Kubeflow rassemble sur une plateforme plusieurs outils pour les principaux cas d'utilisation de l'intelligence artificielle (IA) et de l'apprentissage automatique (AA), à savoir l'exploration de données, les pipelines de données, ainsi que l'entraînement et le déploiement des modèles. Parce que les data scientists accèdent à ces fonctionnalités via un portail qui offre un haut niveau d'abstraction, ils n'ont pas besoin de savoir précisément comment Kubernetes s'intègre à chaque outil. Spécialement conçu pour s'exécuter sur Kubernetes, Kubeflow permet de mettre en œuvre la plupart des concepts clés de ce système d'orchestration, notamment le modèle d'opérateur. À l'exception du portail mentionné, Kubeflow est en réalité une collection d'opérateurs.
Cet article présente des configurations que nous avons adoptées dans le cadre d'une récente collaboration pour assurer le bon fonctionnement de Kubeflow (1.3 ou version ultérieure) dans un environnement OpenShift.
Particularités de l'architecture multi-client de Kubeflow
Kubeflow permet de répondre aux besoins d'un grand nombre de data scientists. Dans le cadre d'une approche d'architecture multi-client (entièrement disponible à partir de la version 1.3), un espace de noms Kubernetes est attribué à chaque data scientist (il existe également des mécanismes pour partager des artéfacts entre les espaces de noms, mais nous ne les avons pas encore testés).
Cette approche d'architecture multi-client doit être bien comprise, car la prise en charge de cette fonction sur OpenShift représente une part importante de la mise en œuvre de Kubeflow. L'utilisation d'un espace de noms par utilisateur plutôt que par application (une pratique habituelle avec OpenShift) peut nécessiter une réorganisation de l'authentification et de l'autorisation lors du déploiement d'OpenShift.
L'architecture multi-client de Kubeflow peut uniquement fonctionner correctement lorsqu'un utilisateur est authentifié et qu'un en-tête fiable (kubeflow-userid par défaut) est ajouté à toutes les requêtes. Kubeflow se charge du reste et crée l'espace de noms pour l'utilisateur, si ce n'est pas déjà fait.
L'architecture multi-client de Kubeflow repose également sur le concept de profil. Un profil est une ressource personnalisée qui représente l'environnement d'un utilisateur. Il est mappé à un espace de noms géré par Kubeflow. L'en-tête kubeflow-userid doit correspondre à un profil existant pour que Kubeflow achemine correctement les requêtes.
Une fois qu'un profil est établi et associé à un utilisateur, Kubeflow crée l'espace de noms correspondant que cet utilisateur devra exploiter.
Kubeflow est aussi étroitement intégré à Istio.Il est recommandé de les exécuter ensemble, car la sécurité de Kubeflow est basée sur les mécanismes d'Istio. Dans le cas où Istio est exécuté, l'architecture multi-client peut être simplement mise en œuvre en créant les espaces de noms à partir des profils Kubeflow qui appartiennent au Service Mesh, et en faisant circuler le trafic à travers une seule passerelle d'entrée.
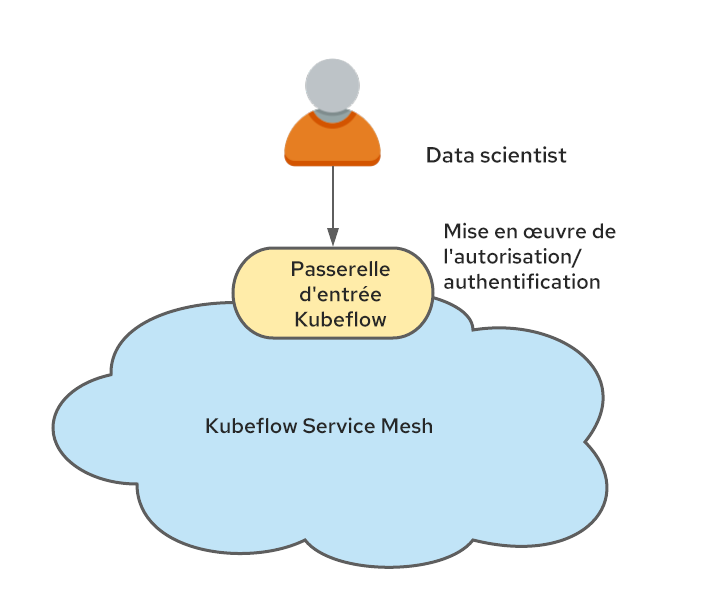
Ce point d'étranglement se met alors à authentifier les utilisateurs et à définir l'en-tête kubeflow-userid mentionné précédemment.
Intégration au Service Mesh
Contrairement à Istio qui étend le Service Mesh à tout le cluster Kubernetes, OpenShift Service Mesh permet d'utiliser plusieurs instances de Service Mesh dans un cluster OpenShift.
Dans notre configuration, nous avons décidé de réserver un Service Mesh aux cas d'utilisation de l'IA/AA. Seuls les espaces de noms d'IA/AA de Kubeflow appartiennent donc à ce Service Mesh.
Nous devions également tenir compte des différents ajouts et retraits de data scientists. C'est pourquoi nous avons adopté le modèle recommandé d'un profil/espace de noms par utilisateur.
En résumé, nous avons dû trouver des solutions pour répondre aux exigences suivantes :
- S'assurer que les connexions des data scientists sont authentifiées et que l'en-tête kubeflow-userid est ajouté à la requête de manière à éviter toute falsification
- S'assurer que des profils Kubeflow sont créés pour chaque data scientist
- S'assurer que les espaces de noms Kubeflow créés par Kubeflow à la suite de la création d'un profil appartiennent au Service Mesh réservé à l'IA/AA
Garantir l'authentification des data scientists
Comme nous l'avons vu précédemment, Kubeflow utilise un en-tête pour représenter l'utilisateur connecté. Étant donné que le changement du nom kubeflow-userid implique des modifications à plusieurs emplacements, nous avons décidé qu'il serait plus simple de continuer à utiliser le nom d'en-tête par défaut.
Voici l'une des nombreuses façons d'injecter cet en-tête :
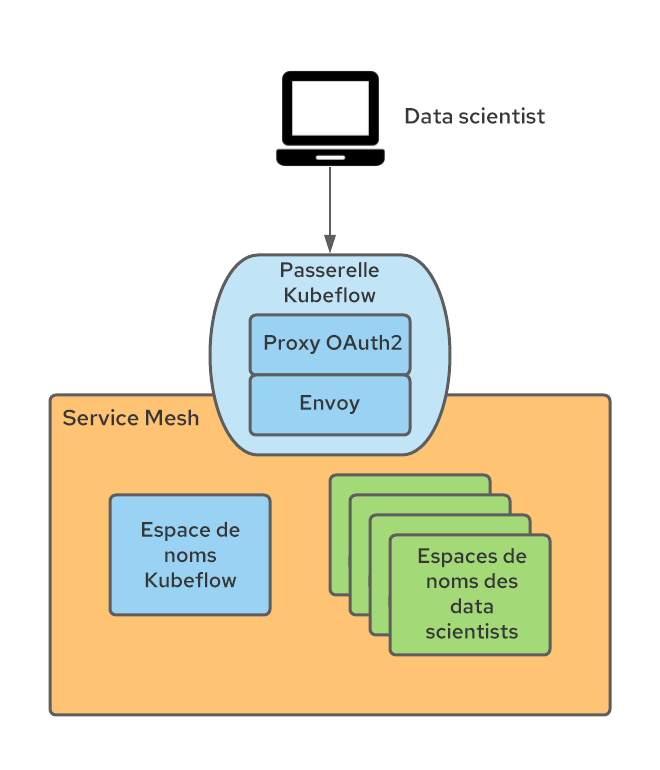
Kubeflow publie ses services externes sur une passerelle d'entrée Istio (appelée par défaut Kubeflow). Nous avons donc utilisé cette passerelle pour mettre en œuvre l'authentification à l'aide d'un proxy OAuth qui redirige les utilisateurs non authentifiés vers le flux de connexion OpenShift. Ce proxy est utilisé par de nombreux autres composants OpenShift et limite l'envoi de requêtes aux utilisateurs authentifiés d'OpenShift disposant des autorisations nécessaires. Vous trouverez plus d'informations sur l'intégration du proxy OAuth dans cet article de blog.
Le sidecar oauth-proxy dans la passerelle d'entrée crée un en-tête appelé x-forwarded-user avec le paramètre userid de l'utilisateur authentifié (selon les meilleures pratiques HTTP). Il suffit donc d'ajouter une règle de transformation (mise en œuvre en tant que ressource personnalisée EnvoyFilter) sur la passerelle d'entrée pour copier la valeur de cet en-tête dans un nouvel en-tête appelé kubeflow-userid. En outre, la configuration du sidecar oauth-proxy accepte uniquement les utilisateurs disposant de l'autorisation GET sur les pods des espaces de noms Kubeflow (l'ensemble d'autorisations souhaité peut y être configuré pour différencier les utilisateurs Kubeflow et autres).
Cette approche permet d'obtenir les résultats suivants :
- Tous les utilisateurs Kubeflow sont également des utilisateurs OpenShift (l'inverse n'est pas nécessairement vrai). Nous pouvons réutiliser l'intégration configurée dans OpenShift Container Platform (OCP) avec le système d'authentification d'entreprise. Cette méthode offre une excellente portabilité.
- Parce qu'il n'existe qu'une méthode d'entrée dans le Service Mesh de Kubeflow (via la protection de la passerelle d'entrée de Kubeflow), nous garantissons que seuls les utilisateurs authentifiés peuvent utiliser les services Kubeflow.
Garantir la création de profils Kubeflow
Kubeflow nécessite un profil, ou objet Profile (ressource personnalisée) pour enregistrer et gérer correctement un utilisateur. L'opération de création d'un objet Profile est appelée « enregistrement ».Les nouveaux utilisateurs peuvent être autorisés à s'auto-enregistrer, mais nous avons opté pour un processus d'enregistrement automatique : lorsqu'un utilisateur se connecte pour la première fois, le profil correspondant est automatiquement créé.
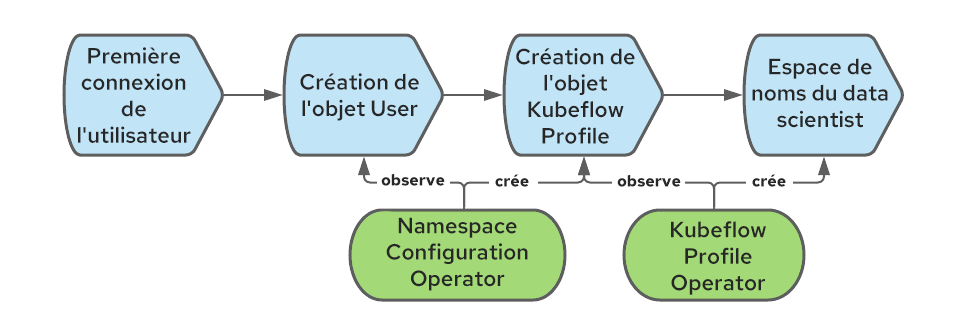
Dans OpenShift, un objet User est créé lors de la première connexion d'un utilisateur. Nous pouvons intercepter cet événement pour créer également l'objet Profile.
Pour automatiser la création de l'objet Profile, nous pouvons utiliser l'opérateur Namespace Configuration Operator. Le schéma suivant illustre le processus de création de l'objet Profile lorsqu'un utilisateur se connecte pour la première fois à OpenShift :
Associer les espaces de noms Kubeflow au Service Mesh réservé à l'IA/AA
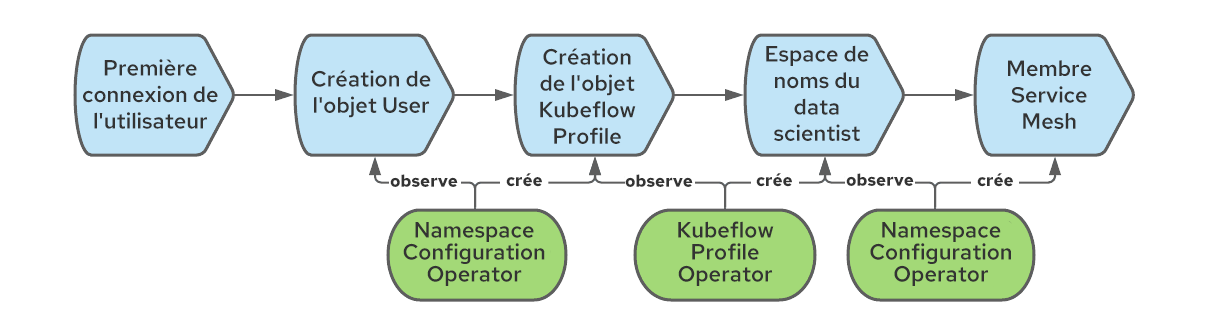
Dans Kubeflow, la création d'un objet Profile entraîne celle de l'espace de noms Kubernetes correspondant et l'ajout de plusieurs ressources au nouvel espace de noms, telles que des quotas, des règles de contrôle d'accès basé sur les rôles (RBAC) Istio et des comptes de service. Kubeflow attribue par défaut les espaces de noms au Service Mesh, ce qui n'est pas le cas pour OpenShift Service Mesh, où chaque espace de noms doit être explicitement associé à un Service Mesh donné (plusieurs instances peuvent être déployées). Pour résoudre ce problème, il est possible d'utiliser à nouveau l'opérateur Namespace Configuration Operator afin de créer une règle qui les intègre au Service Mesh lors de leur création. Voici les détails de l'ensemble du workflow :
Une fois ce workflow correctement configuré, voici ce qu'un data scientist doit voir lorsqu'il se connecte :
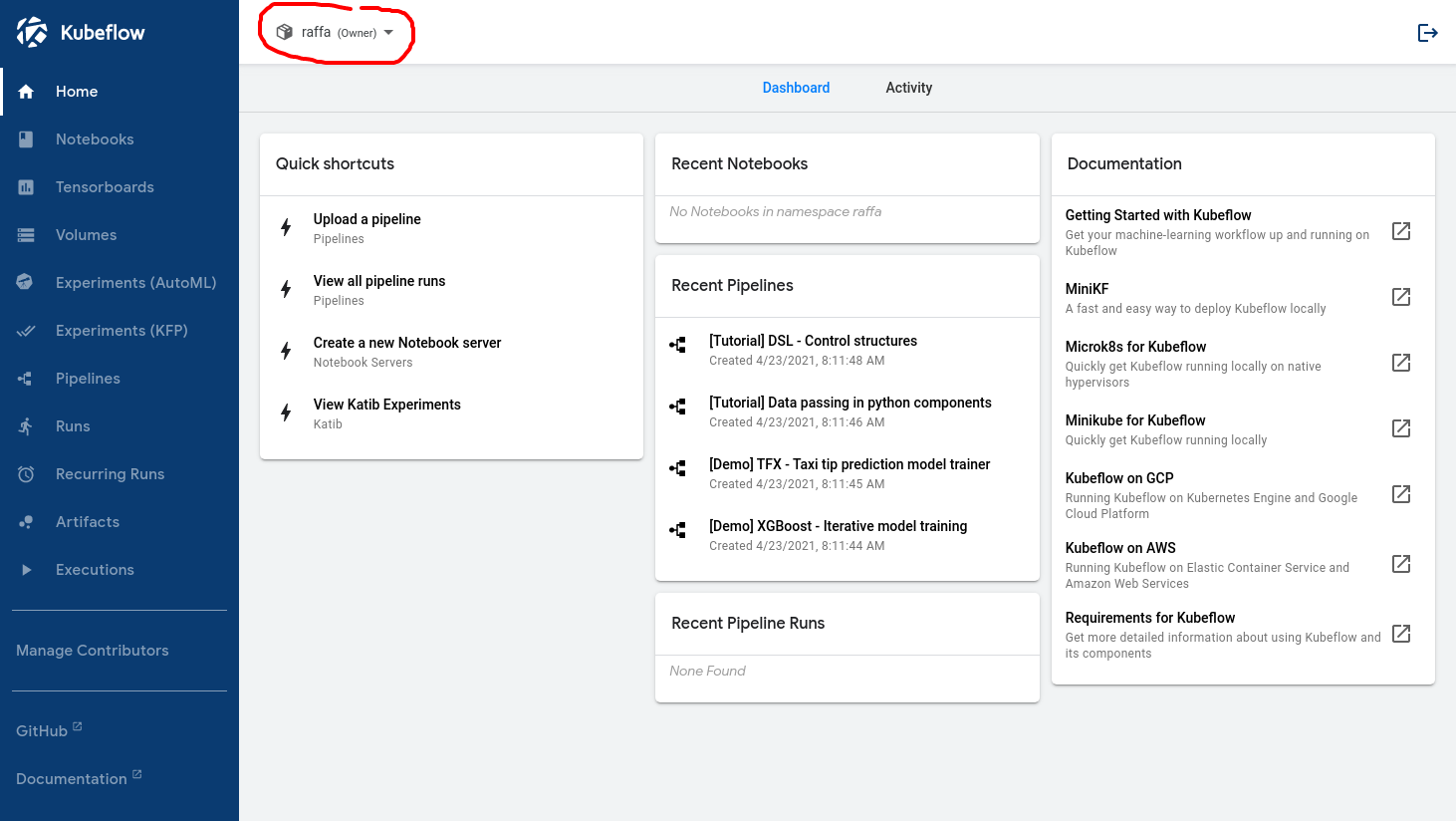
Le nom entouré en rouge confirme que l'utilisateur a bien été reconnu par Kubeflow.
Activer les nœuds GPU et la mise à l'échelle automatique des nœuds
À ce stade, les data scientists peuvent se connecter au tableau de bord principal de Kubeflow et commencer à utiliser les fonctionnalités proposées. Pour prendre en charge plusieurs cas d'utilisation de l'IA/AA, il est nécessaire d'accéder aux processeurs graphiques (GPU).
L'activation des nœuds GPU est simple, à condition de respecter les prérequis. Apprenez-en plus sur ce processus dans cet article de blog.
Cependant, les nœuds GPU sont des ressources coûteuses. Deux conditions permettent de limiter les dépenses :
- Seules les charges de travail liées à l'IA/AA doivent être autorisées sur les nœuds GPU.
- Les nœuds GPU doivent pouvoir évoluer automatiquement en fonction de la quantité de ressources nécessaire.
Séparer les charges de travail d'IA/AA des charges de travail normales
Si le cluster contient des charges de travail qui ne nécessitent pas de nœud GPU, il est possible de les séparer des charges de travail d'IA/AA en utilisant les concepts de rejet (taint) et de tolérance (toleration).Il suffit de créer les nœuds GPU avec un rejet qui empêchera par défaut l'arrivée des charges de travail sur ces nœuds.
Pour que les clients n'utilisant pas l'IA/AA ne considèrent pas que les charges de travail tolèrent le rejet, l'annotation d'espace de noms suivante peut être ajoutée :
scheduler.alpha.kubernetes.io/tolerationsWhitelist: '[]'
Pour simplifier la tâche du data scientist et ajouter automatiquement la tolérance aux charges de travail qui s'exécutent dans les espaces de noms d'IA/AA, l'annotation d'espace de noms suivante peut être ajoutée à tous les espaces de noms Kubeflow :
scheduler.alpha.kubernetes.io/defaultTolerations: '[{"operator": "Equal", "effect": "NoSchedule", "key": "workload", "value": "ai-ml"}]'Dans cet exemple, les nœuds compatibles avec le GPU ont été étiquetés avec l'annotation « workload: ai-ml ».
Il s'agit d'annotations alphabétiques actuellement non prises en charge par Red Hat, mais d'après nos tests, elles fonctionnent très bien.
Comme indiqué précédemment, Kubeflow crée des espaces de noms pour les data scientists lors de leur première connexion. Étant donné que nous ne contrôlons pas la manière dont les espaces de noms sont créés, un processus doit être mis en œuvre pour que les annotations correctes soient appliquées à l'espace de noms. Pour ce faire, il est possible d'utiliser une configuration de webhook de mutation. Ce webhook peut intercepter la création de l'espace de noms et ajouter les annotations nécessaires. Nous avons utilisé Open Policy Agent (OPA) avec le projet Gatekeeper qui intègre OPA à Kubernetes, et nous l'avons déployé via l'opérateur Gatekeeper.
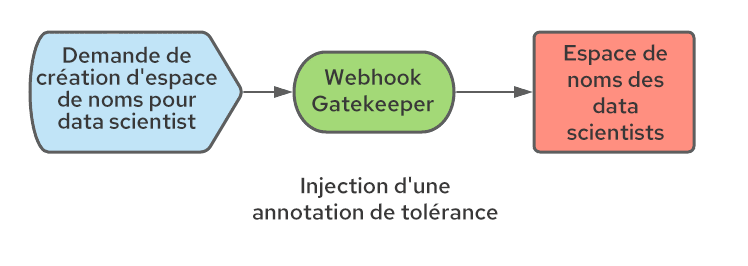
Activer la mise à l'échelle automatique des nœuds
Pour limiter le nombre de nœuds GPU coûteux, il faut activer la mise à l'échelle automatique des nœuds d'IA/AA.
Cette fonction prête à l'emploi d'OpenShift peut être activée en suivant les étapes de la documentation officielle.
L'utilisation de la mise à l'échelle automatique des nœuds a mis en évidence la nécessité d'améliorer les situations suivantes :
Premièrement, l'outil de mise à l'échelle automatique des nœuds ajoute des nœuds uniquement lorsque les pods restent bloqués à l'état « en attente ». Ce comportement réactif dégrade l'expérience des utilisateurs qui tentent de démarrer des charges de travail, car ils doivent attendre la création des nœuds (environ 5 minutes sur AWS) et la mise à disposition des pilotes GPU (environ 3 à 4 minutes supplémentaires). Pour améliorer cette situation, nous avons utilisé l'opérateur proactive-node-scaling-operator (présenté dans cet article de blog).
Deuxièmement, lorsque des nœuds GPU sont utilisés, l'outil de mise à l'échelle automatique a tendance à créer plus de nœuds que nécessaire. Les nouveaux nœuds ne peuvent pas ordonnancer immédiatement les pods en attente, car ils ne sont pas conçus pour fonctionner avec le GPU (alors que l'opérateur GPU effectue des étapes d'initialisation, telles que la compilation et l'injection de pilotes de noyau de GPU). Pour résoudre ce problème, une étiquette spécifique (cluster-api/accelerator: "true") doit être ajoutée au modèle de nœud, comme expliqué ici. Cette étiquette informe l'outil de mise à l'échelle automatique que certaines fonctions (telles que la prise en charge des GPU) doivent être activées sur un nœud donné, même si elles ne sont pas initialement présentes.
Activation de l'accès au data lake
Pour la plupart de leurs tâches, les data scientists doivent pouvoir accéder aux données, que ce soit pour comprendre leur structure et les corrélations internes possibles, entraîner des modèles de réseau neuronal avec des ensembles de données types ou récupérer des modèles pour les distribuer. Dans le domaine de l'IA/AA, le référentiel de données qui contient des données de tous types (relationnelles, valeurs clés, documents, arborescences, etc.) est appelé data lake.
La sécurisation de l'accès à ce data lake peut être un défi, surtout dans un environnement multi-client. Il faut par ailleurs faciliter la tâche des data scientists en limitant le nombre de concepts à maîtriser autour de Kubernetes et de la gestion des informations d'identification.
Dans notre cas, le data lake se composait d'un ensemble de compartiments S3 AWS. D'autres types de référentiels de stockage peuvent tirer parti de ces mêmes concepts.
L'équipe de sécurité souhaitait également que les informations d'identification requises pour accéder au data lake représentent une charge de travail plutôt qu'un utilisateur spécifique. Ces informations devaient aussi avoir une courte durée de vie. Le but était d'éviter de distribuer aux data scientists des informations d'identification statiques qui pourraient être perdues ou mal utilisées.
Nous avons donc utilisé des jetons de compte de service liés et l'intégration entre OpenShift et STS, en réaffectant STS aux charges de travail utilisateur.Voyons comment ces deux technologies peuvent être associées.
Avec les jetons de compte de service liés, il est possible d'utiliser OpenShift pour générer un jeton JWT qui représente la charge de travail et est monté en tant que volume projeté, de la même façon que les jetons de compte de service pour toute autre charge de travail. Contrairement aux jetons de compte de service non liés, ce jeton a une courte durée de vie (le Kubelet est chargé de l'actualiser) et peut être personnalisé en définissant sa propriété audience.
Le service STS d'AWS (d'autres fournisseurs de cloud proposent des services similaires) permet d'établir une relation de confiance entre AWS et d'autres systèmes d'authentification, notamment OIDC. Avec la configuration de STS, il est possible de demander à AWS de faire confiance aux jetons JWT créés par OpenShift et de les échanger contre des jetons AWS avec un ensemble d'autorisations spécifique. Une fois l'échange effectué, l'application exécutée dans un pod peut commencer à utiliser des ressources AWS. Le schéma ci-dessous illustre cette architecture :
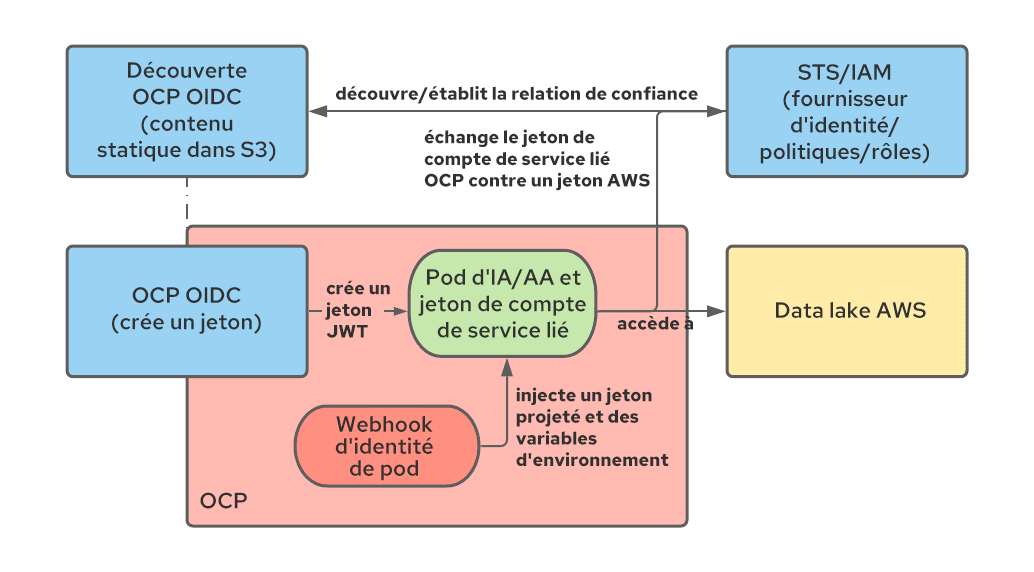
Pour en savoir plus sur la configuration de l'intégration de STS, vous pouvez consulter la documentation officielle et cet article de blog.
Cette approche exige notamment que les comptes de service utilisés pour exécuter les pods d'IA/AA aient des annotations spécifiques qui indiquent que ces charges de travail nécessitent le jeton de compte de service lié supplémentaire. Pour ce faire, nous utilisons OPA et injectons les annotations nécessaires dans les comptes de service des espaces de noms des data scientists.
La configuration décrite précédemment permet aux data scientists et aux charges de travail d'IA/AA d'accéder au data lake à l'aide d'informations d'identification qui représentent la charge de travail (plutôt qu'un utilisateur en particulier) et qui ont une courte durée de vie (donc sans conservation nécessaire). De plus, les data scientists profitent d'un processus transparent. Ils ont simplement besoin d'utiliser un client AWS standard (compatible avec la méthode d'authentification STS) pour accéder au data lake.
Intégration à OpenShift Serverless
Par défaut, Kubeflow utilise Kfserving pour distribuer un modèle (il existe d'autres méthodes décrites ici).
Kfserving repose sur la fonction Knative, qui peut être activée dans OpenShift en installant OpenShift Serverless.
La bonne intégration de Service Mesh et de Serverless dépend de certaines conditions préalables.
Une règle NetworkPolicy doit notamment être créée dans chaque espace de noms Service Mesh pour autoriser le trafic depuis les espaces de noms Serverless vers les espaces de noms du Service Mesh.
En outre, dans la mesure où tous les services du Service Mesh d'un écosystème Kubeflow multi-client sont protégés par Istio Authorization Policy et où les composants Serverless sont externes au Service Mesh, il faut modifier les politiques RBAC pour autoriser les connexions à partir des pods des espaces de noms Serverless (en particulier Kourier et Activator) :
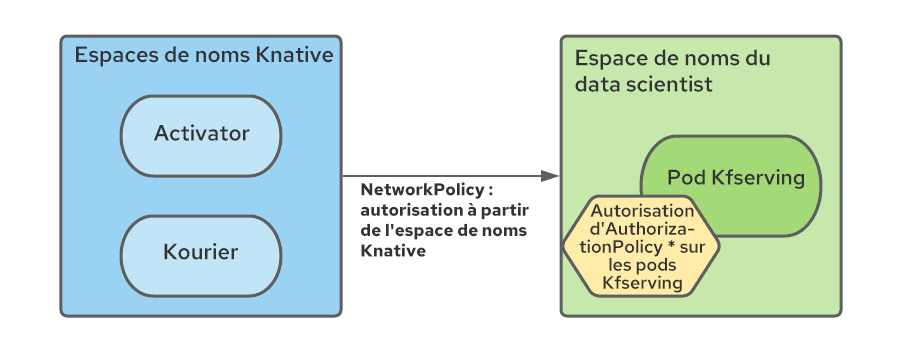
Nous avons automatisé la création de ces règles à l'aide de l'opérateur Namespace Configuration Operator, en lui indiquant d'ajouter les ressources NetworkPolicy et AuthorizationPolicy lors de la création de l'espace de noms du data scientist.
Installation
Les instructions d'installation pour chacune des rubriques ci-dessus, ainsi que les configurations associées, sont disponibles dans ce référentiel. Ce guide contient également plusieurs autres améliorations mineures et quelques exemples de charges de travail d'IA/AA pour valider la configuration.
Conclusion
Dans cet article, nous avons abordé plusieurs éléments à prendre en compte pour configurer un déploiement multi-client de Kubeflow sur OpenShift. Il s'agit de la première étape pour adopter l'IA/AA. Les data scientists peuvent ensuite commencer à explorer les données à l'aide des notebooks Jupyter et à créer des pipelines de données qui peuvent inclure l'entraînement de modèles de réseaux neuronaux. Lorsque ces modèles sont prêts, Kubeflow peut également faciliter leur distribution.
Pour le moment, Red Hat ne prend pas en charge l'exécution de Kubeflow sur OpenShift. Dans le cadre de ce déploiement initial, nous n'avons pas encore vérifié que toutes les fonctions du produit s'exécutent correctement (la liste des fonctionnalités qui ont été testées figure dans le référentiel). Par exemple, Kubeflow fournit une pile d'observabilité complète qui n'est pas mise en œuvre à ce jour, mais qui pourrait être intégrée ultérieurement.
Nous espérons que ce type de travail pourra servir de base pour les entreprises qui souhaitent exécuter Kubeflow sur OpenShift. En outre, ces concepts devraient fournir des éléments essentiels courants qui peuvent être utilisés pour la mise en œuvre d'autres plateformes d'IA/AA.
À propos de l'auteur

Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
Parcourir par canal

Automatisation
Les dernières nouveautés en matière d'automatisation informatique pour les technologies, les équipes et les environnements

Intelligence artificielle
Actualité sur les plateformes qui permettent aux clients d'exécuter des charges de travail d'IA sur tout type d'environnement

Cloud hybride ouvert
Découvrez comment créer un avenir flexible grâce au cloud hybride

Sécurité
Les dernières actualités sur la façon dont nous réduisons les risques dans tous les environnements et technologies

Edge computing
Actualité sur les plateformes qui simplifient les opérations en périphérie

Infrastructure
Les dernières nouveautés sur la plateforme Linux d'entreprise leader au monde

Applications
À l’intérieur de nos solutions aux défis d’application les plus difficiles
Virtualisation
L'avenir de la virtualisation d'entreprise pour vos charges de travail sur site ou sur le cloud