Kubeflow ist eine KI/ML-Plattform (Künstliche Intelligenz/Maschinelles Lernen), die mehrere Tools für die wichtigsten KI/ML-Use Cases vereint: Datenexploration, Daten-Pipelines, Modelltraining und Modellbereitstellung. Mit Kubeflow können Data Scientists auf diese Funktionen über ein Portal zugreifen, das allgemeine Abstraktionen für die Interaktion mit diesen Tools bereitstellt. Das heißt, dass sich Data Scientists nicht mit der Integration von Kubernetes in jedes dieser Tools beschäftigen müssen. Kubeflow wurde jedoch speziell für die Ausführung auf Kubernetes entwickelt und umfasst viele der Schlüsselkonzepte, darunter das Operator-Modell. Mit Ausnahme des bereits erwähnten Portals ist Kubeflow tatsächlich eine Sammlung von Operatoren.
In diesem Artikel werden eine Reihe von Konfigurationen untersucht, die wir kürzlich in einem Kunden-Engagement eingeführt haben, damit Kubeflow (1.3 oder höher) in einer OpenShift-Umgebung gut funktioniert.
Überlegungen zur Mandantenfähigkeit von Kubeflow
Einer der Use Cases für Kubeflow ist die Bereitstellung von Services für eine große Anzahl an Data Scientists. Kubeflow erreicht dies durch die Einführung eines Ansatzes zur Mandantenfähigkeit (vollständig verfügbar ab Release 1.3), bei dem die einzelnen Data Scientists jeweils einen Kubernetes-Namespace erhalten, um darin zu arbeiten (es gibt auch Mechanismen zum Teilen von Artefakten in verschiedenen Namespaces, aber diese wurden zu diesem Zeitpunkt noch nicht untersucht).
Das Verständnis dieses Ansatzes zur Mandantenfähigkeit ist wichtig, da ein erheblicher Teil der Kubeflow-Operationalisierung in die Unterstützung dieser Funktion in OpenShift investiert wurde. Bei einem Namespace pro Nutzendem im Vergleich zu einem Namespace pro Anwendung (was beim Deployment von OpenShift das gängigere Muster ist) ist beim Deployment von OpenShift möglicherweise eine gewisses Redesign erforderlich. Dies hängt davon ab, wie die Authentifizierung/Autorisierung organisiert ist.
Damit die Mandantenfähigkeit bei Kubeflow ordnungsgemäß funktioniert, müssen die Nutzenden authentifiziert werden, und allen Anfragen muss ein vertrauenswürdiger Header (standardmäßig „kubeflow-userid“, ist jedoch konfigurierbar) hinzugefügt werden. Kubeflow erstellt dann den Namespace für den Nutzenden, falls er noch nicht vorhanden ist.
Der andere Aspekt der Mandantenfähigkeit bei Kubeflow ist das Konzept eines Profils. Ein Profil ist eine benutzerdefinierte Ressource (Custom Resource, CR), welche die Umgebung eines Benutzers repräsentiert. Ein Profil wird einem Namespace zugeordnet, den Kubeflow verwaltet. Der Header „kubeflow-userid“ muss mit einem vorhandenen Profil übereinstimmen, damit Kubeflow die Anfragen ordnungsgemäß weiterleitet.
Sobald ein Profil erstellt und einem Nutzenden zugeordnet wurde, erstellt Kubeflow den entsprechenden Namespace, in dem alle nachfolgenden Aktivitäten dieses Nutzenden stattfinden.
Kubeflow ist außerdem stark in Istio integriert.Zwar besteht keine feste Anforderung für die Ausführung von Istio mit Kubeflow, dies wird jedoch empfohlen, da die Kubeflow-Sicherheit auf Istio-Konstrukten basiert. Bei der Ausführung mit Istio besteht einer der einfachsten Ansätze zur Unterstützung der Mandantenfähigkeit darin, die Namespaces als Ergebnis der Zugehörigkeit von Kubeflow-Profilen zum Service Mesh und eines einzelnen Ingress Gateways zu erstellen, durch das der gesamte Datenverkehr fließt.
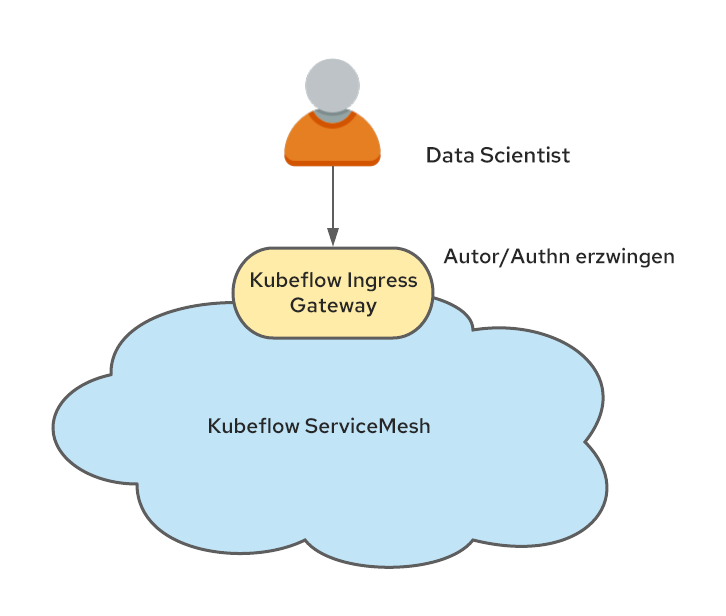
Dieser Engpass wird zum natürlichen Kandidaten für die Authentifizierung der Nutzenden und das Festlegen des zuvor erwähnten Headers kubeflow-userid.
Integration mit Service Mesh
OpenShift Service Mesh unterscheidet sich von Istio dahingehend, dass ein OpenShift-Cluster mehrere Service Meshes enthalten kann, während bei Upstream-Istio impliziert wird, dass das Mesh auf den gesamten Kubernetes-Cluster erweitert wird.
In unserem Setup haben wir uns entschieden, ein Service Mesh vollständig den KI/ML-Use Cases zu widmen. Vor diesem Hintergrund gehören nur die Kubeflow-KI/ML-Namespaces zu diesem dedizierten KI/ML-Service-Mesh.
Wir mussten auch dafür sorgen, dass das Hinzufügen und Entfernen von Data Scientists jederzeit möglich war. Dies führte zu der Entscheidung, das empfohlene Modell von einem Profil/Namespace pro Nutzendem zu übernehmen.
Zusammenfassend mussten wir Lösungen für die folgenden Anforderungen finden:
- Sicherstellen, dass Data Scientist-Verbindungen authentifiziert werden und der Header „kubeflow-userid“ manipulationssicher zur Anfrage hinzugefügt wird.
- Sicherstellen, dass Kubeflow-Profile für jeden Data Scientist erstellt werden.
- Sicherstellen, dass die von Kubeflow als Ergebnis der Profilerstellung erstellten Kubeflow-Namespaces zum KI/ML-Service Mesh gehören.
Sicherstellen der Authentifizierung für Data Scientists
Wie bereits erwähnt, verwendet Kubeflow einen Header für verbundene Nutzende. Es gibt zwar Optionen zum Ändern des Standard-Headernamens „kubeflow-userid“, dies erfordert jedoch Änderungen an mehreren Stellen. Daher haben wir uns entschieden, dass es einfacher wäre, den Standardnamen beizubehalten.
Zum Injizieren dieses Headers gibt es verschiedene Möglichkeiten. Im Folgenden wird ein möglicher Ansatz beschrieben:
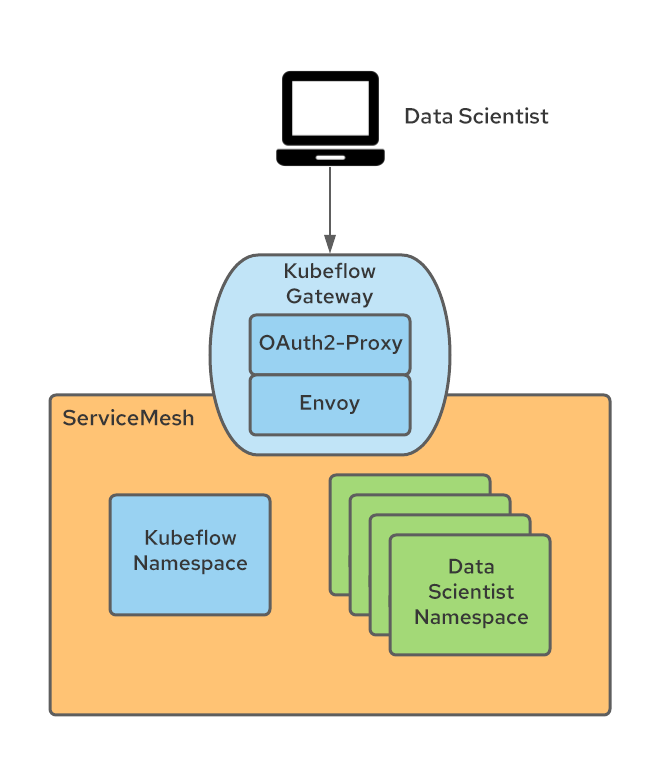
Unter Ausnutzung der Tatsache, dass Kubeflow seine externen Services auf einem Istio Ingress Gateway (standardmäßig Kubeflow genannt) veröffentlicht, wurde das Gateway so instrumentiert, dass es die Authentifizierung mit einem OAuth-Proxy erzwingt, der nicht authentifizierte Nutzende zum OpenShift-Anmeldungs-Flow umleitet. Dieser OAuth-Proxy-Ansatz wird von vielen anderen OpenShift-Komponenten verwendet und erzwingt, dass nur authentifizierte OpenShift-Nutzende mit den erforderlichen Berechtigungen Anfragen senden können. Weitere Informationen zur Integration des OAuth-Proxys finden Sie in diesem Blog-Beitrag.
Das OAuth-Proxy-Sidecar im Ingress Gateway erstellt einen Header namens „x-forwarded-user“ mit der „userid“ des authentifizierten Nutzenden (gemäß den HTTP-Best Practices). Wir müssen also nur auf dem Ingress Gateway eine Transformationsregel hinzufügen (implementiert als EnvoyFilter-CR), um den Wert dieses Headers in einen neuen Header mit dem Namen „kubeflow-userid“ zu kopieren. Außerdem ist das OAuth-Proxy-Sidecar so konfiguriert, dass nur Nutzende mit der GET-Berechtigung für Pods in den Kubeflow-Namespaces (hier können beliebige Berechtigungssätze konfiguriert werden, mit denen zwischen Kubeflow-Nutzenden und Nicht-Kubeflow-Nutzenden unterschieden werden kann) zugelassen werden.
Mit diesem Ansatz wird Folgendes erreicht:
- Nutzende von Kubeflow sind auch Nutzende von OpenShift (beachten Sie, dass das Gegenteil nicht unbedingt der Fall ist). Wir können das nutzen, was in OCP im Hinblick auf die Integration mit dem Authentifizierungssystems des Unternehmens konfiguriert wurde. So wird dieser Ansatz sehr portierbar.
- Da es nur eine Ingress-Methode in das Kubeflow-Mesh gibt (über den Kubeflow Ingress Gateway-Schutz), garantieren wir, dass nur authentifizierte Nutzende die Kubeflow-Services nutzen können.
Sicherstellen der Erstellung von Kubeflow-Profilen
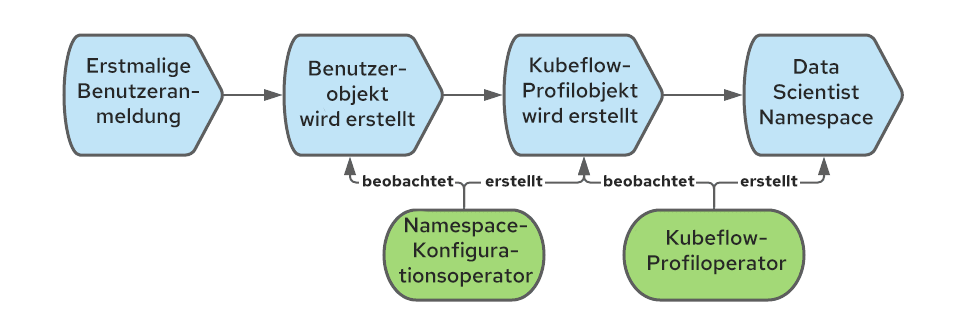
Kubeflow benötigt ein Profilobjekt (CR), um einen Benutzer korrekt zu registrieren und zu verarbeiten. Die Erstellung des Profilobjekts wird als „Registrierung“ bezeichnet.Neue Benutzer können sich selbst registrieren, aber wir haben uns für einen automatischen Registrierungsprozess entschieden: Wenn sich ein Benutzer zum ersten Mal anmeldet, wird automatisch das entsprechende Profil erstellt.
In OpenShift wird ein Benutzerbjekt erstellt, wenn sich Nutzende zum ersten Mal anmelden. Wir können dieses Event abfangen, um das Profilobjekt zu erstellen.
Mit dem Namespace-Konfigurationsoperator können wir die Erstellung des Profilobjekts automatisieren. Nachfolgend ist die Sequenz der Events dargestellt, mit denen das Profilobjekt erstellt wird, wenn sich ein Nutzender zum ersten Mal bei OpenShift anmeldet:
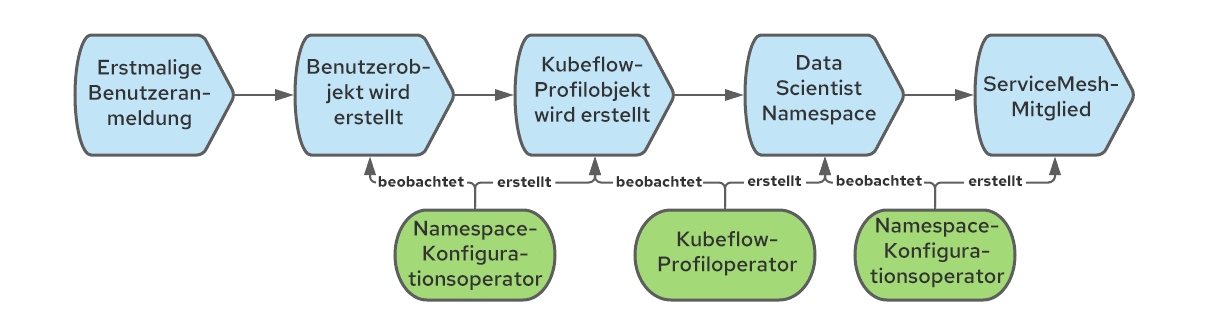
Verbinden von Kubeflow-Namespaces mit dem KI/ML-Service Mesh
Wenn wir ein Kubeflow-Profilobjekt erstellen, erstellt Kubeflow auch den entsprechenden Kubernetes-Namespace und fügt dem neuen Namespace verschiedene Ressourcen hinzu, wie Quotas, Istio RBAC-Regeln und Service Accounts. Kubeflow geht davon aus, dass Namespaces zum Mesh gehören. Dies ist jedoch bei OpenShift Service Mesh nicht der Fall, da jeder Namespace explizit mit einem bestimmten Mesh verbunden werden muss (es können mehrere vorhanden sein). Zur Lösung dieses Problems können wir wieder den Namespace-Konfigurationsoperator verwenden und dieses Mal eine Regel erstellen, die bei der Erstellung von Namespaces ausgelöst wird und sie veranlasst, sich mit dem Mesh zu verbinden. Der vollständige Workflow umfasst Folgendes:
Die folgende Abbildung zeigt, was ein Data Scientist bei der Anmeldung sehen sollte, wenn dieser Workflow korrekt eingerichtet ist:
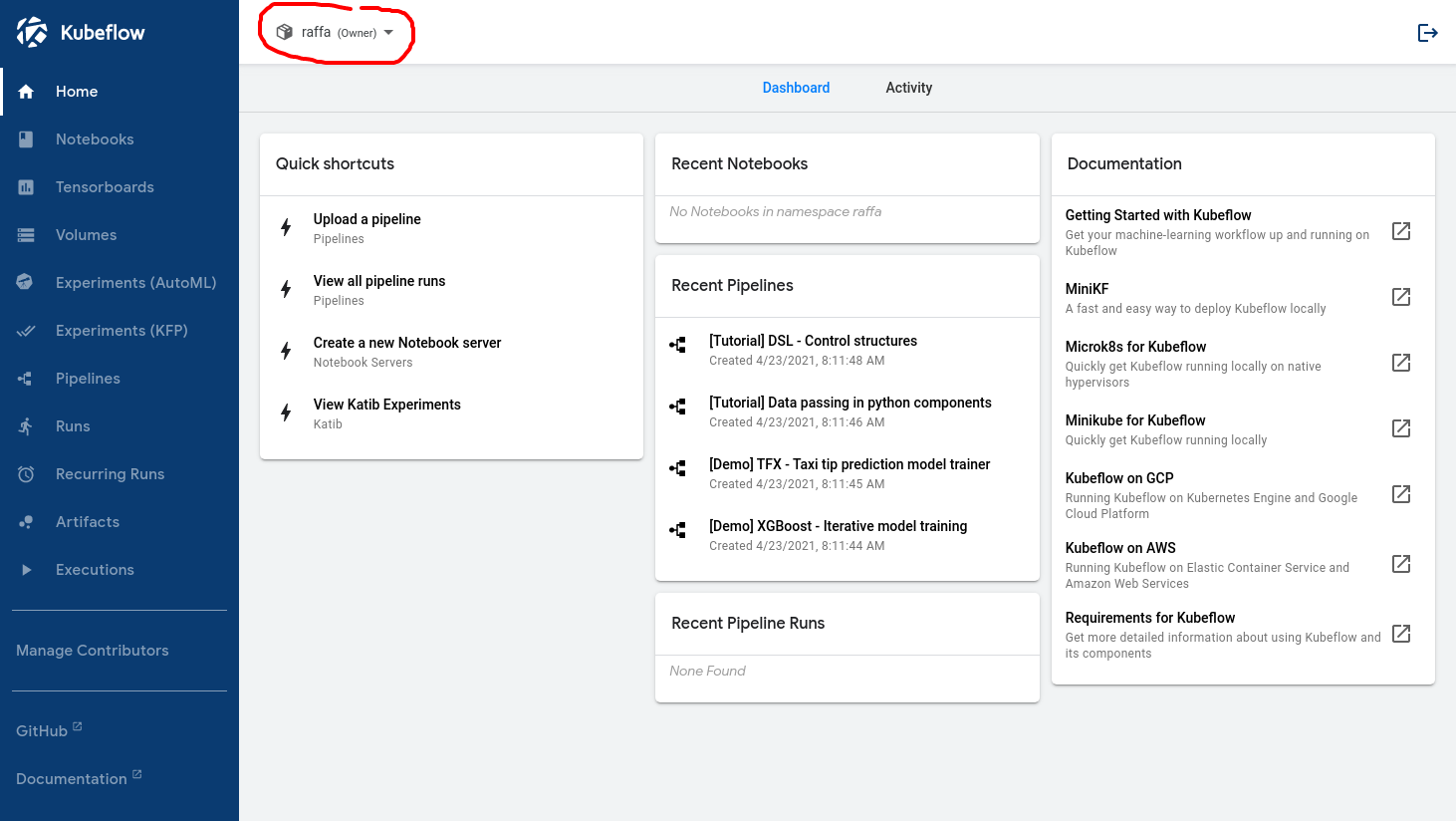
Der Name im roten Kreis bestätigt, dass der Nutzende von Kubeflow erkannt wurde.
Aktivieren von GPU-Nodes und der automatischen Skalierung von Nodes
Zu diesem Zeitpunkt können sich Data Scientists beim Haupt-Dashboard von Kubeflow anmelden und die bereitgestellten Funktionen nutzen. Eine der Funktionen, die zur Unterstützung mehrerer KI/ML-Use Cases erforderlich sind, ist die Möglichkeit zum Zugriff auf GPUs.
Die Aktivierung von GPU-Nodes ist unkompliziert, sofern die Voraussetzungen erfüllt sind. In diesem Blog-Beitrag wird das Verfahren im Detail beschrieben.
GPU-Nodes sind jedoch teure Ressourcen, daher müssen wir zur Kostenminimierung zwei Anforderungen implementieren:
- Auf den GPU-Nodes sollten nur KI/ML-bezogene Workloads zulässig sein.
- GPU-Nodes sollten automatisch skaliert werden können, wenn mehr Ressourcen benötigt werden, und herunterskaliert werden, wenn die Ressourcen nicht mehr benötigt werden.
Trennung der KI/ML-Workloads von normalen Workloads
Um KI/ML-Workloads von anderen Workloads zu trennen, die möglicherweise im Cluster vorhanden sind und keine GPU-Nodes erfordern, können Taints und Toleranzen verwendet werden. Wir müssen lediglich die GPU-Nodes mit einem Taint erstellen, der verhindert, dass Workloads standardmäßig auf diese Nodes gelangen.
Um sicherzustellen, dass Nicht-KI/ML-Mandanten Workloads nicht so kennzeichnen können, dass sie den Taint tolerieren, kann diese Namespace-Annotation verwendet werden:
scheduler.alpha.kubernetes.io/tolerationsWhitelist: '[]'
Um Data Scientists die Arbeit zu erleichtern und den Workloads, die in den KI/ML-Namespaces ausgeführt werden, automatisch die Toleranz hinzuzufügen, kann die folgende Namespace-Annotation auf alle Kubeflow-Namespaces angewendet werden:
scheduler.alpha.kubernetes.io/defaultTolerations: '[{"operator": "Equal", "effect": "NoSchedule", "key": "workload", "value": "ai-ml"}]'In diesem Beispiel wurden die GPU-fähigen Nodes mit dem Label „workload: ai-ml“ versehen.
Beachten Sie, dass es sich hierbei um Alpha-Annotationen handelt, die derzeit nicht von Red Hat unterstützt werden. Basierend auf unseren Tests funktionieren sie gut.
Wie bereits erwähnt, erstellt Kubeflow bei der ersten Anmeldung eines Data Scientists den entsprechenden Data Scientist Namespace. Da wir nicht kontrollieren, wie Namespaces erstellt werden, muss ein Prozess implementiert werden, damit die richtigen Annotationen auf den Namespace angewendet werden. Dies kann mithilfe einer Mutations-Webhook-Konfiguration erfolgen. Dieser Webhook kann die Erstellung des Namespace abfangen und die erforderlichen Annotationen hinzufügen. Wir haben Open Policy Agent (OPA) und das Gatekeeper-Projekt verwendet, das OPA in Kubernetes integriert, und es über den Gatekeeper-Operator bereitgestellt.
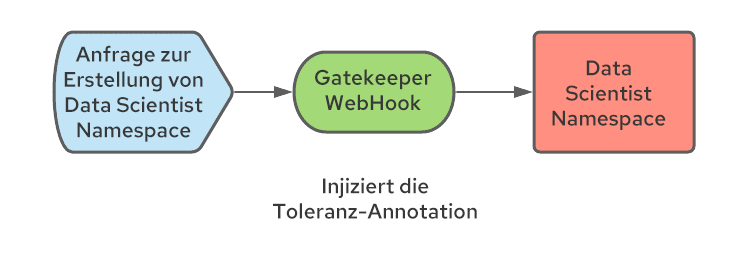
Aktivieren der automatischen Skalierung von Nodes
Um die Anzahl der teuren GPU-Nodes zu minimieren, müssen wir die automatische Skalierung für die KI/ML-Nodes aktivieren.
Die automatische Skalierung von Nodes ist eine Standardfunktion von OpenShift und kann wie in der offiziellen Dokumentation beschrieben aktiviert werden.
Bei der Verwendung des Features für die automatische Skalierung von Nodes wurde deutlich, dass die folgenden Situationen Verbesserungen erforderten:
Erstens fügt der Node Autoscaler nur dann Nodes hinzu, wenn Pods im Status „Pending“ hängenbleiben. Dieses reaktive Verhalten führt zu einem schlechten Benutzererlebnis, da Nutzende, die Workloads starten möchten, warten müssen, bis die Nodes erstellt wurden (etwa 5 Minuten bei AWS) und bis die GPU-Treiber verfügbar sind (zusätzliche etwa 3 bis 4 Minuten). Zur Verbesserung dieser Situation haben wir den Proactive Node Scaling Operator (proactive-node-scaling-operator) verwendet (erläutert in diesem Blog).
Zweitens erstellt der Autoscaler bei der Verwendung von GPU-Nodes tendenziell mehr Nodes als nötig. Dies liegt daran, dass die neu erstellten Nodes die ausstehenden Pods nicht sofort planen können, da diese Nodes anfänglich nicht GPU-fähig sind (während der GPU-Operator Initialisierungsschritte ausführt, z. B. das Kompilieren und Injizieren der GPU-Kernel-Treiber). Um dieses Problem zu beheben, muss ein bestimmtes Label (cluster-api/accelerator: "true") zur Node-Vorlage hinzugefügt werden, wie hier erläutert. Dieses Label informiert den Node Autoscaler darüber, dass für einen bestimmten Node bestimmte Features (z. B. Unterstützung für GPUs) aktiviert werden sollen, auch wenn sie derzeit nicht vorhanden sind.
Ermöglichen des Zugriffs auf den Data Lake
Für fast jede Aufgabe, die ein Data Scientist ausführen muss, sei es die Exploration von Daten, um die Datenstruktur und ihre möglichen internen Korrelationen zu verstehen, das Training neuronaler Netzwerkmodelle anhand von Beispiel-Datasets oder das Abrufen eines Modells zur Bereitstellung, ist der Zugriff auf Daten entscheidend. Im Bereich KI/ML wird das Daten-Repository, das Daten aller Art (relational, Schlüsselwerte, Dokumente, Baumstruktur und andere) enthält, als Data Lake bezeichnet.
Die Sicherung des Zugriffs auf den Data Lake kann sich insbesondere in einer mandantenfähigen Umgebung als schwierig erweisen. Darüber hinaus möchten wir Data Scientists die Arbeit erleichtern, indem wir die Anzahl der Konzepte für das Management von Kubernetes- und Zugangsdaten, mit denen sie sich vertraut machen müssen, minimieren.
In unserem Fall bestand der Data Lake aus mehreren AWS S3-Buckets. Alternative Storage Repository-Typen können viele dieser Konzepte nutzen.
Das Sicherheitsteam gab außerdem an, dass die für den Zugriff auf den Data Lake erforderlichen Zugangsdaten eine Workload und nicht eine bestimmte Person darstellen. Darüber hinaus sollten die Zugangsdaten nur eine kurze Gültigkeit besitzen. Ziel war die Vermeidung der Zuteilung statischer Zugangsdaten an die Data Scientists, die verloren gehen oder zweckentfremdet werden könnten.
Zur Lösung dieses Problems haben wir gebundene Service Account Token und die STS-Integration von OpenShift verwendet und letztere für die Workloads der Nutzenden umgestaltet.Sehen wir uns an, wie diese beiden Technologien miteinander kombiniert werden können.
Mit gebundenen Service Account Token kann OpenShift ein JWT-Token generieren, das die Workload darstellt und als projiziertes Volume gemountet wird, ähnlich der Funktion von Service Account Token für andere Workloads. Im Gegensatz zu Service Account Token ist dieses Token nur kurz gültig (das Kubelet ist für die Aktualisierung zuständig) und kann durch Definition seiner Eigenschaft Zielgruppe angepasst werden.
STS ist ein AWS-Service (ähnliche Services gibt es für andere Cloud-Anbieter), mit dem wir eine Vertrauensstellung zwischen AWS und anderen Authentifizierungssystemen, einschließlich OIDC-Authentifizierungsanbietern, aufbauen können. Durch die Konfiguration von STS können wir AWS anweisen, von OpenShift erstellten JWT-Token zu vertrauen und diese Token gegen AWS-Token mit spezifischen Berechtigungen auszutauschen. Nachdem der Austausch stattgefunden hat, kann die in einem Pod ausgeführte Anwendung AWS-Ressourcen nutzen. Nachfolgend wird diese Architektur dargestellt:
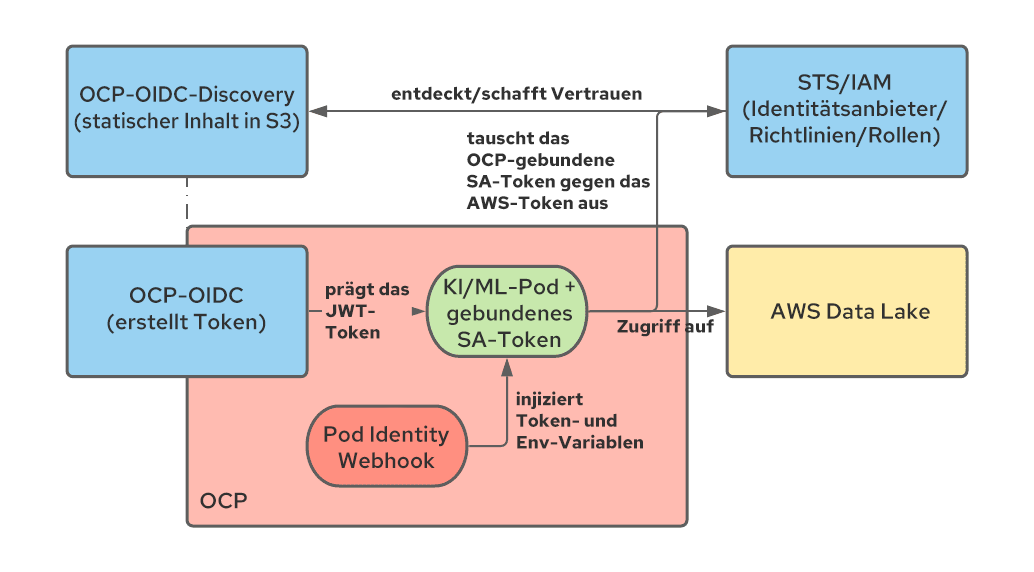
In der offiziellen Dokumentation und diesem Blog erhalten Sie Hilfe bei der Konfiguration der STS-Integration.
Eine der Anforderungen bei diesem Ansatz besteht darin, dass die zum Ausführen der KI/ML-Pods verwendeten Service Accounts über spezifische Annotationen verfügen. Diese geben an, dass für diese Workloads das zusätzliche gebundene Service Account Token erforderlich ist. Dazu können wir OPA verwenden und die benötigten Annotationen in die Service Accounts in den Data Scientist Namespaces einfügen.
Das Ergebnis des zuvor beschriebenen Setups ermöglicht es den Data Scientists und im Allgemeinen KI/ML-Workloads, auf den Data Lake mit Zugangsdaten zuzugreifen, die die Workload (und nicht eine bestimmte Person) repräsentieren und eine kurze Gültigkeit haben (und daher nicht dauerhaft gespeichert werden müssen). All dies geschieht transparent für die Data Scientists, die lediglich einen beliebigen AWS-Standardclient (der die STS-Authentifizierungsmethode versteht) verwenden müssen, um auf den Data Lake zuzugreifen.
Integration mit Serverless
Die Standardmethode zur Bereitstellung eines Modells in Kubeflow ist Kfserving (andere Ansätze werden ebenfalls unterstützt und sind hier beschrieben).
Kfserving basiert auf Knative, einer Funktion, die in OpenShift durch die Installation von OpenShift Serverless aktiviert werden kann.
Bei der Verwendung von Service Mesh und Serverless ist Sorgfalt geboten, da für die ordnungsgemäße Integration bestimmte Voraussetzungen erfüllt sein müssen.
Insbesondere muss die NetworkPolicy-Regel in jedem Service Mesh Namespace erstellt werden, um Datenverkehr von den Serverless Namespaces zu den Mesh Namespaces zu erlauben.
Da alle Mesh Services in einem Kubeflow-Ökosystem mit mehreren Mandanten durch Istio AuthorizationPolicies geschützt sind und Serverless-Komponenten außerhalb des Mesh liegen, müssen wir die RBAC-Richtlinien ändern, um Verbindungen von den Serverless Namespaces Pods zu ermöglichen (speziell Kourier und Activator):
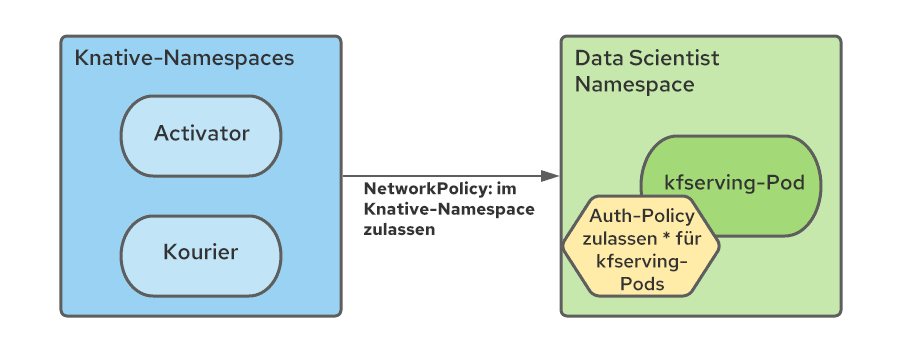
Wir haben die Erstellung dieser Regeln mit dem Namespace-Konfigurationsoperator automatisiert und diesen angewiesen, bei der Erstellung des Data Scientist Namespace NetworkPolicy- und AuthorizationPolicy-Ressourcen hinzuzufügen.
Installation
Schritt-für-Schritt-Installationsanweisungen für die zuvor beschriebenen Themen sowie die zugehörigen Konfigurationen sind in diesem Repository verfügbar. Dieser Walkthrough enthält außerdem einige weitere kleinere Verbesserungen und einige Beispiele für KI/ML-Workloads zur Validierung des Setups.
Fazit
In diesem Artikel haben wir verschiedene Überlegungen angestellt, die bei der Einrichtung eines mandantenfähigen Deployments von Kubeflow auf OpenShift notwendig sind. Dies ist nur der erste Schritt auf dem Weg zu KI/ML, sollte aber für den Einstieg ausreichen. Von hier aus kann das Data Scientist-Team damit beginnen, Daten mit Jupyter Notebooks zu untersuchen und Daten-Pipelines zu erstellen, die auch das Training neuronaler Netzwerkmodelle umfassen können. Sobald die neuronalen Netzwerkmodelle dazu bereit sind, kann Kubeflow auch bei diesen Use Cases für die Bereitstellung von Modellen helfen.
Beachten Sie, dass die Ausführung von Kubeflow auf OpenShift derzeit nicht von Red Hat unterstützt wird. Kubeflow ist ein Produkt mit vielen Funktionen. Im Rahmen dieses ersten Deployments haben wir nicht überprüft, ob alle Funktionen ordnungsgemäß funktionieren. (Sie können die Liste der im Repository getesteten Funktionen einsehen.) Ein wichtiges Feature, das derzeit leider nicht operationalisiert ist, aber zu einem späteren Zeitpunkt integriert werden kann, ist der gesamte von Kubeflow bereitgestellte Observability Stack.
Wir hoffen, dass diese Art von Arbeit als Einstiegshilfe für Unternehmen genutzt werden kann, die Kubeflow auf OpenShift einsetzen möchten. Darüber hinaus sollten diese Konzepte viele der gängigen Primitive bereitstellen, die bei der Operationalisierung anderer KI/ML-Plattformen verwendet werden können.
Über den Autor

Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen
Virtualisierung
Erfahren Sie das Neueste über die Virtualisierung von Workloads in Cloud- oder On-Premise-Umgebungen