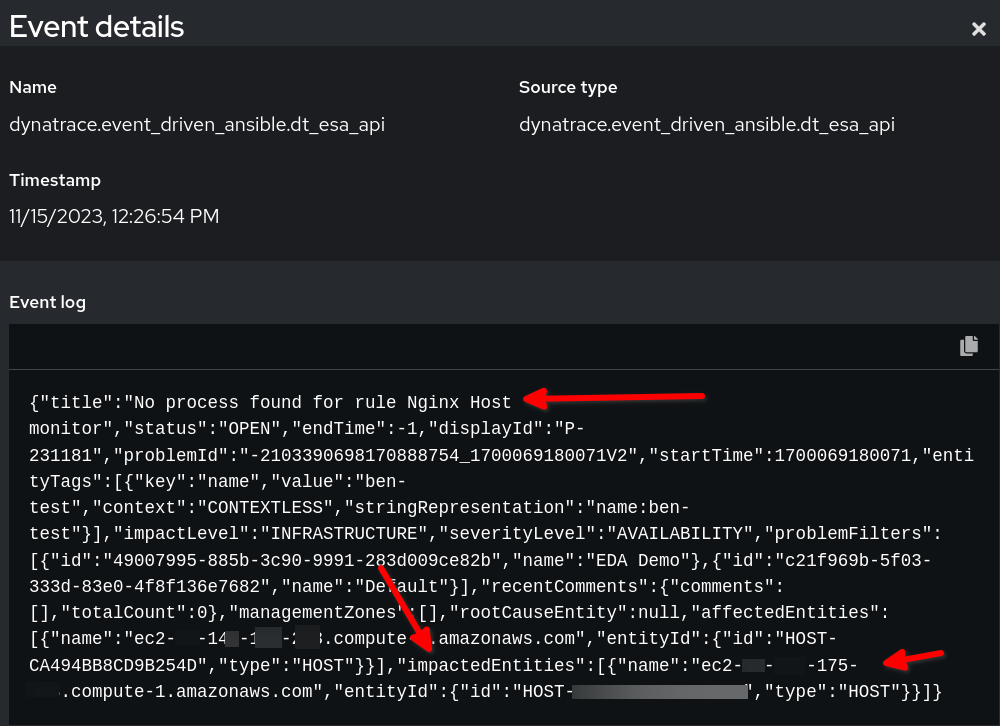
No exemplo acima, podemos perceber que os dados do evento de payload da Dynatrace estão no formato JSON. Usamos a sequência de caracteres definida em event.title como a condição e a variável reporting_host é definida dinamicamente pelo valor event.impactedEntities[0].name. Observe que impactedEntities.name[0].name poderia ser mais de um host.
Agora que sabemos como o valor da chave condition e das variáveis reporting_host são definidos, quais são as próximas etapas?
Este é um momento oportuno para avaliar o playbook destinado à execução no automation controller como um template de tarefa. Esse playbook é usado quando o payload do evento, acionado pelo Event-Driven Ansible que informa a inatividade do processo NGINX, é detectado pela Dynatrace:
---
- name: Restore nginx service create, update and close ServiceNow ticket after Ansible restores services
hosts: "{{ reporting_host }}"
gather_facts: false
become: true
vars:
incident_description: Nginx Web Server is down
sn_impact: medium
sn_urgency: medium
tasks:
- name: Create an incident in ServiceNow
servicenow.itsm.incident:
state: new
description: " Dynatrace reported {{ problemID }}"
short_description: "Nginx is down per {{ problemID }} on {{ reporting_host }} reported by Dynatrace nginix monitor."
caller: admin
urgency: "{{ sn_urgency }}"
impact: "{{ sn_impact }}"
register: new_incident
delegate_to: localhost
- name: Display incident number
ansible.builtin.debug:
var: new_incident.record.number
- name: Pass incident number
ansible.builtin.set_fact:
ticket_number: "{{ new_incident.record.number }}"
- name: Try to restart nginx
ansible.builtin.service:
name: nginx
state: restarted
register: chksrvc
- name: Update incident in ServiceNow
servicenow.itsm.incident:
state: in_progress
number: "{{ ticket_number }}"
other:
comments: "Ansible automation is working on {{ problemID }}. on host {{ reporting_host }}"
delegate_to: localhost
- name: Validate service is up and update/close SNOW ticket
block:
- name: Close incident in ServiceNow
servicenow.itsm.incident:
state: closed
number: "{{ ticket_number }}"
close_code: "Solved (Permanently)"
close_notes: "Go back to bed. Ansible fixed problem {{ problemID }} on host {{ reporting_host }} reported by Dynatrace."
delegate_to: localhost
when: chksrvc.state == "started"A Red Hat não garante a exatidão desse código. Todo o conteúdo é considerado sem suporte, a menos que especificado de outra forma.
É importante enfatizar que o nome do template da tarefa a ser estabelecido no automation controller deve estar alinhado ao nome especificado na seção run_job_template do rulebook. No contexto deste caso de uso de exemplo, optei por incorporar pesquisas no template de tarefa, ativando prompts na inicialização das variáveis problemID e reporting_host, conforme passadas pelo rulebook.
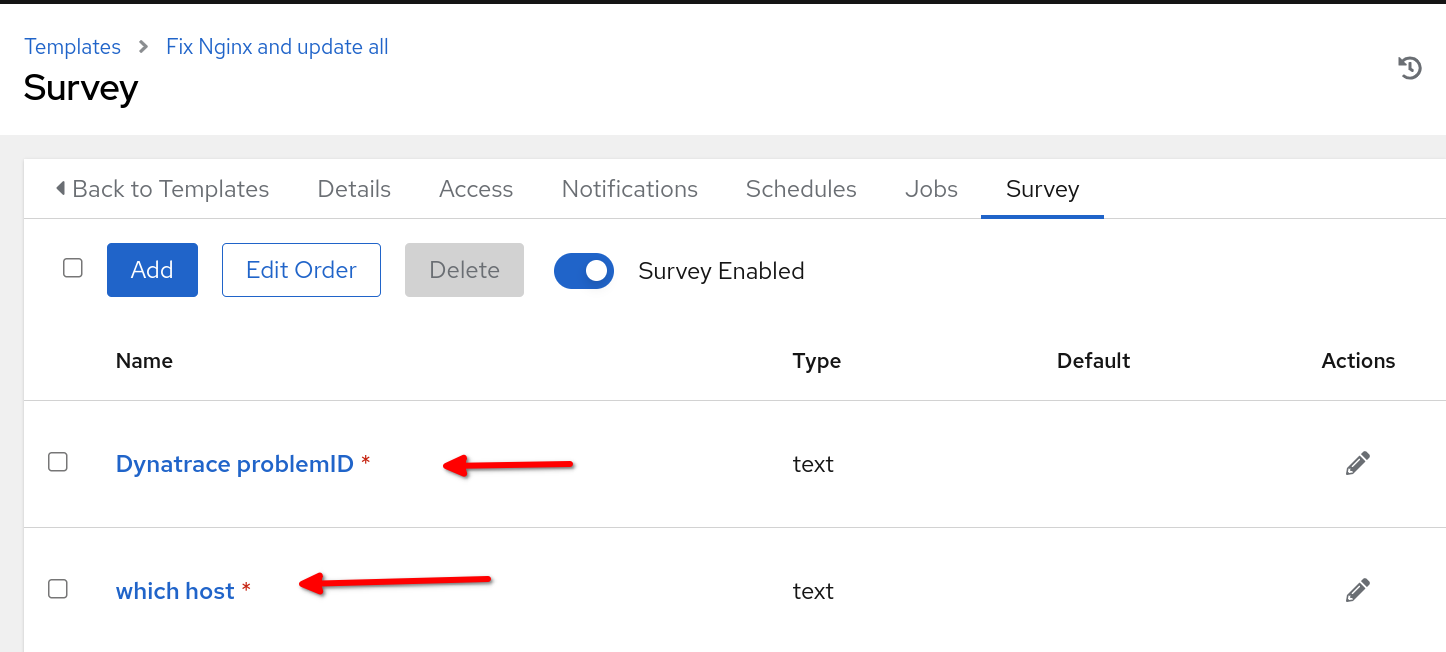


Para o nosso caso de uso funcionar, você precisará que o automation controller seja integrado ao ServiceNow e tenha um automation execution environment com a coleção ITSM ServiceNow configurado para ser usado com o template de tarefa. Além disso, seu projeto no automation controller deve hospedar o playbook de correção e o nome do host que hospeda o servidor web NGINX deve ser incluído no inventário do automation controller. Por fim, integre o controlador do Event-Driven Ansible ao automation controller.
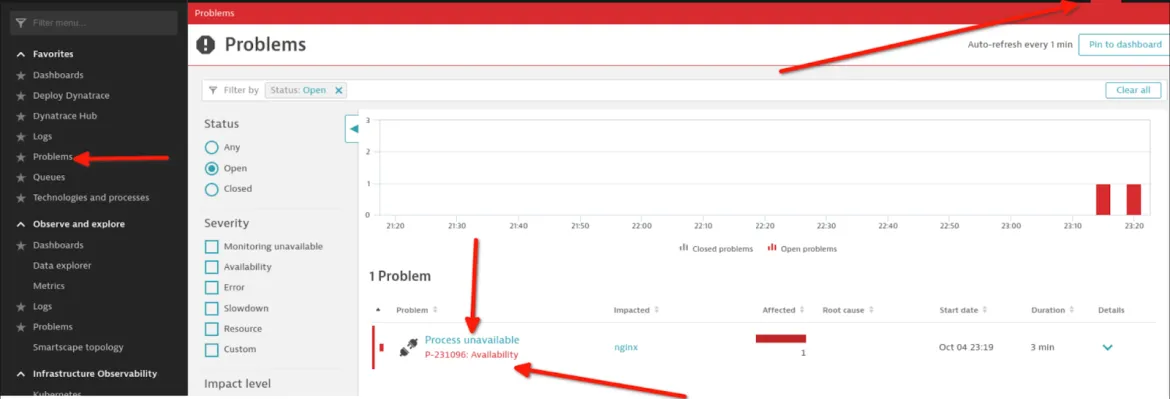
Agora que tudo está configurado corretamente, teste encerrando o processo NGINX no host e observe o seguinte:
Um alerta gerado na plataforma da Dynatrace:
Um evento de auditoria de regra no Event-Driven Ansible:
Evento de tarefa em que o template de tarefa de correção é executado no automation controller:

Um ticket de incidente será aberto, atualizado e fechado se o processo NGINX for restaurado no host problemático informado pela Dynatrace.





Neste exemplo de caso de uso, apresentamos o plugin da Dynatrace e os ambientes de decisão, explorando amostras de dados de evento payload da nossa fonte para demonstrar como preencher variáveis de forma dinâmica. Implementamos um monitor de processos no nível do host para o processo NGINX na Dynatrace. Como alternativa, poderíamos ter usado um monitor sintético na Dynatrace para o monitoramento no nível da aplicação.
Enfatizando a importância da adaptabilidade, nosso playbook de correção permanece dinâmico e tem como escopo específico ser executado somente nos hosts informados como problemáticos pela Dynatrace. Embora esse exemplo inclua vários tópicos, é essencial reconhecer que a automação de tarefas complexas não exige uma abordagem abrangente desde o início. Em vez disso, considere uma integração gradual de tarefas de correção no seu playbook no decorrer do tempo, à medida que você aprende a automatizar correções. De início, você pode optar por abrir um ticket de incidente antes de implementar qualquer ação de correção e, gradualmente, fazer a transição para a automação de problemas comuns. Ao implementar princípios ágeis padrão à sua jornada de automação, você pode adotar uma abordagem iterativa e flexível. É importante observar que a era de solucionar problemas comuns manualmente durante a madrugada está virando coisa do passado. Você agora pode adotar práticas eficazes de automação empresarial e recuperar seu sono.
Boa automação!
Recursos adicionais e próximas etapas
Quer mais informações sobre o Event-Driven Ansible?
- Página da web do Event-Driven Ansible
- Laboratórios individualizados: experiência hands-on com o Event-Driven Ansible e muito mais
- Playlist de vídeos sobre o Event-Driven Ansible
Sobre o autor

Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações
Virtualização
O futuro da virtualização empresarial para suas cargas de trabalho on-premise ou na nuvem