Kubeflow は、AI/ML の主要なユースケース (データ探索、データパイプライン、モデルのトレーニング、モデルの提供) に対応する複数のツールをまとめた AI/ML プラットフォームです。Kubeflow は、データサイエンティストがポータルを介してこれらの機能にアクセスすることを可能にし、これらのツールを操作するための高レベルの抽象化を提供します。そのためデータサイエンティストは、Kubernetes がこれらの各ツールにどのようにプラグインされるかというような詳細を学ぶ必要がありません。とはいえ、Kubeflow 自体は、とりわけ Kubernetes 上で動作するように設計されており、Operator モデルを含む主要なコンセプトの多くを完全に取り入れています。実際、前述のポータルを除けば、Kubeflow は Operator のコレクションです。
この記事では、最近の顧客エンゲージメントで Red Hat が導入した、Kubeflow (1.3 以降) を OpenShift 環境で適切に動作させる一連の構成を検証します。
Kubeflow マルチテナンシーに関する考慮事項
Kubeflow が対象とするユースケースの 1 つに、多数のデータサイエンティストにサービスを提供する機能があります。Kubeflow はこれを実現するため、マルチテナンシーに対するアプローチを導入しています (リリース 1.3 から完全利用可能)。各データサイエンティストはそこで運用する Kubernetes 名前空間を受け取ります (名前空間をまたいでアーティファクトを共有するためのメカニズムもありますが、これらについては今回は調査外です)。
OpenShift でこの機能をサポートするために、Kubeflow の運用化の大部分が費やされるため、マルチテナンシーに対するこのアプローチを理解することが重要です。ユーザーごとに 1 つの名前空間、アプリケーションごとに 1 つの名前空間 (OpenShift をデプロイする場合はより一般的なパターン) では、認証/認可の編成方法に応じて OpenShift のデプロイ時に再設計が必要になる場合があります。
Kubeflow マルチテナンシーが適切に動作するようにするには、ユーザーを認証し、信頼できるヘッダー (デフォルトでは kubeflow-userid ですが、設定可能です) をすべての要求に追加する必要があります。そこから Kubeflow に代わり、存在しない場合は名前空間をユーザー用に作成します。
Kubeflow マルチテナンシーのもう 1 つの側面は、Profile の概念です。Profile は、ユーザーの環境を表すカスタムリソース (CR) です。Profile は、Kubeflow が管理する名前空間にマップされます。kubeflow-userid ヘッダーは、リクエストを適切にルーティングするために、Kubeflow の既存のプロファイルと一致する必要があります。
Profile が確立され、ユーザーに関連付けられると、対応する名前空間が Kubeflow によって作成され、そのユーザーの以降のすべてのアクティビティがここで実行されます。
Kubeflow は Istio とも緊密に統合されています。Kubeflow で Istio を実行するための厳密な要件はありませんが、Kubeflow セキュリティは Istio の構造に基づいているため、Istio の実行が推奨されまています。Istio で実行する場合、マルチテナンシーをサポートする最も簡単なアプローチの 1 つに、サービスメッシュに属する Kubeflow Profile の結果として作成された名前空間と、すべてのトラフィックが通過する単一の ingress-gateway を使用することが挙げられます。

上記のポイントは、ユーザー認証を実行し、前述の kubeflow-userid ヘッダーを設定するための自然な候補になります。
サービスメッシュとの統合
OpenShift Service Mesh は、OpenShift クラスタに複数のサービスメッシュを含めることができるという点で Istio と異なりますが、アップストリームの Istio では、メッシュが Kubernetes クラスタ全体に拡張されます。
このセットアップでは、1 つのサービスメッシュを AI/ML ユースケース専用にすることにしました。したがって、この AI/ML 専用サービスメッシュには、Kubeflow AI/ML 名前空間のみが属します。
また、データサイエンティストの追加および削除がいつでも実行される状況に対応する必要がありました。そのため、ユーザーごとに 1 つの Profile/名前空間という推奨モデルを導入することが決定しました。
まとめると、以下の要件を満たすソリューションを見つける必要がありました。
- データサイエンティストの接続が認証され、改ざんを防止しながら kubeflow-userid ヘッダーがリクエストに追加されていることを確認する
- Kubeflow Profile がデータサイエンティストごとに作成されるようにする
- Profile 作成の結果として Kubeflow が作成した Kubeflow 名前空間が、AI/ML サービスメッシュに属することを確認する
データサイエンティストの認証を維持
先ほど紹介したとおり、Kubeflow は接続されたユーザーを、ヘッダーを使用して表します。デフォルトのヘッダー名 kubeflow-userid を変更するオプションもありますが、複数の場所を変更する必要があるため、結果として、デフォルトのヘッダー名を使い続ける方が簡単だと判断しました。
このヘッダーを挿入するにはいくつかの方法があります。以下ではそのアプローチの 1 つを説明します。
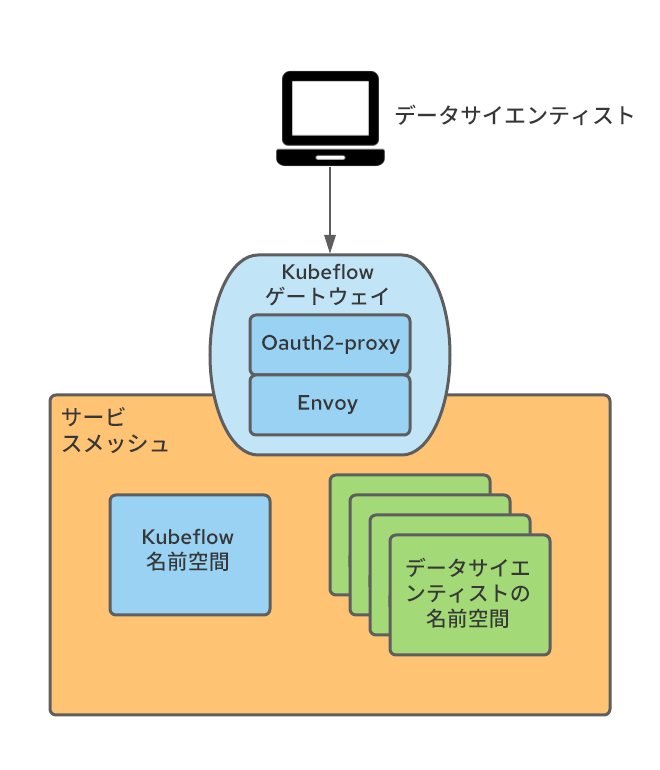
Kubeflow が Istio Ingress ゲートウェイ (デフォルトでは Kubeflow と呼ばれる) で外部向けのサービスを公開するという事実を利用して、認証されていないユーザーを OpenShift のログインフローにリダイレクトする oauth プロキシを使用して認証を実行するようゲートウェイを設定しました。この oauth-proxy アプローチは他の多くの OpenShift コンポーネントで使用されており、OpenShift が認証した、必要な権限を持つユーザーのみが要求を行えるようにします。oauth プロキシの統合方法の詳細については、ブログ記事を参照してください。
ingress ゲートウェイの oauth-proxy サイドカーが、認証されたユーザーの userid を持つ x-forwarded-user というヘッダーを作成するので (http のベストプラクティスに準拠)、そのヘッダーの値を kubeflow-userid という新しいヘッダーにコピーするには、変換ルール (EnvoyFilter CRとして実装) を ingress ゲートウェイに追加するだけです。また、oauth-proxy サイドカーは、Kubeflow 名前空間内の pod に対する GET パーミッション (ここで任意のパーミッションセットを設定して、Kubeflow ユーザーと Kubeflow 以外のユーザーを区別するために使用できます) を持つユーザーのみが通過できるように設定されています。
このアプローチにより、次のことを実現できます。
- すべての Kubeflow ユーザーは OpenShift ユーザーでもあります (逆は必ずしも真ではありません)。 エンタープライズ認証システムとの統合という点で、OCP 内で設定されたものを活用できます。そのため、このアプローチの可搬性は非常に高くなります。
- Kubeflow メッシュへの Ingress の手法は 1 つしかないため (Kubeflow Ingress ゲートウェイ保護を経由)、認証されたユーザーのみが Kubeflow サービスを活用できます。
Kubeflow Profile の作成を実現
Kubeflow は、ユーザーを適切に登録して処理するために Profile オブジェクト (CR) を必要とします。Profile オブジェクトの作成は、「登録」と呼ばれます。新規ユーザーが自己登録を行うこともできますが、今回は自動登録プロセスにしました。ユーザーが初めてログインすると、対応するプロファイルが自動的に作成されます。
OpenShift では、ユーザーが初めてログインしたときに User オブジェクトが作成されます。そのイベントをインターセプトして、Profile オブジェクトを作成することもできます。
Profile オブジェクトの作成を自動化するには、名前空間構成 Operator を使用できます。次の図は、ユーザーが OpenShift に初めてログインしたときに Profile オブジェクトを作成するイベントのシーケンスを示しています。

Kubeflow 名前空間を AI/ML サービスメッシュに追加する
Kubeflow の Profile オブジェクトを作成すると、Kubeflow は対応する Kubernetes 名前空間も作成し、クォータ、Istio RBAC ルール、サービスアカウントなど、新しい名前空間に複数のリソースを追加します。Kubeflow は名前空間がメッシュに属することを前提としていますが、OpenShift Service Mesh の場合はそうではなく、それぞれの名前空間は所定のメッシュ (複数存在することもあります) に明示的に追加する必要があります。この問題を解決するために、ここでも名前空間構成 Operator を使用して、今度は名前空間の作成時にトリガーされ、名前空間をメッシュに追加するルールを作成します。全体的なワークフローは次のとおりです。

このワークフローが正しく設定されていると、データサイエンティストがログインしたときに表示されるのは以下の画像のようになります。
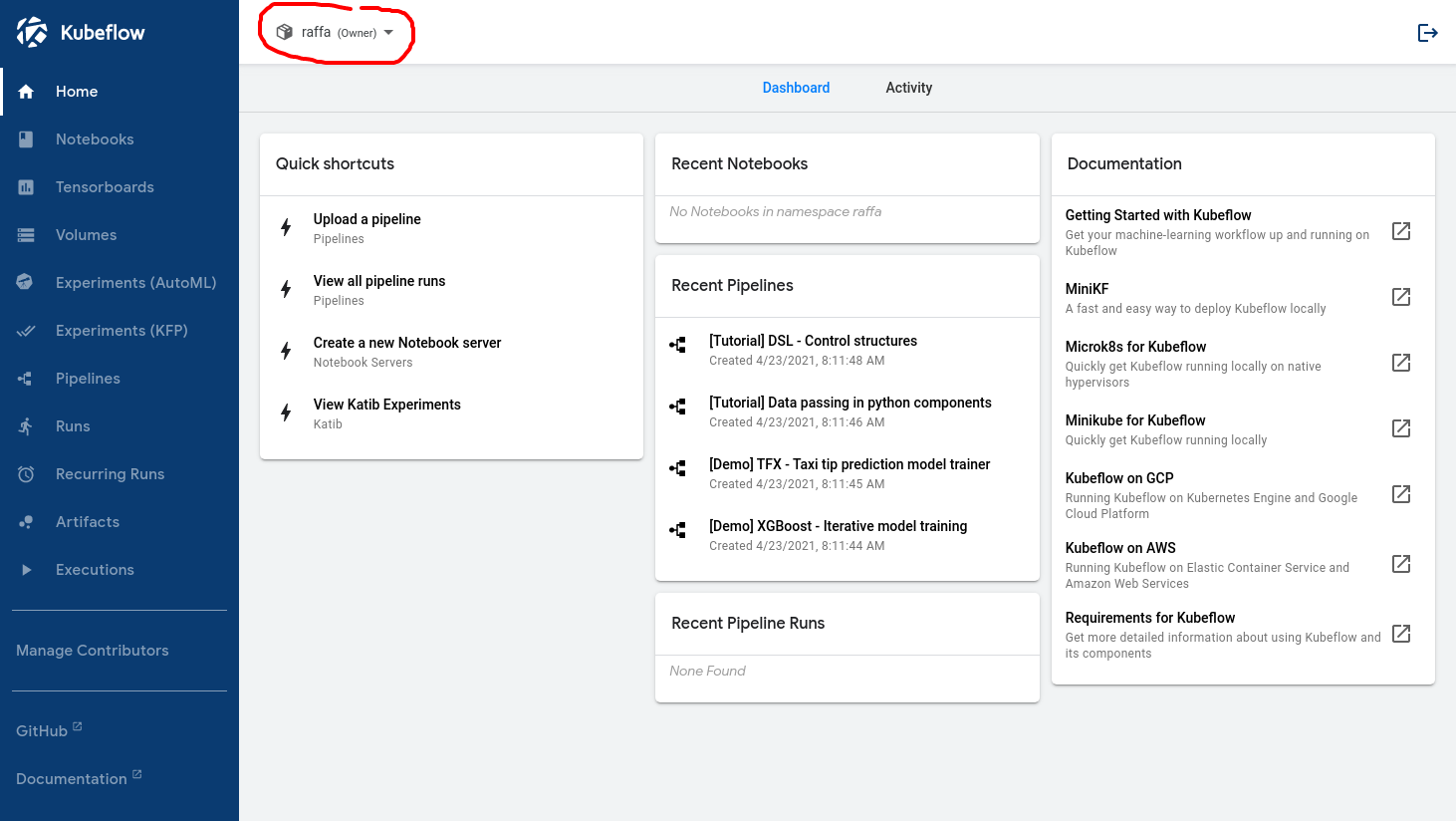
赤い円内の名前は、ユーザーが Kubeflow によって認識されたことを示しています。
GPU ノードとノード自動スケーリングの有効化
この時点で、データサイエンティストは Kubeflow のメインダッシュボードにログインし、提供されている機能を使用できます。AI/ML のユースケースの一部をサポートするために必要な機能の 1 つとして、GPU へのアクセス機能があります。
前提条件が満たされていれば、GPU ノードの有効化は簡単です。このプロセスについて、こちらのブログ記事で詳しく説明しています。
しかし、GPU ノードは高価なリソースなので、費用を最小限に抑えるためには次の 2 つの要件を満たす必要があります。
- AI/ML 関連のワークロードのみを GPU ノードで許可する
- より多くのリソースが必要な場合は GPU ノードを自動的にスケールアップし、リソースが不要になった場合はスケールダウンできるようにする
AI/ML ワークロードを通常のワークロードから分離する
クラスタに存在する可能性があり、GPU ノードを必要としない他のワークロードから AI/ML ワークロードを分離するには、テイントと許容範囲を使用できます。ここでは、デフォルトでワークロードがこれらのノードに到達するのを防ぐテイントを使用して GPU ノードを作成するだけです。
AI/ML 以外のテナントがテイントを容認するものとしてワークロードにタグ付けできないようにするため、次の名前空間アノテーションを使用できます。
scheduler.alpha.kubernetes.io/tolerationsWhitelist: '[]'
データサイエンティストの作業を単純化し、AI/ML 名前空間で実行されるワークロードに自動的に許容範囲を追加するために、次の名前空間アノテーションをすべての Kubeflow 名前空間に適用することができます。
scheduler.alpha.kubernetes.io/defaultTolerations: '[{"operator": "Equal", "effect": "NoSchedule", "key": "workload", "value": "ai-ml"}]'この例では、GPU 対応ノードに「workload: ai-ml」ラベルが付いています。
これらはアルファ版アノテーションで、現時点では Red Hat でサポートされていませんが、テストしたところ問題なく機能しました。
前述のように、Kubeflow はデータサイエンティストの初回ログイン時にデータサイエンティストの名前空間を作成します。名前空間の作成方法を制御することはできないため、正しいアノテーションが名前空間に適用されるようにプロセスを実装する必要があります。これはミューテーション Webhook 構成を使用して実行できます。この Webhook は名前空間の作成に割り込み、必要なアノテーションを追加します。使用したのは Open Policy Agent (OPA) と、OPA と Kubernetes を統合する Gatekeeper プロジェクトで、Gatekeeper Operator を介してデプロイしました。

ノードの自動スケーリングを有効にする
高価な GPU ノードの数を最小限に抑えるためには、AI/ML ノードで自動スケーリングを有効にする必要があります。
ノードの自動スケーリングは OpenShift ですぐに使える機能であり、公式ドキュメントの手順を使用して有効化できます。
ノードの自動スケーリング機能を使用する際、次の状況には改善が必要であることが明らかになりました。
1 つ目として、ノードの自動スケーラーは Pod が「保留」状態でスタックした場合にのみノードを追加する点です。ワークロードを開始しようとするユーザーは、ノードが作成されるまで (AWS では約 5 分)、また GPU ドライバーが使用可能になるまで (さらに約 3 - 4 分) 待機する必要があるため、この事後応答的な動作はユーザーエクスペリエンスの悪化につながります。この状況を改善するため、proactive-node-scaling-operator を使用しました (こちらのブログで説明しています)。
2 つ目は、GPU ノードを使用する場合、自動スケーラーは必要以上に多くのノードを作成する傾向があることです。これは、新しく作成されたノードは GPU に対応していないため、保留中の pod をすぐにスケジュールできないためです (GPU Operator が GPU カーネルドライバーのコンパイルや挿入などの初期化ステップを実行している間)。この問題に対処するには、こちらで説明しているとおり、特定のラベル (cluster-api/accelerator: "true") をノードテンプレートに追加する必要があります 。このラベルは、指定されたノードが特定の機能 (GPU のサポートなど) を有効にすることを意図していることを、それらが現在存在しない場合でも、ノードの自動スケーラーに通知します。
データレイクへのアクセスの有効化
データ構造と内部相関の可能性を理解するためのデータ探索、サンプルデータセットを介したニューラルネットワークモデルのトレーニング、モデルを提供できるようにするためのモデルの取得など、データサイエンティストが行う必要のあるほとんどすべてのタスクにおいて、データへのアクセスは重要です。AI/ML では、あらゆるタイプのデータ (リレーショナル、キー値、ドキュメント、ツリーなど) が含まれるデータリポジトリはデータレイクと呼ばれます。
特にマルチテナント環境では、データレイクへのアクセスを保護することが課題になることがあります。私たちはデータサイエンティストが習得すべき Kubernetes や認証情報管理に関する概念を最小限に抑えることで、データサイエンティストの負担を軽減したいと考えています。
このケースでは、データレイクは一連の AWS S3 バケットで構成されていました。別のストレージリポジトリタイプでも、同じ概念の多くを活用できます。
セキュリティチームはまた、データレイクへのアクセスに必要な認証情報は特定の個人ではなくワークロードを表すように求めていました。また、認証情報は一時的なものである必要があります。その目的は、紛失や悪用が起きる可能性がある静的な認証情報をデータサイエンティストに渡らないようにすることでした。
この問題を解決するために、バインドされたサービスアカウントトークンと OpenShift - STS 統合を使用し、後者をユーザーのワークロード用に転用しました。これら 2 つのテクノロジーをどのように組み合わせることができるかを見てみましょう。
バインドされたサービスアカウントトークンを使用すると、OpenShift に JWTトークンを生成させることができます。これはワークロードを表し、プロジェクトボリュームとしてマウントされます。他のワークロードに対するサービスアカウントトークンの仕組みと同様です。サービスアカウントトークンとは異なり、このトークンは短期的で (更新は Kubelet が担当)、 オーディエンスプロパティを定義することでカスタマイズできます。
STS は AWS サービスで (同様のサービスは他のクラウドプロバイダーにも存在します)、AWS から OIDC 認証プロバイダーなど他の認証システムへの信頼を確立できます。STS を設定することで、OpenShift によって生成された JWT トークンを信頼するように AWS に指示し、これらのトークンを特定のパーミッションセットで AWS トークンに交換することができます。交換が発生すると、pod で実行されているアプリケーションは AWS リソースの消費を開始できます。以下の図は、このアーキテクチャを示しています。

STS 統合の設定には、公式ドキュメントとこちらのブログが役立ちます。
このアプローチの要件の 1 つとして、AI/ML pod の実行に使用されるサービスアカウントに特定のアノテーションがアタッチされている必要があり、このアノテーションはこれらのワークロードには追加のバインドされたサービスアカウントトークンを必要であることを示すものです。これは、OPA を使用し、データサイエンティストの名前空間のサービスアカウントに必要なアノテーションを挿入して実行できます。
前述のセットアップによって、データサイエンティスト、さらに一般的に AI/ML ワークロードは特定の個人ではなくワークロードを代表する認証情報でデータレイクにアクセスできるようになり、またその認証情報は一時的なものです (そのためどこにも永続化する必要はありません)。さらに、これらはすべてデータサイエンティストに対して透過的に行われます。データサイエンティストにとって必要なのは、標準の AWS クライアント (STS 認証方式を認識する) を使用してデータレイクにアクセスすることだけです。
サーバーレスとの統合
モデルの提供に関して、Kubeflow でそれを実現するデフォルトの方法は Kfserving によるものです (他のアプローチもサポートされており、こちらで説明されています)。
Kfserving は Knative に基づいており、OpenShift では OpenShift Serverless をインストールすることで有効になります。
サービスメッシュとサーバーレスを使用する場合は、適切に統合するために複数の前提条件を満たす必要があるため注意する必要があります。
特に、NetworkPolicy ルールをすべてのサービスメッシュ名前空間で作成して、サーバーレス名前空間からメッシュ名前空間へのトラフィックを許可する必要があります。
さらに、マルチテナント Kubeflow エコシステムのすべてのメッシュサービスは Istio AuthorizationPolicies によって保護されており、サーバーレス・コンポーネントはメッシュの外部にあるため、サーバーレス名前空間 pod からの接続を許可するように RBAC ポリシーを変更する必要があります (具体的には Kourier と Activator)。

名前空間構成 Operator を使用してこれらのルールの作成を自動化し、データサイエンティストの名前空間の作成時に NetworkPolicy リソースと AuthorizationPolicy リソースを追加するように指示しました。
インストール
前述の各トピックの段階的なインストール手順と関連する設定については、こちらのリポジトリを参照してください。このチュートリアルには、他にも複数のマイナーな機能強化と、セットアップを検証するための AI/ML ワークロードの例が含まれています。
まとめ
この記事では、OpenShift で Kubeflow のマルチテナント・デプロイメントを設定するために必要な複数の検討事項を取り上げました。これは AI/ML 導入プロセスの第一歩に過ぎませんが、始めるにはこれで十分でしょう。データサイエンティスト・チームはここから、Jupyter Notebook を使用したデータの調査やデータパイプラインの作成を開始できます (これにはニューラルネットワークモデルのトレーニングを含めることができます)。ニューラルネットワーク・モデルが準備できたら、Kubeflow はモデル提供のユースケースにも役立ちます。
OpenShift での Kubeflow の実行は、現時点では Red Hat でサポートされていませんので、ご注意ください。また、Kubeflow は機能豊富な製品ですが、初期デプロイメントの一環としてすべての機能が正しく動作するかどうかは検証されていません (テスト済みの機能のリストはリポジトリで確認できます)。例として、残念ながら現時点では運用されていない重要な機能に、Kubeflow によって提供される可観測性スタック全体が挙げられます。ただしこれは後に統合される可能性があります。
これらが OpenShift 上で Kubeflow を実行することを検討している組織のスムーズな実行をサポートするものとなることを願っています。また言及した概念については、他の AI/ML プラットフォームを運用するときにも使用できる多くの一般的なプリミティブを提供するものとなるでしょう。
執筆者紹介

Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細
仮想化
オンプレミスまたは複数クラウドでのワークロードに対応するエンタープライズ仮想化の将来についてご覧ください