L'integrazione degli strumenti di osservabilità con l'automazione è fondamentale nell'ambito delle moderne operazioni IT, poiché favorisce una relazione simbiotica tra visibilità ed efficienza. Gli strumenti di osservabilità forniscono informazioni approfondite su prestazioni, integrità e comportamento dei sistemi complessi, consentendo alle organizzazioni di identificare e correggere in modo proattivo i problemi prima che passino al livello superiore.
Se integrati in modo uniforme con i framework di automazione, questi strumenti consentono alle aziende non solo di monitorare, ma anche di rispondere ai cambiamenti dinamici in tempo reale. Questa sinergia tra osservabilità e automazione consente ai team IT di adattarsi rapidamente alle condizioni in evoluzione, ridurre il tempo di fermo e ottimizzare l'utilizzo delle risorse. Automatizzando le risposte basate sui dati di osservabilità, le organizzazioni possono migliorare la propria agilità, ridurre gli interventi manuali e mantenere un'infrastruttura robusta e resiliente. In sostanza, utilizzare l'osservabilità insieme all'automazione è indispensabile per ottenere un ambiente operativo proattivo, reattivo e ottimizzato nel panorama frenetico e complesso della tecnologia odierna.
In questo articolo del blog esamineremo uno scenario di utilizzo comune che riguarda il monitoraggio dei processi su macchine virtuali e bare metal. La nostra esplorazione si concentrerà sull'utilizzo di OneAgent di Dynatrace, un file binario distribuito sugli host che comprende una suite di servizi specializzati configurati con meticolosità per il monitoraggio dell'ambiente. Questi servizi raccolgono attivamente le metriche di telemetria, acquisendo informazioni dettagliate sui vari aspetti degli host, inclusi hardware, sistemi operativi e processi applicativi.
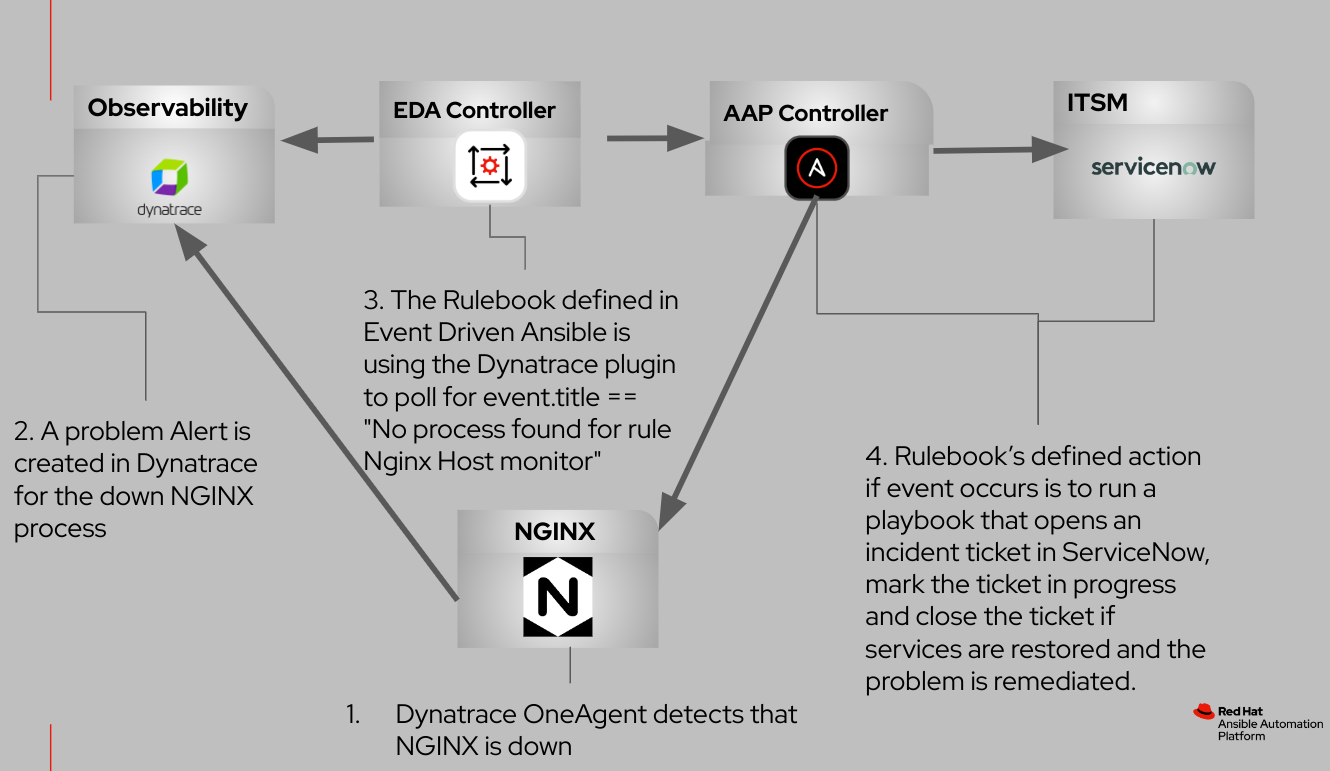
In questo scenario di utilizzo, il nostro obiettivo è definire un monitoraggio a livello di host specifico per il processo del web server NGINX. Illustreremo l'implementazione di Event-Driven Ansible, un framework che collega le sorgenti di eventi alle azioni corrispondenti tramite regole definite. In questo caso, la sorgente dell'evento è Dynatrace.
Una volta completata la configurazione, simuleremo il seguente scenario:
- Il web server NGINX subisce un tempo di fermo non pianificato sul server.
- Il monitoraggio dei processi, agevolato da Dynatrace OneAgent, rileva tempestivamente il processo NGINX non riuscito e genera un avviso di problema nella piattaforma Dynatrace.
- Il plugin sorgente Dynatrace, come definito nel rulebook utilizzato da Event-Driven Ansible, esegue attivamente il polling degli eventi di errore.
- In risposta all'evento, Event-Driven Ansible esegue un modello di processo che effettua le seguenti azioni:
- Avvia la creazione di un ticket dell'incidente su ServiceNow.
- Tenta di riavviare il processo NGINX.
- Aggiorna lo stato del ticket a "In corso".
- Chiude il ticket solo se il processo NGINX viene ripristinato correttamente.
Il diagramma di flusso riportato di seguito illustra le interazioni tra questi componenti integrati.
Prima di iniziare, prendiamo familiarità con alcuni termini che rappresentano concetti chiave di Event-Driven Ansible:
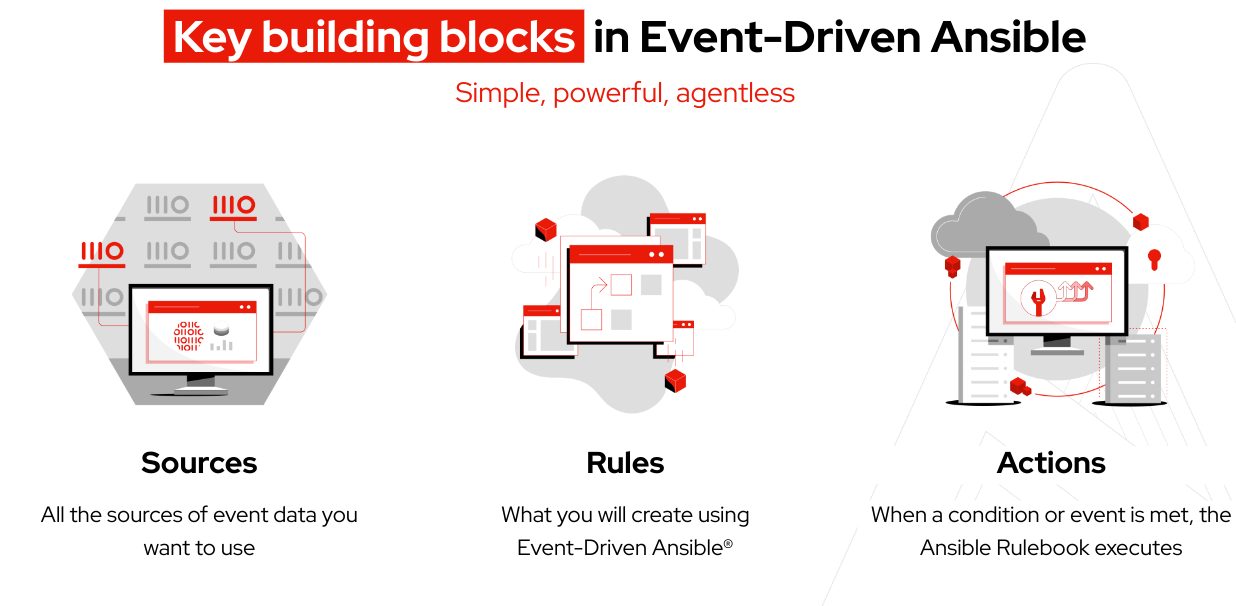
Terminologia:
Un Ansible Rulebook include sia la sorgente dell'evento che istruzioni dettagliate basate su regole relative alle azioni da intraprendere quando vengono soddisfatte condizioni specifiche, offrendo un elevato grado di flessibilità.
Un ambiente decisionale è un'immagine container creata per eseguire gli Ansible Rulebook utilizzati nel controller di Event-Driven Ansible.
I plugin per le sorgenti di eventi sono comunemente creati in Python e servono a raccogliere gli eventi dalla sorgente specificata. Inoltre, i plugin vengono distribuiti tramite Red Hat Ansible Certified Content Collections.
Sarà necessario creare un ambiente decisionale. Di seguito l'esempio del file di sviluppo:
---
version: 3
images:
base_image:
name: registry.redhat.io/ansible-automation-platform-24/de-minimal-rhel8:latest
dependencies:
galaxy:
collections:
- ansible.eda
- dynatrace.event_driven_ansible
system:
- pkgconf-pkg-config [platform:rpm]
- systemd-devel [platform:rpm]
- gcc [platform:rpm]
- python39-devel [platform:rpm]
options:
package_manager_path: /usr/bin/microdnfConsulta la documentazione fornita per ulteriori indicazioni sulla creazione di ambienti decisionali. Dopo aver creato l'ambiente decisionale, procedi prima al push dell'immagine container nel repository di immagini designato e poi al pull dell'immagine nel controller di Event-Driven Ansible.
Completati questi passaggi, avrai quasi creato un'attivazione delle regole nel controller di Event-Driven Ansible. Questa attivazione racchiude il rulebook, definendo la sorgente dell'evento e istruzioni dettagliate sulle azioni da eseguire in condizioni specifiche. Analogamente all'organizzazione dei playbook all'interno dei progetti in Automation Controller, il controller di Event-Driven Ansible utilizza i progetti per gestire e contenere i nostri rulebook.
Di seguito è riportata una gerarchia di directory standard per l'organizzazione e l'archiviazione di rulebook e playbook nel repository Git.
Dopo aver creato un progetto nel controller di Event-Driven Ansible, è necessario realizzare un'attivazione del rulebook, ovvero un processo in background definito da un rulebook in esecuzione all'interno di un ambiente decisionale.
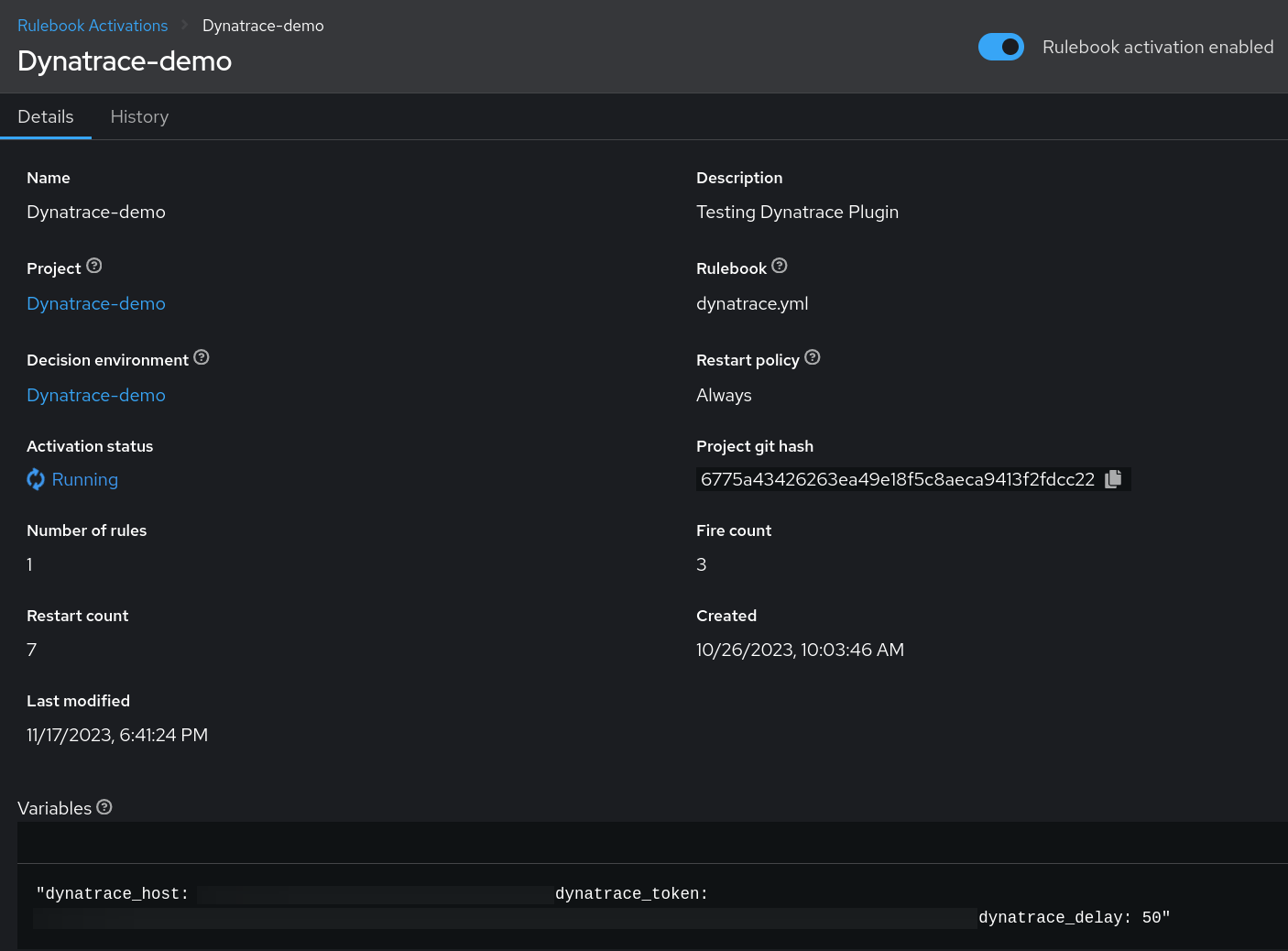
Per questo scenario di utilizzo, creeremo un rulebook che utilizza il plugin Dynatrace come sorgente dell'evento Ansible e specificheremo cosa fare quando viene soddisfatta una condizione.
In generale, esistono tre modelli di integrazione per i plugin sorgente:
- polling
- webhook
- messaggistica
Nel contesto del nostro scenario di utilizzo, il plugin sorgente Dynatrace recupera gli eventi in modo efficiente eseguendo un polling attivo in base alle condizioni specificate delineate nel rulebook. Questo meccanismo di polling introduce una variabile delay inerente al plugin Dynatrace, come indicato nel rulebook (consulta la configurazione della variabile delay).
Questo ritardo svolge un ruolo cruciale nella regolazione del comportamento del plugin, implementando un meccanismo di throttling. In sostanza, orchestra l'esecuzione delle chiamate API a intervalli predefiniti, consentendo al plugin di generare un nuovo evento in base alla risposta ricevuta. Questo ritmo intenzionale delle chiamate API si rivela fondamentale per la gestione e l'ottimizzazione del flusso di lavoro complessivo, per ridurre il rischio di incontrare limiti di frequenza e garantire il funzionamento lineare del sistema.
Consulta il rulebook di seguito:
---
- name: Watching for Problems on Dynatrace
hosts: all
sources:
- dynatrace.event_driven_ansible.dt_esa_api:
dt_api_host: "{{ dynatrace_host }}"
dt_api_token: "{{ dynatrace_token }}"
delay: "{{ dynatrace_delay }}"
rules:
- name: Look for open Process monitor problem
condition: event.title == "No process found for rule Nginx Host monitor"
action:
run_job_template:
name: Fix Nginx and update all
organization: "Default"
job_args:
extra_vars:
problemID: "{{ event.displayId }}"
reporting_host: "{{ event.impactedEntities[0].name }}"Nota: Red Hat non fornisce alcuna dichiarazione di supporto in merito alla correttezza di questo codice. Tutti i contenuti vengono ritenuti non supportati, se non diversamente specificato.
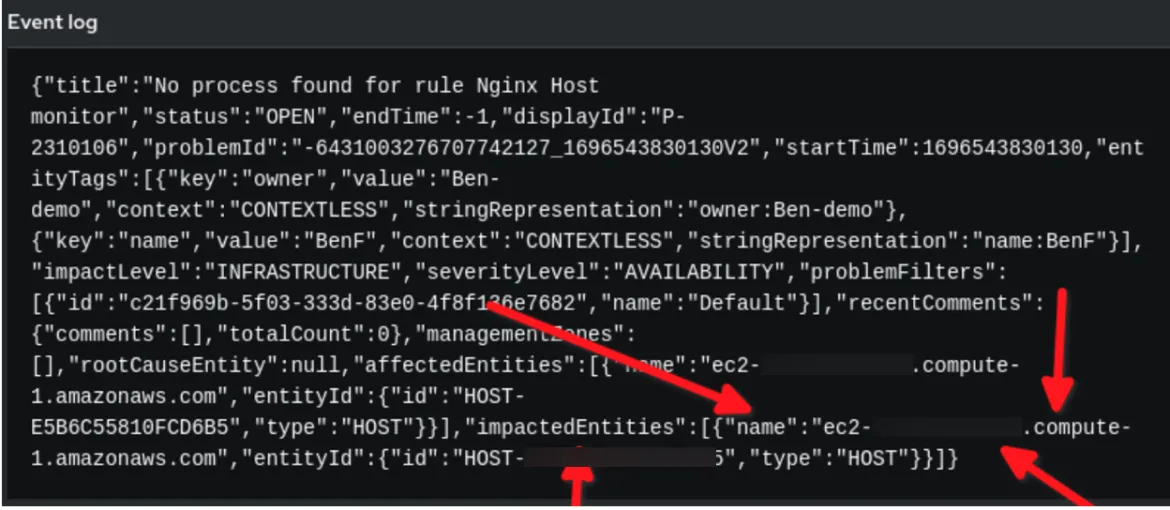
Nel rulebook riportato sopra, ci sono due chiavi in YAML che richiedono attenzione. Uno è la condizione stabilita nella sezione delle regole. Si noti che event.title equivale a "Nessun processo trovato per la regola Nginx per il monitoraggio dell'host". Ma dove è stata trovata quella stringa?
In secondo luogo, osserva la variabile reporting_host nella sezione delle azioni, in cui chiamiamo il modello di processo da eseguire nell'Automation Controller. Dove è stato trovato event.impactedEntities[0].name?
Nell'articolo approfondiremo la questione per scoprire la definizione e l'utilizzo di queste chiavi nei nostri processi di automazione basati sugli eventi.
Dopo aver installato Dynatace OneAgent sull'host di destinazione, dovrai creare un token di accesso. Assicurati che disponga delle autorizzazioni seguenti:
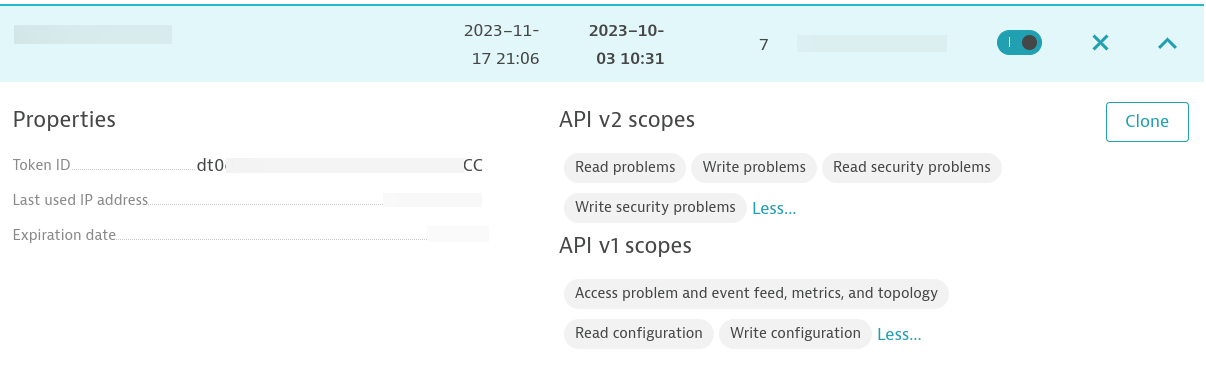
Devi configurare una regola di monitoraggio della disponibilità dei processi a livello di host per il processo NGINX. Assicurati che il nome host che esegue NGINX sia allineato al nome host specificato nell'inventario all'interno di Automation Controller.
Dopo aver configurato il monitor, puoi testare il payload sottoposto a polling dall'attivazione del rulebook in Event-Driven Ansible interrompendo il processo NGINX sull'host gestito.
Guarda l'esempio di audit delle regole dell'aspetto del payload in Event-Driven Ansible:
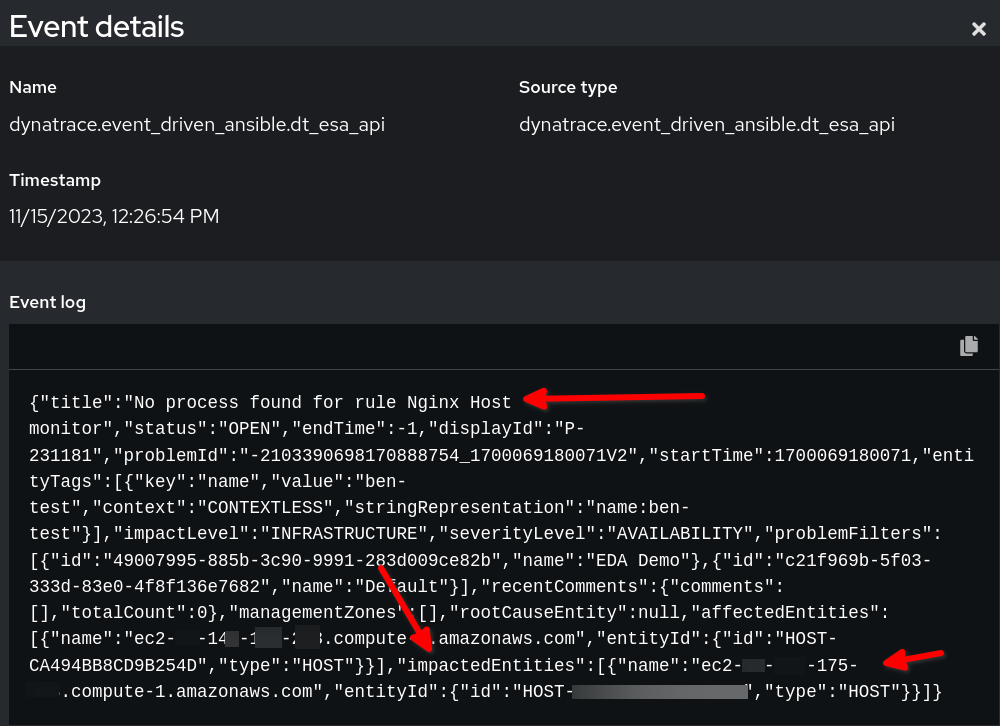
Nell'esempio precedente, i dati dell'evento del payload di Dynatrace sono in formato JSON. Utilizziamo la stringa configurata in event.title per la nostra condizione e la variabile reporting_host viene configurata in modo dinamico dal valore event.impactedEntities[0].name. Nota che impactedEntities.name[0].name potrebbe essere più di un host.
Ora che sappiamo come vengono impostate le variabili condition e reporting_host, qual è il prossimo passo?
Questo è il momento opportuno per valutare il playbook destinato all'esecuzione in Automation Controller come modello di processo. Questo playbook viene utilizzato quando il payload dell'evento attivato da Event-Driven Ansible, che segnala l'interruzione del processo NGINX, viene rilevato da Dynatrace:
---
- name: Restore nginx service create, update and close ServiceNow ticket after Ansible restores services
hosts: "{{ reporting_host }}"
gather_facts: false
become: true
vars:
incident_description: Nginx Web Server is down
sn_impact: medium
sn_urgency: medium
tasks:
- name: Create an incident in ServiceNow
servicenow.itsm.incident:
state: new
description: " Dynatrace reported {{ problemID }}"
short_description: "Nginx is down per {{ problemID }} on {{ reporting_host }} reported by Dynatrace nginix monitor."
caller: admin
urgency: "{{ sn_urgency }}"
impact: "{{ sn_impact }}"
register: new_incident
delegate_to: localhost
- name: Display incident number
ansible.builtin.debug:
var: new_incident.record.number
- name: Pass incident number
ansible.builtin.set_fact:
ticket_number: "{{ new_incident.record.number }}"
- name: Try to restart nginx
ansible.builtin.service:
name: nginx
state: restarted
register: chksrvc
- name: Update incident in ServiceNow
servicenow.itsm.incident:
state: in_progress
number: "{{ ticket_number }}"
other:
comments: "Ansible automation is working on {{ problemID }}. on host {{ reporting_host }}"
delegate_to: localhost
- name: Validate service is up and update/close SNOW ticket
block:
- name: Close incident in ServiceNow
servicenow.itsm.incident:
state: closed
number: "{{ ticket_number }}"
close_code: "Solved (Permanently)"
close_notes: "Go back to bed. Ansible fixed problem {{ problemID }} on host {{ reporting_host }} reported by Dynatrace."
delegate_to: localhost
when: chksrvc.state == "started""Red Hat non fornisce alcuna dichiarazione di supporto in merito alla correttezza di questo codice. Tutti i contenuti vengono ritenuti non supportati, se non diversamente specificato".
È importante sottolineare che il nome del modello di processo da definire in Automation Controller deve essere allineato al nome specificato nella sezione run_job_template del rulebook. Nel contesto di questo esempio, abbiamo scelto di racchiudere i sondaggi all'interno del modello di processo, abilitando i prompt all'avvio per le variabili problemID e reporting_host, come trasmesso dal rulebook.
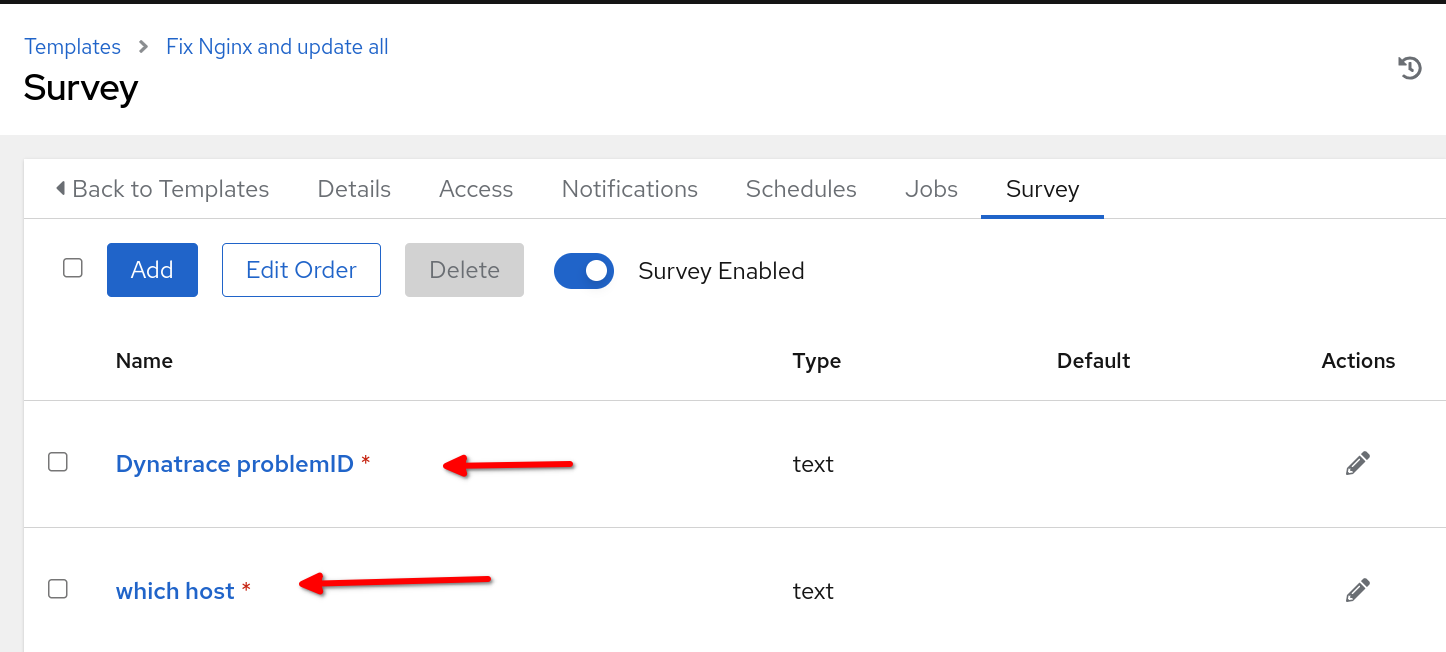


Affinché il nostro scenario di utilizzo funzioni, è necessario che Automation Controller sia integrato con ServiceNow e disponga di un Automation Execution Environment con la raccolta ITSM ServiceNow configurato in Automation Controller da utilizzare con il modello di processo. Inoltre, assicurati di aver creato un progetto in Automation Controller contenente il playbook di correzione e che il nome host che ospita il web server NGINX sia incluso nell'inventario di Automation Controller. Infine, assicurati di aver integrato il controller di Event-Driven Ansible con Automation Controller.
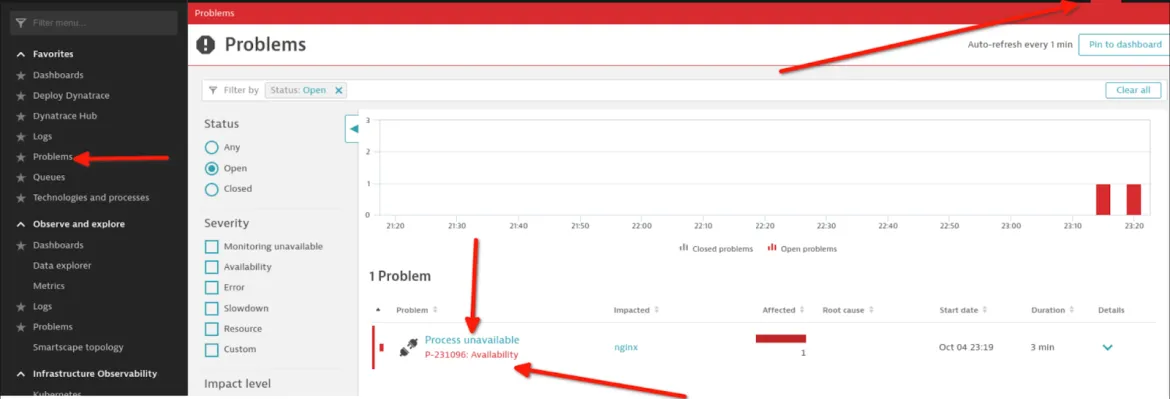
Ora che tutto è impostato correttamente, è necessario eseguire il test chiudendo il processo NGINX sull'host e osservando quanto segue:
Un avviso generato in Dynatrace:
Un evento di audit delle regole in Event-Driven Ansible:
Evento del processo in cui il modello di processo di correzione viene eseguito in Automation Controller

Un ticket di incidente viene aperto, aggiornato e chiuso se il processo NGINX viene ripristinato sull'host del problema segnalato da Dynatrace.





In questo esempio, abbiamo illustrato il plugin Dynatrace e gli ambienti decisionali, analizzando i dati degli eventi di payload di esempio dalla nostra sorgente per dimostrare come popolare dinamicamente le variabili. Abbiamo implementato un monitoraggio di processo a livello di host per il processo NGINX in Dynatrace. In alternativa, avremmo potuto utilizzare un monitoraggio artificiale in Dynatrace per il monitoraggio a livello di applicazione.
Sottolineando l'importanza dell'adattabilità, il nostro playbook di correzione rimane dinamico ed è specificamente concepito per essere eseguito esclusivamente sugli host segnalati come problematici da Dynatrace. Anche se questo esempio copre un'ampia gamma di argomenti, è essenziale riconoscere che l'automazione di attività complesse non richiede un approccio globale fin dall'inizio. Prendi invece inconsiderazione un'integrazione graduale delle attività di correzione nel playbook nel corso del tempo mentre impari ad automatizzare le correzioni. Inizialmente, potresti scegliere di aprire un ticket di incidente prima di implementare qualsiasi azione di correzione, passando gradualmente all'automazione dei problemi comuni. L'applicazione dei principi agili standard al percorso di automazione consente di adottare un approccio iterativo e flessibile. Vale la pena notare che l'era della risoluzione manuale dei problemi comuni alle 3 del mattino si sta evolvendo, offrendo l'opportunità di recuperare il sonno attraverso pratiche di automazione efficaci a livello aziendale.
Buona automazione!
Risorse aggiuntive e passaggi successivi
Vuoi sapere di più su Event-Driven Ansible?
- Pagina web di Event-Driven Ansible
- Laboratori autogestiti: esperienza pratica con Event-Driven Ansible e molto altro
- Playlist di video su Event-Driven Ansible
Sull'autore

Ricerca per canale

Automazione
Novità sull'automazione IT di tecnologie, team e ambienti

Intelligenza artificiale
Aggiornamenti sulle piattaforme che consentono alle aziende di eseguire carichi di lavoro IA ovunque

Hybrid cloud open source
Scopri come affrontare il futuro in modo più agile grazie al cloud ibrido

Sicurezza
Le ultime novità sulle nostre soluzioni per ridurre i rischi nelle tecnologie e negli ambienti

Edge computing
Aggiornamenti sulle piattaforme che semplificano l'operatività edge

Infrastruttura
Le ultime novità sulla piattaforma Linux aziendale leader a livello mondiale

Applicazioni
Approfondimenti sulle nostre soluzioni alle sfide applicative più difficili
Virtualizzazione
Il futuro della virtualizzazione negli ambienti aziendali per i carichi di lavoro on premise o nel cloud