L'intégration de l'automatisation dans les outils d'observabilité est primordiale dans l'environnement d'exploitation informatique moderne, car elle favorise la synergie entre visibilité et efficacité. Les outils d'observabilité fournissent des informations détaillées sur les performances, l'intégrité et le comportement de systèmes complexes, ce qui permet aux entreprises d'identifier et de corriger les problèmes de manière proactive avant qu'ils ne s'aggravent.
Lorsqu'ils sont intégrés en toute transparence aux frameworks d'automatisation, ces outils offrent aux entreprises un moyen de surveiller les évolutions dynamiques en temps réel, mais aussi d'y répondre. C'est grâce à cette synergie entre l'observabilité et l'automatisation que les équipes informatiques peuvent s'adapter rapidement à l'évolution des conditions, réduire les temps d'arrêt et optimiser l'utilisation des ressources. En automatisant les réponses basées sur les données d'observabilité, les entreprises gagnent en agilité, réduisent les interventions manuelles et conservent une infrastructure robuste et résiliente. En résumé, l'association de l'observabilité et de l'automatisation est indispensable pour mettre en place un environnement d'exploitation proactif, réactif et rationalisé dans le paysage complexe et changeant des technologies actuelles.
Dans cet article de blog, nous allons étudier un cas d'utilisation courant qui implique la surveillance des processus à la fois sur des systèmes bare metal et sur des machines virtuelles. Notre étude se concentrera sur l'utilisation de l'agent Dynatrace OneAgent, un fichier binaire déployé sur des hôtes et composé d'une suite de services spécialisés, configurés avec soin pour la surveillance de l'environnement. Ces services collectent de manière active des indicateurs de mesure télémétriques et obtiennent ainsi des informations sur divers aspects de vos hôtes, notamment sur le matériel, les systèmes d'exploitation et les processus d'application.
Dans ce cas d'utilisation, notre objectif est d'établir un moniteur au niveau de l'hôte spécifiquement pour le processus du serveur web NGINX. Je vous guiderai pour la mise en œuvre d'Event-Driven Ansible, un framework qui relie les sources d'événements aux actions correspondantes par le biais de règles définies. Dans ce cas, la source de l'événement est Dynatrace.
Une fois la configuration terminée, nous allons simuler le scénario suivant.
- Le serveur web NGINX subit un temps d'arrêt non planifié sur le serveur.
- Le moniteur de processus, facilité par Dynatrace OneAgent, détecte rapidement le processus NGINX en échec et génère une alerte de problème sur la plateforme Dynatrace.
- Le plug-in source Dynatrace, tel qu'il est défini dans le rulebook utilisé par Event-Driven Ansible, interroge activement les événements de panne.
- En réponse à l'événement, Event-Driven Ansible exécute un modèle de tâche qui entreprend les actions suivantes :
- Création d'un ticket d'incident ServiceNow
- Tentative de redémarrage du processus NGINX
- Mise à jour du statut du ticket d'incident sur « En cours »
- Fermeture du ticket uniquement si le processus NGINX est correctement restauré
Le schéma ci-dessous illustre les interactions entre ces composants intégrés.
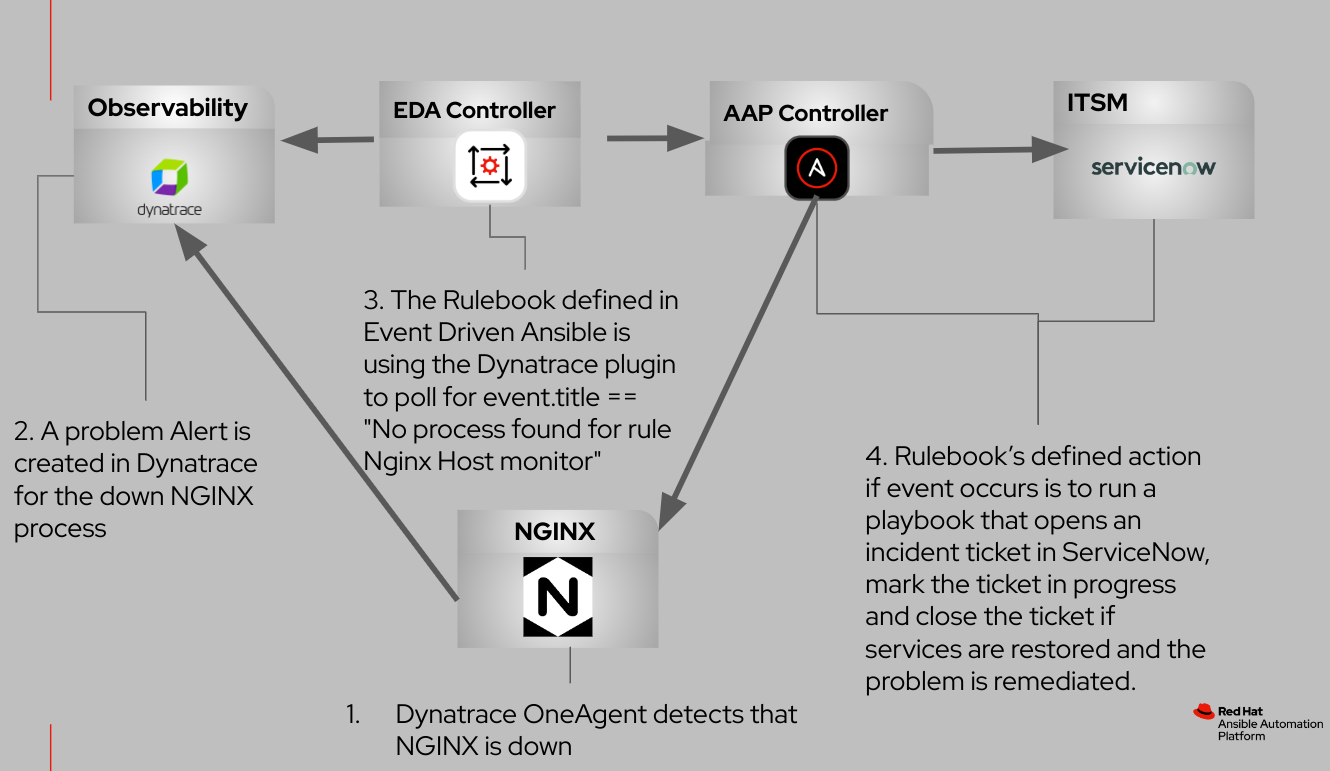
Avant de commencer, familiarisons-nous avec quelques termes qui correspondent aux concepts fondamentaux d'Event-Driven Ansible.
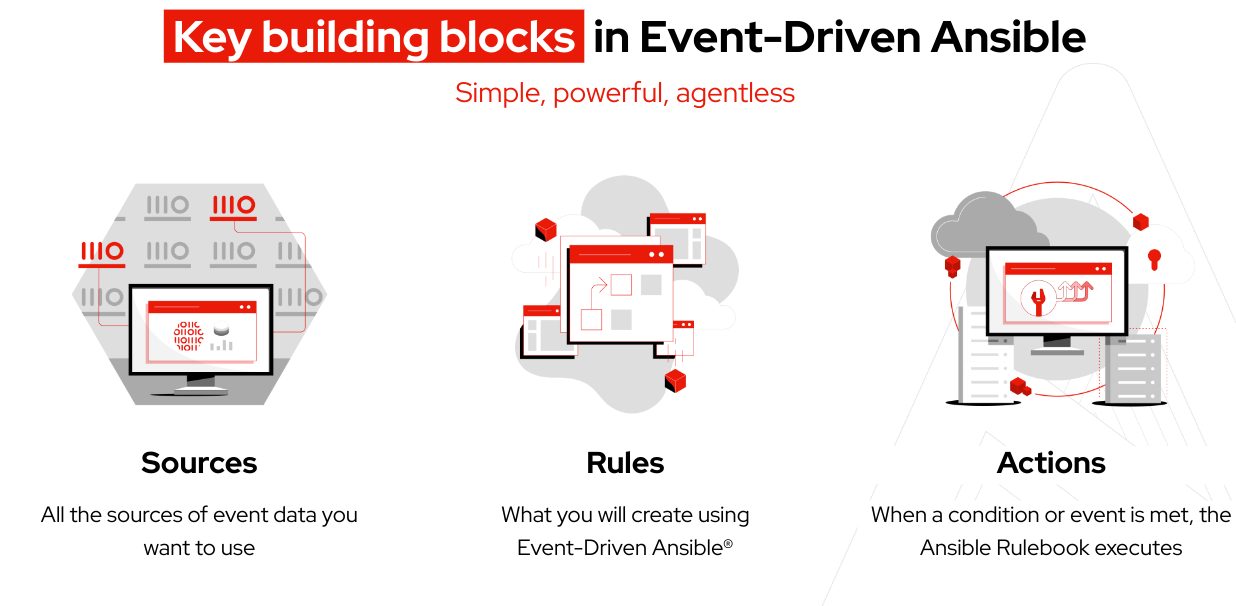
Terminologie
Un rulebook Ansible contient à la fois une source d'événements et des instructions détaillées basées sur des règles en ce qui concerne les actions à entreprendre lorsque des conditions spécifiques sont remplies, offrant ainsi un haut niveau de flexibilité.
Un environnement de décision est une image de conteneur conçue pour exécuter les rulebooks Ansible utilisés dans le contrôleur Event-Driven Ansible.
Les plug-ins de source d'événement sont généralement créés en Python et servent à collecter des événements depuis une source d'événement que vous avez spécifiée. Les plug-ins sont également distribués via les collections de contenus certifiés Red Hat Ansible Certified Content Collection.
Un environnement de décision devra être créé. Voir l'exemple ci-dessous du fichier de build :
---
version: 3
images:
base_image:
name: registry.redhat.io/ansible-automation-platform-24/de-minimal-rhel8:latest
dependencies:
galaxy:
collections:
- ansible.eda
- dynatrace.event_driven_ansible
system:
- pkgconf-pkg-config [platform:rpm]
- systemd-devel [platform:rpm]
- gcc [platform:rpm]
- python39-devel [platform:rpm]
options:
package_manager_path: /usr/bin/microdnfPour obtenir des conseils supplémentaires sur la création des environnements de décision, consultez la documentation fournie. Une fois votre environnement de décision créé, vous pouvez envoyer l'image de conteneur vers le référentiel d'images désigné, puis extraire l'image dans votre contrôleur Event-Driven Ansible.
Avec l'établissement de votre environnement de décision, vous êtes sur le point de créer une activation de règle dans le contrôleur Event-Driven Ansible. Cette activation contient le rulebook qui définit votre source d'événements et qui fournit des instructions détaillées sur les actions à exécuter dans certaines situations. À l'instar de l'organisation des playbooks dans les projets dans Automation Controller, le contrôleur Event-Driven Ansible utilise des projets pour gérer et contenir les rulebooks.
Vous trouverez ci-dessous une hiérarchie standard de répertoires pour l'organisation et le stockage de vos rulebooks et playbooks dans le référentiel Git.
Pour ce cas d'utilisation, nous allons créer un rulebook qui utilise le plug-in Dynatrace comme source d'événements Ansible et nous indiquerons ce que nous devons faire lorsqu'une condition est remplie.
En général, il existe trois modèles d'intégration pour les plug-ins sources :
- Sondage ;
- Webhook ;
- Messagerie.
Dans notre contexte, le plug-in source Dynatrace récupère les événements de manière efficace en interrogeant les conditions spécifiées dans le rulebook. Ce mécanisme de sondage introduit une variable delay inhérente au plug-in Dynatrace, comme indiqué dans le rulebook (consultez le paramètre de variable delay).
Ce délai joue un rôle crucial dans la réglementation du comportement du plug-in grâce à la mise en œuvre d'un mécanisme de limitation. Il orchestre l'exécution des appels d'API à intervalles prédéfinis et permet au plug-in de générer un nouvel événement en fonction de la réponse reçue. Ce paramétrage intentionnel des appels d'API est essentiel pour la gestion et l'optimisation de l'ensemble du workflow, en atténuant les risques de rencontrer des limites de débit et en garantissant le bon fonctionnement du système.
Voir le rulebook ci-dessous :
---
- name: Watching for Problems on Dynatrace
hosts: all
sources:
- dynatrace.event_driven_ansible.dt_esa_api:
dt_api_host: "{{ dynatrace_host }}"
dt_api_token: "{{ dynatrace_token }}"
delay: "{{ dynatrace_delay }}"
rules:
- name: Look for open Process monitor problem
condition: event.title == "No process found for rule Nginx Host monitor"
action:
run_job_template:
name: Fix Nginx and update all
organization: "Default"
job_args:
extra_vars:
problemID: "{{ event.displayId }}"
reporting_host: "{{ event.impactedEntities[0].name }}"Remarque : Red Hat ne fournit aucune prise en charge expresse en ce qui concerne l'exactitude de ce code. Sauf mention contraire, tout contenu est considéré comme non pris en charge.
Dans le rulebook ci-dessus, deux clés de YAML requièrent votre attention. L'une est la clé condition dans la section « rules ». Notez que event.title est égal à « No process found for rule Nginx Host monitor ». Mais d'où vient cette chaîne ?
Ensuite, regardez la variable reporting_host sous la section « action » où nous appelons le modèle de tâche à exécuter dans Automation Controller. Où obtenir event.impactedEntities[0].name ?
Dans cet article, nous détaillerons la définition et l'utilisation de ces éléments clés dans nos processus d'automatisation orientée événements.
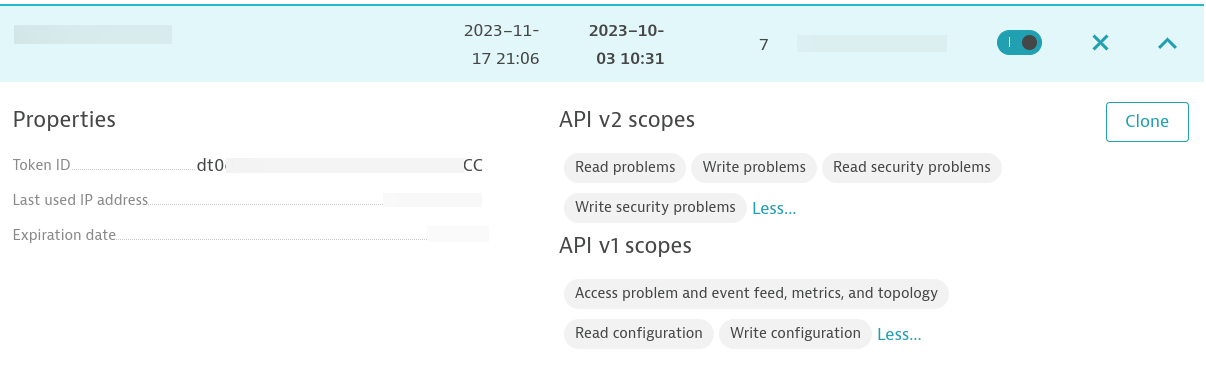
Une fois que vous avez installé l'agent Dynatrace OneAgent sur votre hôte cible, vous devez créer un jeton d'accès. Assurez-vous que le token dispose des autorisations suivantes :
Vous devrez configurer une règle de surveillance de la disponibilité des processus de niveau hôte pour le processus NGINX. Assurez-vous que le nom d'hôte qui exécute NGINX correspond au nom d'hôte spécifié dans votre inventaire au sein d'Automation Controller.
Après avoir configuré le moniteur, vous pouvez tester la charge utile interrogée par l'activation du rulebook dans Event-Driven Ansible en supprimant le processus NGINX sur votre hôte géré.
Voici un exemple d'audit de règle en ce qui concerne la charge utile dans Event-Driven Ansible :
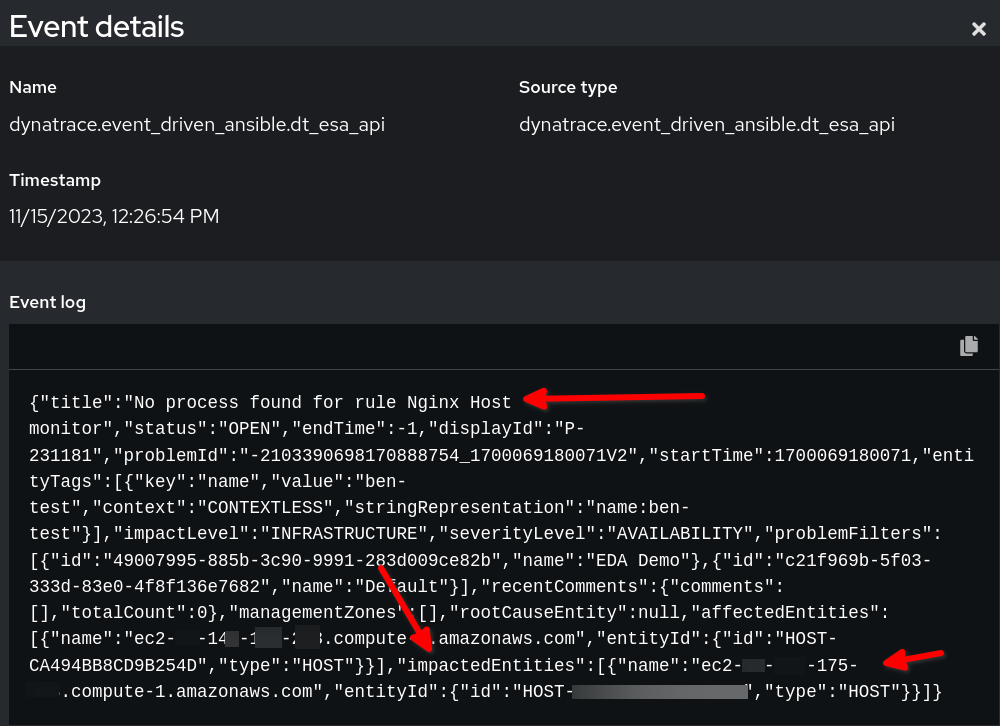
Dans l'exemple ci-dessus, vous voyez que les données d'événement de charge utile de Dynatrace sont au format JSON. Nous utilisons la chaîne définie dans event.title pour notre condition, et la variable reporting_host est définie de manière dynamique par la valeur event.impactedEntities[0].name. Remarque : impactedEntities.name[0].name peut être supérieur à un hôte.
Maintenant que nous savons comment sont définies la valeur clé condition et les variables reporting_host, que dois-je faire ensuite ?
C'est le moment idéal pour évaluer le playbook destiné à être exécuté dans Automation Controller en tant que modèle de tâche. Ce playbook est utilisé lorsque la charge utile d'événement, déclenchée par Event-Driven Ansible qui signale l'arrêt du processus NGINX, est détectée par Dynatrace :
---
- name: Restore nginx service create, update and close ServiceNow ticket after Ansible restores services
hosts: "{{ reporting_host }}"
gather_facts: false
become: true
vars:
incident_description: Nginx Web Server is down
sn_impact: medium
sn_urgency: medium
tasks:
- name: Create an incident in ServiceNow
servicenow.itsm.incident:
state: new
description: " Dynatrace reported {{ problemID }}"
short_description: "Nginx is down per {{ problemID }} on {{ reporting_host }} reported by Dynatrace nginix monitor."
caller: admin
urgency: "{{ sn_urgency }}"
impact: "{{ sn_impact }}"
register: new_incident
delegate_to: localhost
- name: Display incident number
ansible.builtin.debug:
var: new_incident.record.number
- name: Pass incident number
ansible.builtin.set_fact:
ticket_number: "{{ new_incident.record.number }}"
- name: Try to restart nginx
ansible.builtin.service:
name: nginx
state: restarted
register: chksrvc
- name: Update incident in ServiceNow
servicenow.itsm.incident:
state: in_progress
number: "{{ ticket_number }}"
other:
comments: "Ansible automation is working on {{ problemID }}. on host {{ reporting_host }}"
delegate_to: localhost
- name: Validate service is up and update/close SNOW ticket
block:
- name: Close incident in ServiceNow
servicenow.itsm.incident:
state: closed
number: "{{ ticket_number }}"
close_code: "Solved (Permanently)"
close_notes: "Go back to bed. Ansible fixed problem {{ problemID }} on host {{ reporting_host }} reported by Dynatrace."
delegate_to: localhost
when: chksrvc.state == "started"« Red Hat ne fournit aucune prise en charge expresse en ce qui concerne l'exactitude de ce code. Sauf mention contraire, tout contenu est considéré comme non pris en charge. »
Il est important de souligner que le nom du modèle de tâche à établir dans Automation Controller doit correspondre au nom spécifié dans la section run_job_template du rulebook. Dans le contexte de cet exemple de cas d'utilisation, j'ai choisi d'intégrer les questionnaires dans mon modèle de tâche, ce qui active ainsi les invites au lancement des variables problemsID et reporting_host, telles qu'elles sont transmises depuis le rulebook.
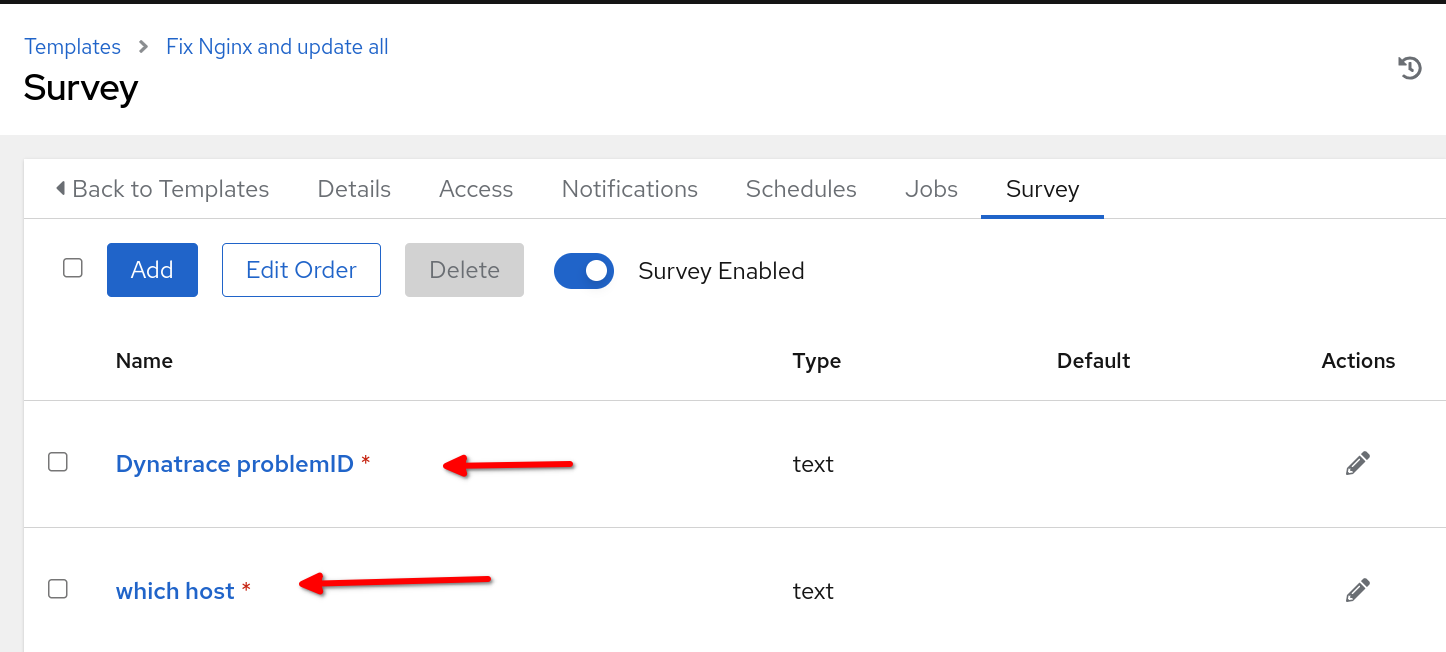


Pour que notre cas d'utilisation fonctionne, il sera nécessaire qu'Automation Controller soit intégré à ServiceNow et qu'il dispose d'un environnement d'exécution pour l'automatisation avec la collection ITSM ServiceNow configurée dans Automation Controller à utiliser avec votre modèle de tâche. En outre, assurez-vous d'avoir créé un projet dans Automation Controller qui héberge le playbook de correction et que le nom d'hôte hébergeant le serveur web NGINX est inclus dans l'inventaire d'Automation Controller. Pour terminer, assurez-vous que vous avez réussi à intégrer votre contrôleur Event-Driven Ansible à Automation Controller.
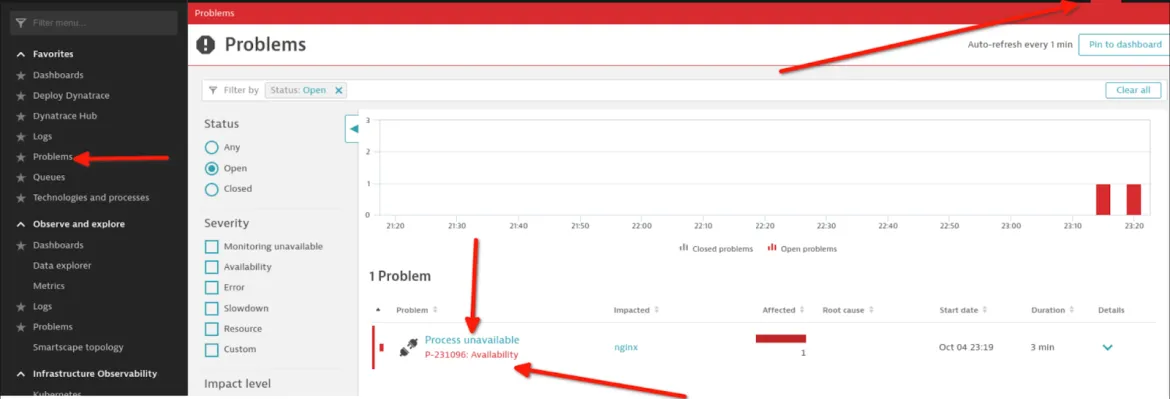
Maintenant que tout est correctement configuré, vous devez effectuer un test en arrêtant votre processus NGINX sur votre hôte et observer ce qui suit.
Une alerte générée dans Dynatrace :
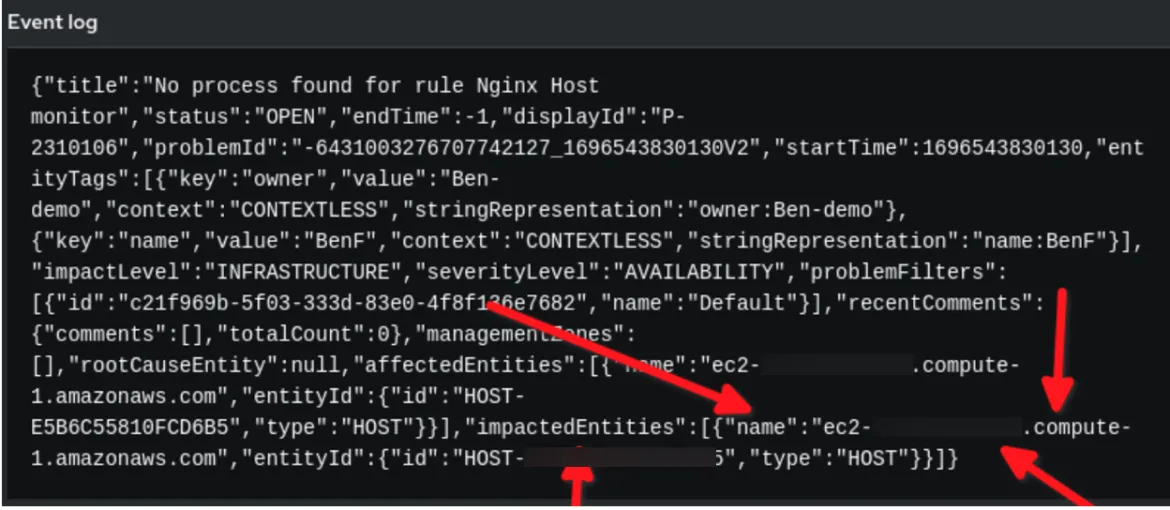
Un événement d'audit de règle dans Event-Driven Ansible :
Un événement de tâche où le modèle de tâche de correction s'exécute dans Automation Controller :

Un ticket d'incident ouvert, mis à jour et fermé si le processus NGINX est restauré sur l'hôte problématique qui a été signalé par Dynatrace :





Dans cet exemple de cas d'utilisation, nous avons introduit le plug-in Dynatrace et les environnements de décision, en explorant les données d'événement de charge utile de notre source pour montrer comment remplir des variables de manière dynamique. Nous avons mis en œuvre un moniteur de processus au niveau de l'hôte pour le processus NGINX dans Dynatrace. Nous aurions aussi pu utiliser un écran synthétique dans Dynatrace pour la surveillance au niveau de l'application.
En mettant l'accent sur l'adaptabilité, notre playbook de correction reste dynamique et est spécialement conçu pour s'exécuter uniquement sur les hôtes signalés comme problématiques par Dynatrace. Cet exemple couvre un large éventail de sujets, mais il est essentiel de reconnaître que l'automatisation de tâches complexes ne nécessite pas d'adopter dès le départ une approche exhaustive. Envisagez plutôt d'intégrer progressivement les tâches de correction dans votre playbook, à mesure que vous apprenez à automatiser les correctifs. Au départ, vous pouvez choisir d'ouvrir un ticket d'incident avant de mettre en œuvre toute mesure de correction, en passant progressivement à l'automatisation des problèmes courants. L'application de principes agiles standards à votre parcours d'automatisation permet d'adopter une approche itérative et flexible. Il est important de noter que l'ère de la résolution manuelle des problèmes courants à 3 heures du matin évolue et vous offre la possibilité de récupérer votre sommeil grâce à des pratiques d'automatisation efficaces à l'échelle de l'entreprise.
Bonne automatisation !
Ressources supplémentaires et étapes suivantes
Vous souhaitez en savoir plus sur Event-Driven Ansible ?
- Page web d'Event-Driven Ansible
- Ateliers en autonomie : Testez notre solution Event-Driven Ansible et plus encore
- Liste de lectures de vidéos sur Event-Driven Ansible
À propos de l'auteur

Parcourir par canal

Automatisation
Les dernières nouveautés en matière d'automatisation informatique pour les technologies, les équipes et les environnements

Intelligence artificielle
Actualité sur les plateformes qui permettent aux clients d'exécuter des charges de travail d'IA sur tout type d'environnement

Cloud hybride ouvert
Découvrez comment créer un avenir flexible grâce au cloud hybride

Sécurité
Les dernières actualités sur la façon dont nous réduisons les risques dans tous les environnements et technologies

Edge computing
Actualité sur les plateformes qui simplifient les opérations en périphérie

Infrastructure
Les dernières nouveautés sur la plateforme Linux d'entreprise leader au monde

Applications
À l’intérieur de nos solutions aux défis d’application les plus difficiles
Virtualisation
L'avenir de la virtualisation d'entreprise pour vos charges de travail sur site ou sur le cloud