Kubeflow는 데이터 탐색, 데이터 파이프라인, 모델 학습, 모델 서빙 등 주요 AI/ML 활용 사례를 다루는 여러 툴을 통합하는 AI/ML 플랫폼입니다. Kubeflow를 사용하는 데이터 사이언티스트는 이러한 여러 툴과 상호작용할 수 있는 높은 수준의 추상화를 제공하는 포털을 통해 AI/ML 기능에 액세스할 수 있습니다. 따라서 데이터 사이언티스트는 쿠버네티스가 각 툴에 플러그인하는 방법에 관한 낮은 수준의 세부 정보를 배우지 않아도 됩니다. 그렇지만 Kubeflow는 쿠버네티스에서 실행되도록 특별히 설계되었으며 오퍼레이터 모델을 비롯한 여러 주요 개념을 완전히 수용합니다. 실제로 위에서 언급한 포털을 제외하고 Kubeflow는 사실 오퍼레이터 컬렉션입니다.
이 문서에서는 OpenShift 환경에서 Kubeflow(1.3 이상)가 원활하게 작동할 수 있도록 최근 고객 소통에 도입한 일련의 구성을 검토합니다.
Kubeflow 멀티테넌시 고려 사항
Kubeflow가 다루는 활용 사례 중 하나는 다수의 데이터 사이언티스트를 지원하는 기능입니다. Kubeflow는 멀티테넌시(릴리스 1.3부터 완전히 사용 가능)에 대한 접근 방식을 도입하여 이를 수행합니다. 이 경우 각 데이터 사이언티스트가 내부에서 관리할 쿠버네티스 네임스페이스를 하나씩 받을 수 있습니다(네임스페이스 간에 아티팩트를 공유하는 메커니즘도 있지만 여기서는 살펴보지 않습니다).
멀티테넌시에 대한 이 접근 방식을 이해해야 합니다. OpenShift에서 이 기능을 지원하는 데 Kubeflow 운영화의 상당 부분이 사용되었기 때문입니다. 애플리케이션당 하나의 네임스페이스(OpenShift를 배포할 때 더 일반적인 패턴)가 아닌 사용자당 하나의 네임스페이스를 사용하려면 인증/권한 부여가 구성되는 방식에 따라 OpenShift를 배포할 때 약간의 재설계가 필요할 수 있습니다.
Kubeflow 멀티테넌시가 제대로 작동하려면 사용자를 인증해야 하며 신뢰할 수 있는 헤더(기본적으로 kubeflow-userid지만 구성 가능)를 모든 요청에 추가해야 합니다. Kubeflow는 그렇게 헤더를 받아 사용자의 네임스페이스가 존재하지 않는 경우 생성합니다.
Kubeflow 멀티테넌시의 또 다른 측면은 프로필이란 개념입니다. 프로필은 사용자의 환경을 나타내는 사용자 정의 리소스(Custom Resource, CR)입니다. 프로필은 Kubeflow에서 관리하는 네임스페이스에 매핑됩니다. Kubeflow-userid 헤더가 요청을 올바르게 라우팅하려면 Kubeflow의 기존 프로필과 일치해야 합니다.
프로필이 설정되고 사용자와 연결되면 Kubeflow에서 알맞은 네임스페이스가 생성되면서 해당 사용자의 모든 후속 활동이 발생합니다.
또한 Kubeflow는 Istio와 긴밀하게 통합됩니다.Istio를 Kubeflow와 함께 실행해야 한다는 엄격한 요구 사항은 없지만 Kubeflow 보안은 Istio 구문을 기반으로 하므로 실행이 권장됩니다. Istio와 함께 실행될 때 멀티테넌시를 지원하는 가장 간단한 방법 중 하나는 서비스 메쉬에 속하는 Kubeflow 프로필과 모든 트래픽이 통과하는 단일 ingress-gateway의 결과로 네임스페이스를 생성하는 것입니다.
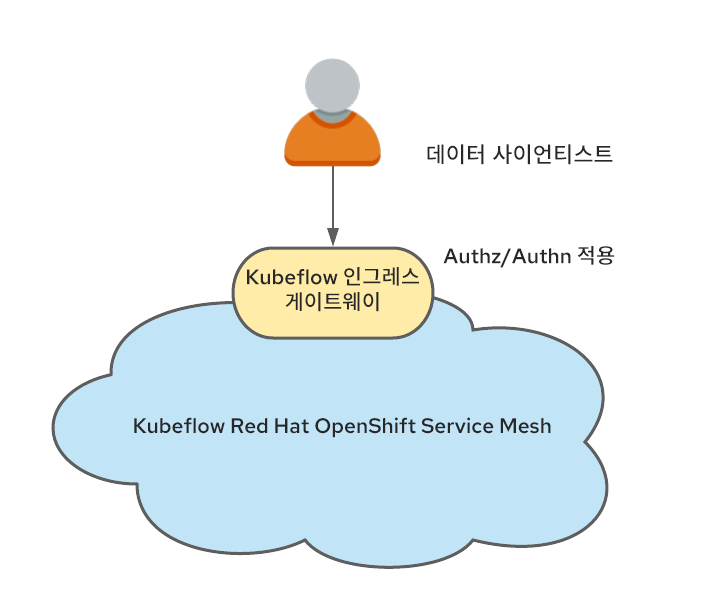
이 병목 지점은 사용자 인증을 수행하고 앞에서 언급한 kubeflow-userid 헤더를 설정할 가능성이 높습니다.
Red Hat OpenShift Service Mesh와 통합
OpenShift Service Mesh는 OpenShift 클러스터에 여러 서비스 메쉬가 포함될 수 있다는 점에서 Istio와 다르지만, 업스트림 Istio의 경우 서비스 메쉬가 전체 Kubernetes 클러스터로 확장된다는 것을 의미합니다.
이 설정에서는 서비스 메쉬를 AI/ML 활용 사례에 전적으로 할당하기로 했습니다. 이를 고려해 볼 때 Kubeflow AI/ML 네임스페이스만 이 AI/ML 전용 서비스 메쉬에 속합니다.
또한 데이터 사이언티스트가 언제든지 추가되고 제거될 수 있어야 했습니다. 따라서 권장에 따라 사용자당 하나의 프로필/네임스페이스 모델을 채택하기로 결정했습니다.
요약하자면 Red Hat은 다음과 같은 요구 사항을 충족하는 솔루션을 찾아야 했습니다.
- 데이터 사이언티스트 연결이 인증되고 kubeflow-userid 헤더가 변조를 방지하는 방식으로 요청에 추가되어야 합니다.
- 데이터 사이언티스트마다 Kubeflow 프로필이 생성되어야 합니다.
- 프로필 생성의 결과로 Kubeflow에서 생성된 Kubeflow 네임스페이스가 AI/ML 서비스 메쉬에 속해야 합니다.
데이터 사이언티스트 인증 보장
앞서 소개했듯이 Kubeflow는 헤더를 사용하여 연결된 사용자를 나타냅니다. 기본 헤더 이름인 kubeflow-userid를 변경하는 옵션이 있지만 여러 위치에서 수정해야 하므로 우리는 기본 헤더 이름을 계속 사용하는 것이 더 간단하다고 결정했습니다.
이 헤더를 삽입하는 방법에는 여러 가지가 있습니다. 다음은 이러한 접근 방식 중 하나에 대한 설명입니다.
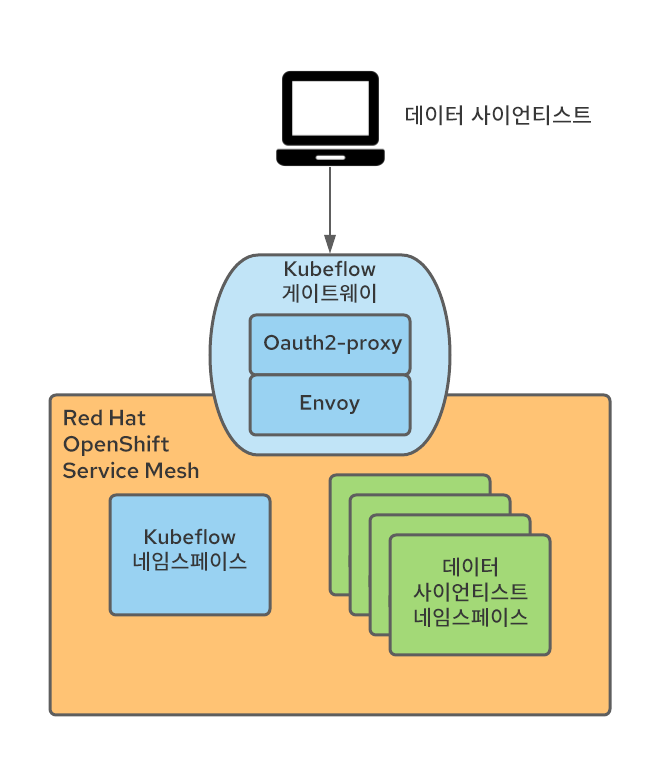
Kubeflow가 Istio 인그레스 게이트웨이(기본적으로 Kubeflow라고 함)에 외부 연결 서비스를 게시한다는 사실을 활용하여 인증되지 않은 사용자를 OpenShift 로그인 흐름으로 리디렉션하는 oauth 프록시를 사용해 인증을 실시하도록 게이트웨이가 설치되었습니다. 이 oauth-프록시 접근 방식은 다른 많은 OpenShift 구성 요소에서 사용되며 필요한 권한이 있는 OpenShift 인증 사용자만 요청할 수 있도록 강제합니다. oauth 프록시를 통합하는 방법에 대한 자세한 내용은 이 블로그 포스트에서 확인할 수 있습니다.
인그레스 게이트웨이의 oauth-프록시 사이드카는 인증된 사용자의 사용자 ID를 사용하여 x-forwarded-user라는 헤더를 생성하므로(http 모범 사례에 따름) 인그레스 게이트웨이에 트랜스포메이션 규칙(EnvoyFilter CR로 구현)을 추가하여 해당 헤더의 값을 kubeflow-userid라는 새 헤더에 복사하기만 하면 됩니다. 또한 oauth-프록시 사이드카는 Kubeflow 네임스페이스의 포드에 대한 GET 권한이 있는 사용자만(Kubeflow 사용자와 비Kubeflow 사용자를 구분하는 데 사용할 수 있는 원하는 권한 집합을 구성할 수 있음) 통과할 수 있도록 구성됩니다.
이 접근 방식을 통해 다음을 성취할 수 있습니다.
- 모든 Kubeflow 사용자가 OpenShift 사용자이기도 합니다(반대의 경우가 항상 맞는 것은 아님). 우리는 엔터프라이즈 인증 시스템과의 통합과 관련해 OCP 내에 구성된 항목을 활용할 수 있습니다. 따라서 이 접근 방식은 이식성이 매우 높습니다.
- Kubeflow 메쉬에 진입하는 방법은 하나뿐이므로(Kubeflow 인그레스 게이트웨이 보호를 통해) 인증된 사용자만 Kubeflow 서비스를 활용할 수 있습니다.
Kubeflow 프로필 생성 확인
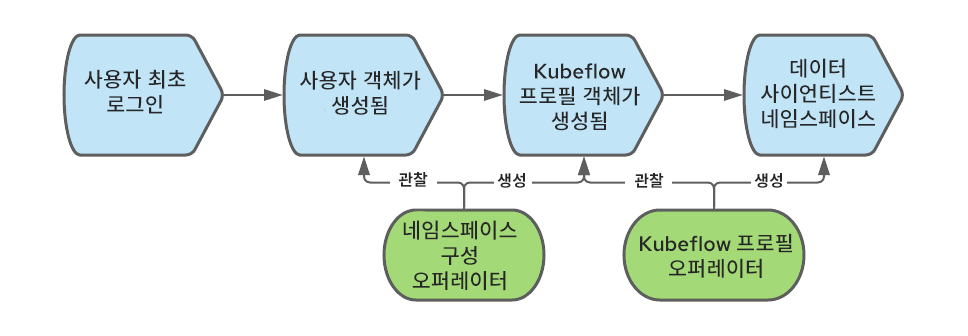
Kubeflow에서 사용자를 올바르게 등록하고 처리하려면 프로필 객체(CR)가 필요합니다. 프로필 객체의 생성을 'https://www.kubeflow.org/docs/components/multi-tenancy/getting-started/#onboarding-a-new-user'이라고 합니다.신규 사용자를 자체 등록하도록 할 수도 있지만, 우리는 자동 등록 프로세스를 사용하기로 결정했습니다. 따라서 사용자가 처음 로그인하면 해당 프로필이 자동으로 생성됩니다.
OpenShift에서는 사용자가 처음 로그인할 때 사용자 객체가 생성됩니다. 이때 해당 이벤트를 가로채서 프로필 객체를 생성할 수도 있습니다.
프로필 객체의 생성을 자동화하기 위해 네임스페이스 구성 오퍼레이터를 사용할 수 있습니다. 다음 다이어그램은 사용자가 OpenShift에 처음 로그인할 때 프로필 객체를 생성하는 이벤트들의 순서를 보여줍니다.
AI/ML 서비스 메쉬에 Kubeflow 네임스페이스 결합
Kubeflow 프로필 객체를 생성하면 Kubeflow도 해당 Kubernetes 네임스페이스를 생성하고 할당량, Istio RBAC 규칙, 서비스 계정과 같은 여러 리소스를 새 네임스페이스에 추가합니다. Kubeflow는 네임스페이스가 메쉬에 속한다고 가정하지만 각 네임스페이스가 지정된 메쉬(여러 개일 수 있음)에 명시적으로 결합되어야 하는 OpenShift Service Mesh의 경우는 다릅니다. 이 문제를 해결하기 위해 우리는 다시 네임스페이스 구성 오퍼레이터를 사용하고 이번에는 네임스페이스 생성 시 트리거되어 메시에 참여하도록 하는 규칙을 생성할 수 있습니다. 전체 워크플로우는 다음으로 구성됩니다.

이 워크플로우가 올바르게 설정되면 데이터 사이언티스트가 로그인할 때 다음 이미지와 같이 표시됩니다.
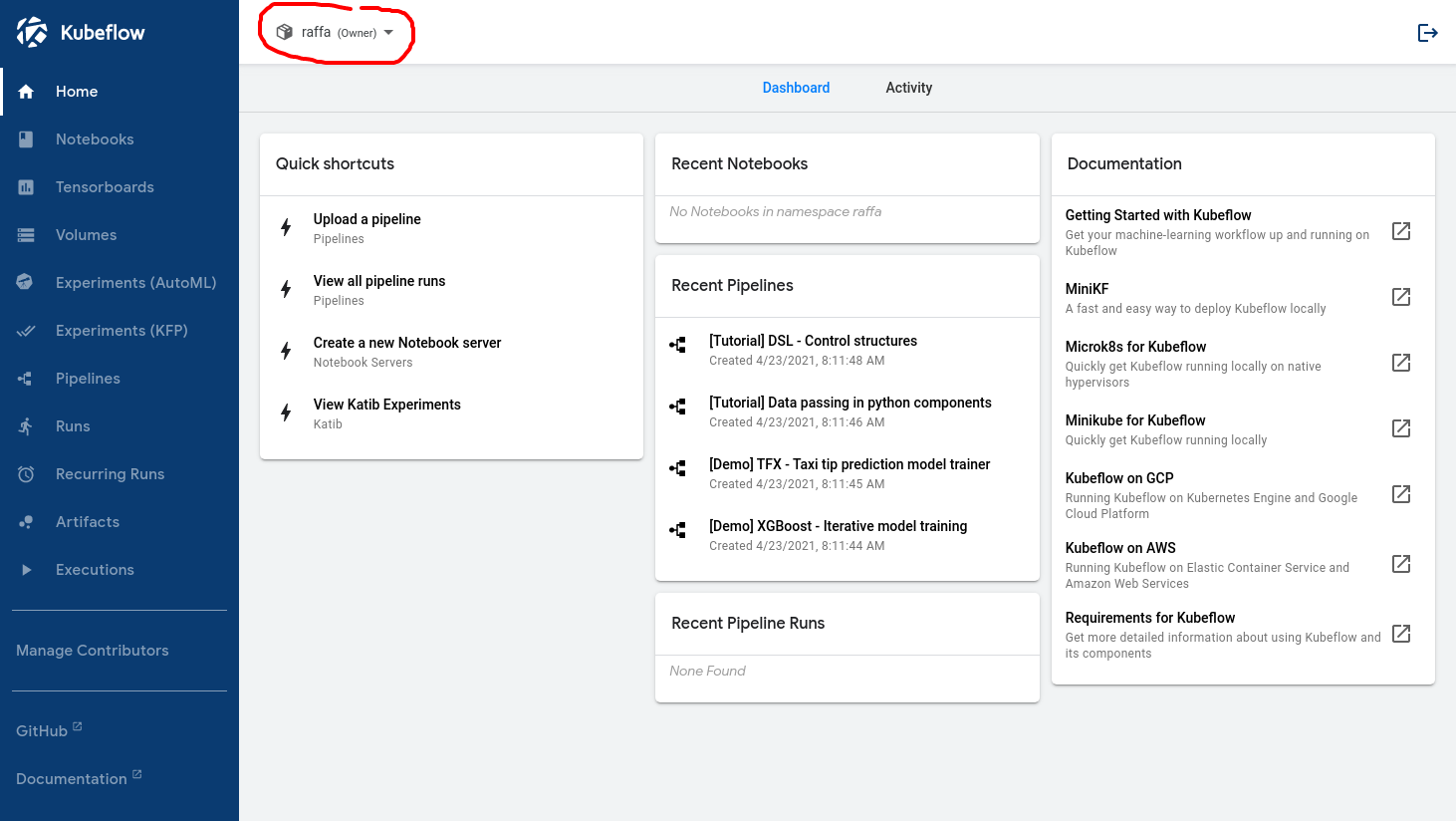
빨간색 원 안의 이름을 통해 Kubeflow에서 사용자를 인식했다는 것을 확인할 수 있습니다.
GPU 노드 및 노드 자동 스케일링 활성화
이제 데이터 사이언티스트는 Kubeflow 기본 대시보드에 로그인하여 제공된 기능을 사용할 수 있습니다. 물론 여러 AI//ML 활용 사례를 지원하는 데 필요한 기능 중 하나는 GPU에 액세스하는 기능입니다.
전제 조건이 충족되는 경우 GPU 노드를 활성화하는 것은 간단합니다. 이 블로그 포스트에서 프로세스를 자세히 설명하고 있습니다.
그러나 GPU 노드는 값비싼 리소스이므로 비용을 최소화하기 위해 다음 두 가지 요구 사항을 실행해야 합니다.
- GPU 노드에서는 AI/ML 관련 워크로드만 허용해야 합니다.
- GPU 노드는 더 많은 리소스가 필요할 때 자동으로 확장하고 해당 리소스가 더 이상 필요하지 않을 때 축소될 수 있어야 합니다.
AI/ML 워크로드와 일반 워크로드의 분리
AI/ML 워크로드를 클러스터에 있을 수 있고 GPU 노드가 필요하지 않은 다른 워크로드와 분리하기 위해 우리는 오염 및 허용 오차를 사용할 수 있습니다.기본적으로 워크로드가 일반 노드에 도달하지 않도록 막는 오염을 사용하여 GPU 노드를 생성하기만 하면 됩니다.
비AI/ML 테넌트가 워크로드에 오염 허용으로 태그를 지정할 수 없도록 하기 위해 다음과 같은 네임스페이스 주석을 사용할 수 있습니다.
scheduler.alpha.kubernetes.io/tolerationsWhitelist: '[]'
데이터 사이언티스트의 작업을 간소화하고 AI/ML 네임스페이스에서 실행되는 워크로드에 허용 오차를 자동으로 추가하기 위해 다음 네임스페이스 주석을 모든 Kubeflow 네임스페이스에 적용할 수 있습니다.
scheduler.alpha.kubernetes.io/defaultTolerations: '[{"operator": "Equal", "effect": "NoSchedule", "key": "workload", "value": "ai-ml"}]'이 예시에서 GPU 지원 노드는 'workload: ai-ml'로 레이블이 지정되었습니다.
이러한 주석은 알파 주석이며 현재 Red Hat에서 지원하지 않지만 테스트에 따르면 정상적으로 작동합니다.
앞에서 설명한 대로 Kubeflow는 데이터 사이언티스트가 처음 로그인하면 데이터 사이언티스트 네임스페이스를 생성합니다. 우리는 네임스페이스를 생성하는 방법을 제어하지 않으므로 올바른 주석이 네임스페이스에 적용되도록 프로세스를 구현해야 합니다. 이 작업은 변형 웹후크 구성을 사용하여 수행할 수 있습니다. 이 웹후크는 네임스페이스 생성을 가로채고 필요한 주석을 추가할 수 있습니다. 우리는 OPA(Open Policy Agent)와 OPA를 쿠버네티스와 통합하는 게이트키퍼 프로젝트를 사용했으며 게이트키퍼 오퍼레이터를 통해 배포했습니다.
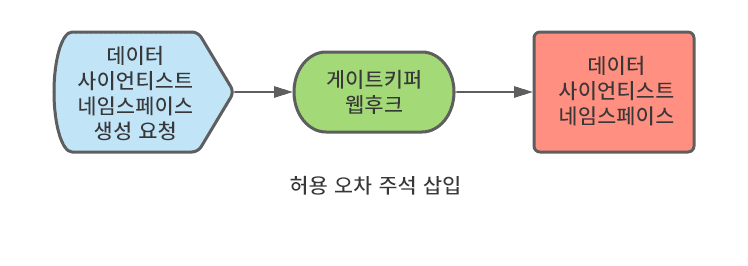
노드 자동 스케일링 활성화
값비싼 GPU 노드 수를 최소화하려면 AI/ML 노드에서 자동 스케일링을 활성화해야 합니다.
노드 자동 스케일링은 OpenShift의 기본 기능으로, 공식 문서의 단계를 통해 활성화할 수 있습니다.
노드 자동 스케일링 기능을 사용하면서 다음과 같은 상황을 개선해야 한다는 점이 분명해졌습니다.
첫째, 노드 자동 스케일러는 포드가 'pending' 상태에 멈춘 경우에만 노드를 추가합니다. 이러한 반응형 동작은 워크로드를 시작하려는 사용자가 노드가 생성되고(AWS에서 최대 5분) GPU 드라이버를 사용할 수 있을 때까지(추가로 최대 3~4분) 기다려야 하기 때문에 바람직하지 않은 사용자 환경으로 이어집니다. 이러한 상황을 개선하기 위해 우리는 proactive-node-scaling-operator를 사용했습니다(이 블로그에 설명되어 있음).
둘째, GPU 노드를 사용할 때 자동 스케일러에서 필요한 것보다 더 많은 노드를 생성하는 경향이 있습니다. 이는 새로 생성된 노드의 경우 처음에는(GPU 오퍼레이터가 GPU 커널 드라이버의 컴파일링, 삽입과 같은 초기화 단계를 수행하는 동안) GPU가 활성화되어 있지 않아 보류 중인 포드를 즉시 예약할 수 없기 때문입니다. 이 문제를 해결하려면 여기에 설명된 대로 특정 레이블(cluster-api/accelerator: "true")을 노드 템플릿에 추가해야 합니다. 이 레이블은 특정 기능(예: GPU 지원)이 현재 존재하지 않을 때도 지정된 노드가 그러한 기능을 활성화하려고 한다는 것을 노드 자동 스케일러에게 알립니다.
데이터 레이크에 대한 액세스 활성화
데이터 구조와 가능한 내부 상관관계를 이해하기 위한 데이터 탐색, 샘플 데이터 세트를 통한 신경망 모델 학습, 서빙할 수 있는 모델 검색 등 데이터 사이언티스트가 수행해야 하는 거의 모든 태스크에서 데이터 액세스는 핵심입니다. AI/ML에서 모든 유형의 데이터(관계형, 키 값, 문서, 트리 등)를 포함하는 데이터 리포지토리를 데이터 레이크라고 합니다.
특히 멀티테넌트 환경에서는 데이터 레이크에 대한 액세스를 보호하는 것이 어려울 수 있습니다. 아울러 우리는 데이터 사이언티스트가 학습해야 하는 쿠버네티스 및 자격 증명 관리 개념의 수를 최소화하여 데이터 사이언티스트의 편의를 도모하고자 합니다.
지금 이 경우 데이터 레이크는 AWS S3 버킷 세트로 구성되었습니다. 대체 스토리지 리포지토리 유형은 이러한 동일한 개념을 대부분 활용할 수 있습니다.
보안 팀 역시 데이터 레이크에 액세스하는 데 필요한 자격 증명이 특정 개인이 아닌 워크로드를 나타내야 한다고 요청했습니다. 또한 자격 증명은 수명이 짧아야 합니다. 손실되거나 오용될 수 있는 정적 자격 증명을 데이터 사이언티스트에게 배포하는 것을 방지하는 것이 목표였습니다.
우리는 이 문제를 해결하기 위해 바인딩된 서비스 계정 토큰과 OpenShift - STS 통합을 사용하여 후자를 사용자 워크로드에 맞게 용도 변경했습니다.이 두 기술을 어떻게 결합할 수 있는지 살펴보겠습니다.
바인딩된 서비스 계정 토큰을 사용하면 서비스 계정 토큰이 기타 다른 워크로드에 대해 작동하는 방식과 유사하게 워크로드를 나타내고 예상 볼륨으로 마운트되는 JWT 토큰을 OpenShift가 생성할 수 있습니다. 서비스 계정 토큰과 달리 이 토큰은 수명이 짧으며(Kubelet이 새로 고침을 담당) 대상 속성을 정의하여 사용자 정의할 수 있습니다.
STS는 AWS 서비스(다른 클라우드 공급업체에도 유사한 서비스가 있음)로, AWS에서 OIDC 인증 공급업체를 비롯한 다른 인증 시스템으로 신뢰를 구축할 수 있습니다. STS를 구성함으로써 우리는 OpenShift에서 생성한 JWT 토큰을 신뢰하고 이 토큰을 특정 권한 세트가 있는 AWS 토큰으로 교환하도록 AWS에 지시할 수 있습니다. 교환이 수행되고 나면 포드에서 실행되는 애플리케이션에서 AWS 리소스를 사용할 수 있습니다. 아래 다이어그램은 이러한 아키텍처를 보여줍니다.
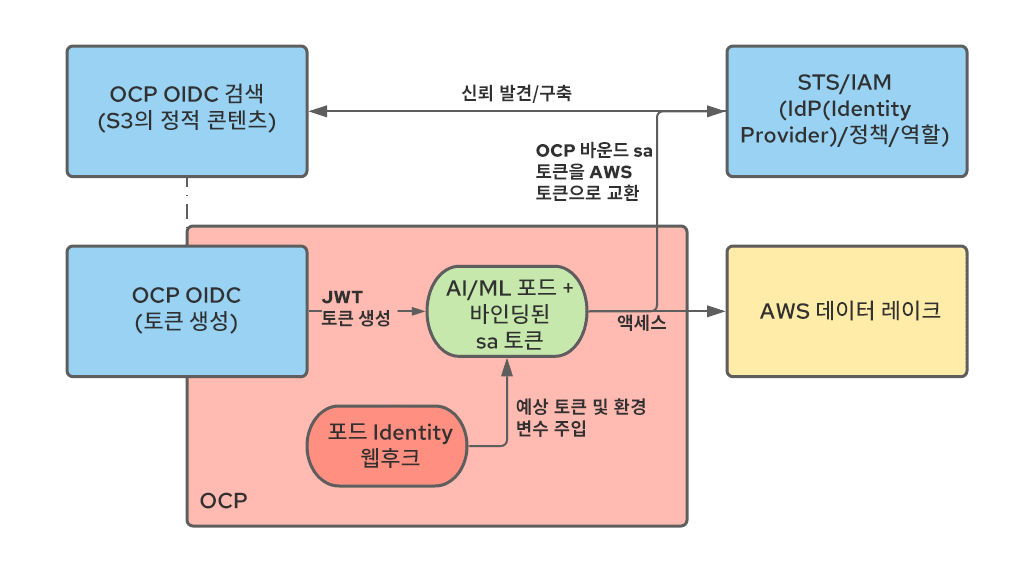
공식 문서와 이 블로그를 참조하여 STS 통합을 구성할 수 있습니다.
이 접근 방식의 요구 사항 중 하나는 AI/ML 포드를 실행하는 데 사용되는 서비스 계정에 이러한 워크로드에 바인딩된 추가 서비스 계정 토큰이 필요하다는 것을 나타내는 특정 주석이 첨부되어야 한다는 것입니다. 우리는 OPA를 사용하고 데이터 사이언티스트 네임스페이스의 서비스 계정에 필요한 주석을 주입하면 이 요구 사항을 충족할 수 있습니다.
앞에서 설명한 설정의 결과를 통해 데이터 사이언티스트와 AI/ML 워크로드는 워크로드(특정 개인이 아님)를 나타내고 짧게 지속되는(short-lived)(따라서 어디서나 유지될 필요가 없음) 자격 증명을 사용하여 데이터 레이크에 액세스할 수 있습니다. 또한 이 모든 작업은 데이터 레이크에 액세스하기 위해 표준 AWS 클라이언트(STS 인증 방법 이해)를 사용하기만 하면 되는 데이터 과학자에게 투명하게 이루어집니다.
Serverless와 통합
모델을 서빙할 때 Kubeflow에서 모델 서빙을 완수하는 기본 방법은 Kfserving을 사용하는 것입니다(다른 접근 방식도 지원되며 여기에 설명되어 있음).
Kfserving은 OpenShift Serverless를 설치하여 활성화할 수 있는 기능인 Knative(OpenShift에 존재)를 기반으로 합니다.
ServiceMesh 및 Serverless를 올바르게 통합하려면 일부 전제 조건을 충족해야 하므로 사용 시 주의가 필요합니다.
특히 서버리스 네임스페이스에서 메쉬 네임스페이스로의 트래픽을 허용하려면 모든 서비스 메쉬 네임스페이스에 NetworkPolicy 규칙을 생성해야 합니다.
또한 멀티테넌트 Kubeflow 에코시스템의 모든 메쉬 서비스는 Istio AuthorizationPolicies로 보호되고 서버리스 구성 요소는 메쉬의 외부에 있으므로 Serverless 네임스페이스 포드(특히 Kourier와 Activator)로부터의 연결을 허용하도록 RBAC 정책을 수정해야 합니다.
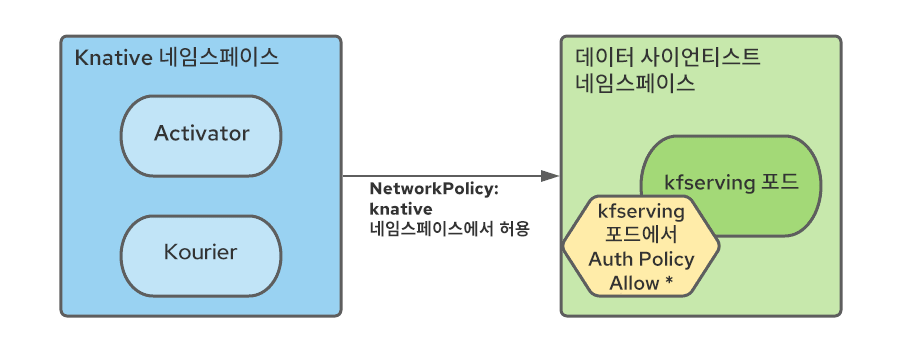
우리는 이러한 네임스페이스 구성 오퍼레이터로 이러한 규칙의 생성을 자동화하고, 데이터 사이언티스트 네임스페이스 생성 시 NetworkPolicy 리소스와 AuthorizationPolicy 리소스를 추가할 것을 지시했습니다.
설치
이전에 설명한 각 항목의 단계별 설치 지침과 관련 구성은 이 리포지토리에서 확인할 수 있습니다. 이 안내서에는 몇 가지 기타 소규모 개선 사항과 설정을 검증하는 AI/ML 워크로드의 몇 가지 예시도 포함되어 있습니다.
결론
이 문서에서는 OpenShift에서 Kubeflow의 멀티테넌트 배포를 설정하는 데 필요한 몇 가지 고려 사항을 다루었습니다. 이것은 AI/ML 여정의 첫 단계에 불과하지만 여정을 시작하기에는 충분합니다. 이 단계에서부터 데이터 사이언티스트 팀은 Jupyter Notebook을 사용하여 데이터를 탐색하고 신경망 모델 학습을 포함할 수 있는 데이터 파이프라인을 생성할 수 있습니다. 신경망 모델이 준비되면 Kubeflow는 모델 서빙 활용 사례도 지원할 수 있습니다.
OpenShift에서 Kubeflow를 실행하는 것은 현재 Red Hat에서 지원하지 않습니다. 또한 Kubeflow는 기능이 풍부한 제품이며, 우리는 이 초기 배포에서 모든 기능이 올바르게 작동하는지 검증하지 않았습니다(리포지토리에서 테스트된 기능 목록을 확인할 수 있음). 예를 들어 나중에 통합될 수 있지만 현재는 운영화되지 않은 중요한 기능 중 하나가 Kubeflow에서 제공하는 전체 관측성 스택입니다.
이러한 유형의 작업이 OpenShift에서 Kubeflow를 실행하려는 조직에 도움이 되기를 바랍니다. 또한 이러한 개념들을 통해 다른 AI/ML 플랫폼을 운영할 때 사용할 수 있는 여러 일반적인 기본 요소가 제공되어야 합니다.
저자 소개

Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래