Kubeflow es una plataforma de inteligencia artificial/machine learning (aprendizaje automático) que reúne varias herramientas que se utilizan para los principales casos prácticos de estas tecnologías: análisis de datos, canales de datos, entrenamiento de modelos y distribución de modelos. Además, permite que los analistas de datos accedan a estas funciones a través de un portal que ofrece una serie de abstracciones de nivel superior para utilizar esas herramientas, de manera que no necesitan preocuparse por conocer los detalles básicos sobre el modo en que Kubernetes se conecta a cada una de ellas. Kubeflow está diseñado específicamente para ejecutarse en Kubernetes y adopta por completo muchos de sus conceptos clave, incluido el modelo de operador. De hecho, a excepción del portal recién mencionado, Kubeflow es en realidad un conjunto de operadores.
En este artículo, analizaremos una serie de configuraciones que adoptamos recientemente con un cliente para lograr que Kubeflow (1.3 o superior) funcione bien en un entorno de OpenShift.
Aspectos relacionados con la arquitectura multiempresa de Kubeflow
Uno de los casos prácticos que aborda Kubeflow es la capacidad de prestar servicio a una gran cantidad de analistas de datos. Kubeflow lo logra introduciendo un enfoque orientado a la arquitectura multiempresa (totalmente disponible desde la versión 1.3), en la cual cada analista de datos recibe un espacio de nombres de Kubernetes para operar en ella (también hay mecanismos para compartir artefactos entre los espacios de nombres, pero no se analizan en este artículo).
Es importante comprender este enfoque orientado a la arquitectura multiempresa, ya que una gran parte de lo requerido para el funcionamiento de Kubeflow se destinó a la implementación de esta estrategia en OpenShift. Es posible que para tener un espacio de nombres por usuario en lugar de un espacio de nombres por aplicación (que es el patrón más común que se utiliza para OpenShift) se requieran algunas tareas de rediseño en el momento de implementar OpenShift, según la manera en que se organice la autenticación o autorización.
Para que la arquitectura multiempresa de Kubeflow funcione correctamente, se debe autenticar al usuario y agregar un encabezado de confianza (de forma predeterminada, kubeflow-userid, pero se puede configurar) en todas las solicitudes. Luego, Kubeflow creará el espacio de nombres para el usuario si todavía no existe.
El otro aspecto de la arquitectura multiempresa de Kubeflow es el concepto de perfil. Un perfil es un recurso personalizado que representa el entorno de un usuario y se asigna a un espacio de nombres que Kubeflow administra. El encabezado kubeflow-userid debe coincidir con un perfil que ya exista para que Kubeflow dirija las solicitudes correctamente.
Una vez que se establece un perfil y se asocia con un usuario, Kubeflow crea el espacio de nombres correspondiente, donde se llevarán a cabo todas las actividades posteriores de ese usuario.
Kubeflow también está integrado directamente a Istio.Si bien no hay un requisito obligatorio de ejecutar Istio con Kubeflow, se recomienda hacerlo, ya que la seguridad de la segunda plataforma se basa en los elementos de la primera. Cuando se ejecutan juntas, una de las estrategias más sencillas para admitir la arquitectura multiempresa es crear los espacios de nombres con los perfiles de Kubeflow que pertenecen a la malla de servicios y a una única puerta de enlace de ingreso a través de la cual fluye todo el tráfico.
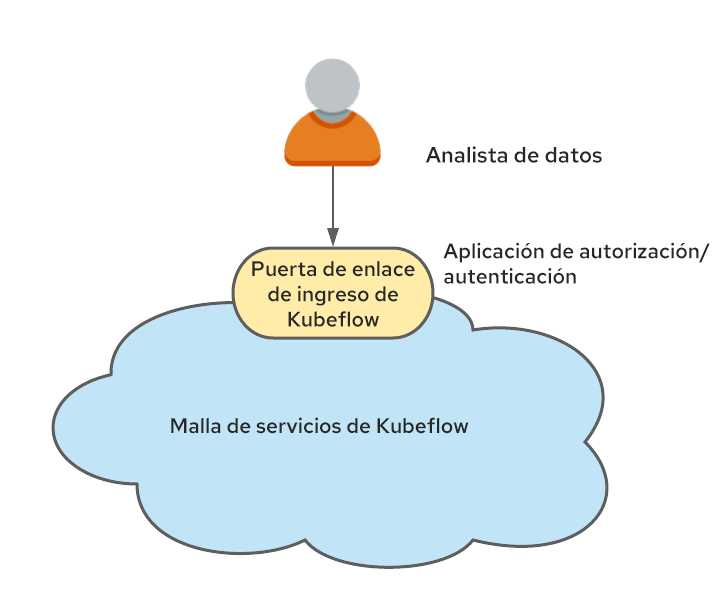
Este punto de congestión se convierte en el escenario natural para llevar a cabo la autenticación de los usuarios y establecer el encabezado kubeflow-userid mencionado anteriormente.
Integración en Service Mesh
OpenShift Service Mesh se diferencia de Istio en que un clúster de OpenShift puede contener varias mallas de servicios, mientras que para Istio upstream, la malla se expande a todo el clúster de Kubernetes.
En nuestra configuración, decidimos dedicar toda una malla de servicios a los casos prácticos de inteligencia artificial/machine learning. De esta manera, solo los espacios de nombres de Kubeflow para las mencionadas tecnologías pertenecen a esta malla de servicios
También necesitábamos prever la incorporación y eliminación de analistas de datos en cualquier momento, por lo que adoptamos el modelo recomendado de un perfil y un espacio de nombre por usuario.
En resumen, teníamos que encontrar soluciones para los siguientes requisitos:
- Garantizar que las conexiones de los analistas de datos estén autenticadas y que se agregue el encabezado kubeflow-userid a la solicitud de manera que evite manipulaciones
- Garantizar que se cree un perfil de Kubeflow para cada analista de datos
- Garantizar que los espacios de nombres de Kubeflow que genere esta plataforma con la creación de un perfil pertenezcan a la malla de servicios de inteligencia artificial/machine learning
Garantizar la autenticación de los analistas de datos
Como se explicó anteriormente, Kubeflow usa un encabezado para representar al usuario que está conectado. Si bien hay opciones para cambiar el nombre predeterminado del encabezado, kubeflow-userid, cambiarlo implica efectuar modificaciones en varias ubicaciones y, por lo tanto, decidimos que sería más sencillo seguir usando ese nombre.
Este encabezado se puede insertar de varias maneras; una de ellas es la siguiente:
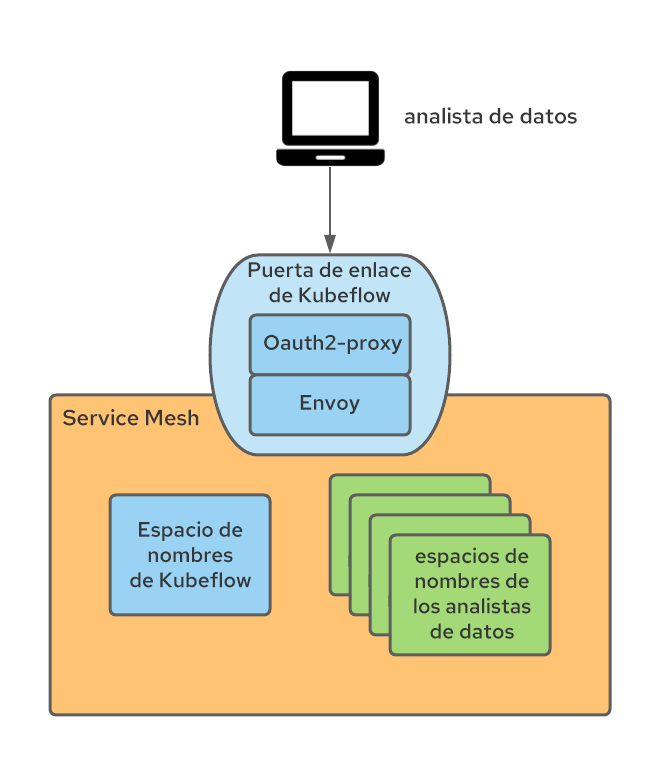
Como Kubeflow publica sus servicios externos en una puerta de enlace de ingreso de Istio (llamada Kubeflow de forma predeterminada), la puerta de enlace se instrumentó para aplicar la autenticación mediante un proxy OAuth que redirige a los usuarios no autenticados al flujo de inicio de sesión de OpenShift. Muchos otros elementos de OpenShift utilizan este enfoque de proxy OAuth, el cual establece que solo los usuarios autenticados de OpenShift con los permisos necesarios puedan realizar solicitudes. Obtenga más información sobre la forma de integrar el proxy OAuth en esta publicación de blog.
El sidecar de proxy OAuth en la puerta de enlace de ingreso crea un encabezado denominado x-forwarded-user con el ID del usuario autenticado (según las prácticas recomendadas de http), por lo que solo necesitamos agregar una regla de transformación (implementada como un recurso personalizado EnvoyFilter) en la puerta de enlace de ingreso para copiar el valor de ese encabezado en uno nuevo denominado kubeflow-userid. Además, el sidecar de oauth-proxy está configurado para que solo puedan acceder los usuarios que cuenten con el permiso GET en los pods de los espacios de nombres de Kubeflow (aquí se puede configurar cualquier conjunto de permisos deseado, el cual se puede usar para distinguir entre los usuarios de Kubeflow y aquellos que no lo son).
Este enfoque logra lo siguiente:
- Todos los usuarios de Kubeflow también son usuarios de OpenShift (tenga en cuenta que no necesariamente ocurre lo mismo en el otro sentido). Podemos aprovechar la configuración de OpenShift Container Platform (OCP) en términos de integración en el sistema de autenticación empresarial. Esto permite que el enfoque ofrezca un gran nivel de compatibilidad.
- Como solo hay un método de ingreso a la malla de Kubeflow (a través de la protección de la puerta de enlace de ingreso de Kubeflow), garantizamos que únicamente los usuarios autenticados puedan utilizar los servicios de Kubeflow.
Garantizar la creación de los perfiles de Kubeflow
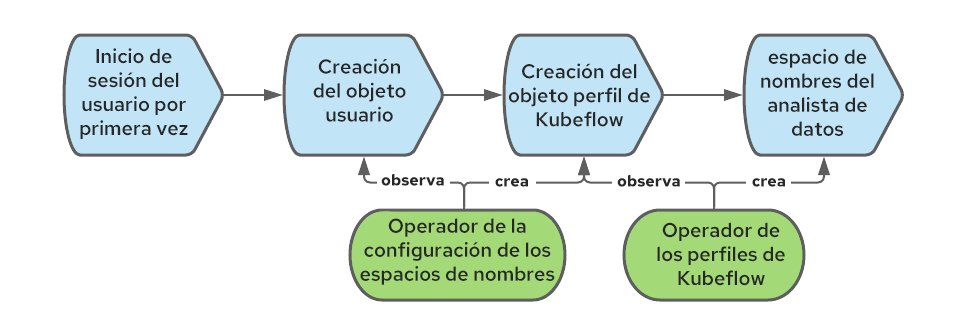
Kubeflow requiere un objeto perfil (recurso personalizado) para registrar y gestionar al usuario correctamente. La creación del objeto perfil se denomina "registro".Se puede permitir que los nuevos usuarios se autorregistren, pero decidimos establecer un proceso de registro automático: cuando un usuario inicia sesión por primera vez, creamos el perfil correspondiente de forma automática.
En OpenShift, se crea el objeto usuario la primera vez que un usuario inicia sesión. Podemos interceptar ese evento para crear también el objeto perfil.
Para automatizar la creación de este último objeto, podemos usar el operador de la configuración de los espacios de nombres. En el siguiente diagrama, se muestra la secuencia de eventos que crean el objeto perfil cuando un usuario inicia sesión por primera vez en OpenShift:
Unir los espacios de nombres de Kubeflow a la malla de servicios de inteligencia artificial/machine learning
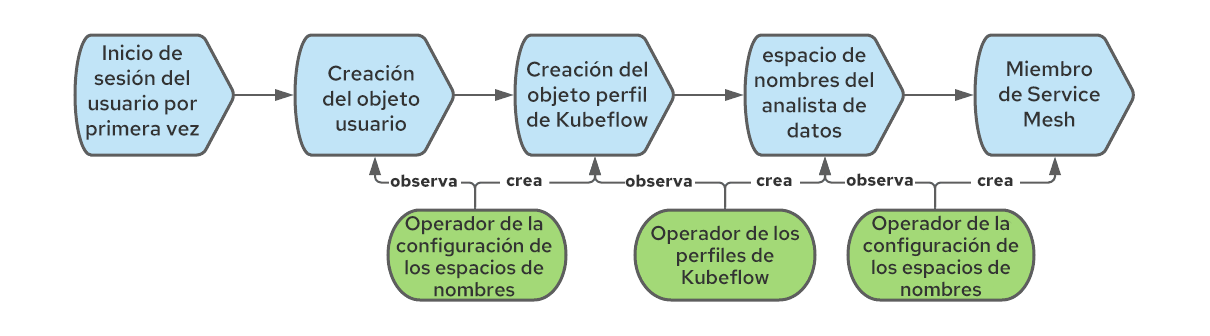
Cuando creamos un objeto perfil de Kubeflow, la plataforma también crea el espacio de nombres de Kubernetes correspondiente y le agrega varios recursos, como cuotas, reglas de RBAC de Istio y cuentas de servicios. Kubeflow asume que los espacios de nombres pertenecen a la malla, pero ese no es el caso de OpenShift Service Mesh, donde cada espacio de nombres debe unirse explícitamente a una malla determinada (puede haber varias). Para resolver este problema, podemos volver a usar el operador de la configuración de los espacios de nombres, pero esta vez crear una regla que se active cuando se creen los espacios de nombres para luego unirlos a la malla. El flujo de trabajo completo comprende lo siguiente:
La siguiente imagen muestra lo que el analista de datos debe ver cuando inicia sesión después de configurar correctamente el flujo de trabajo:
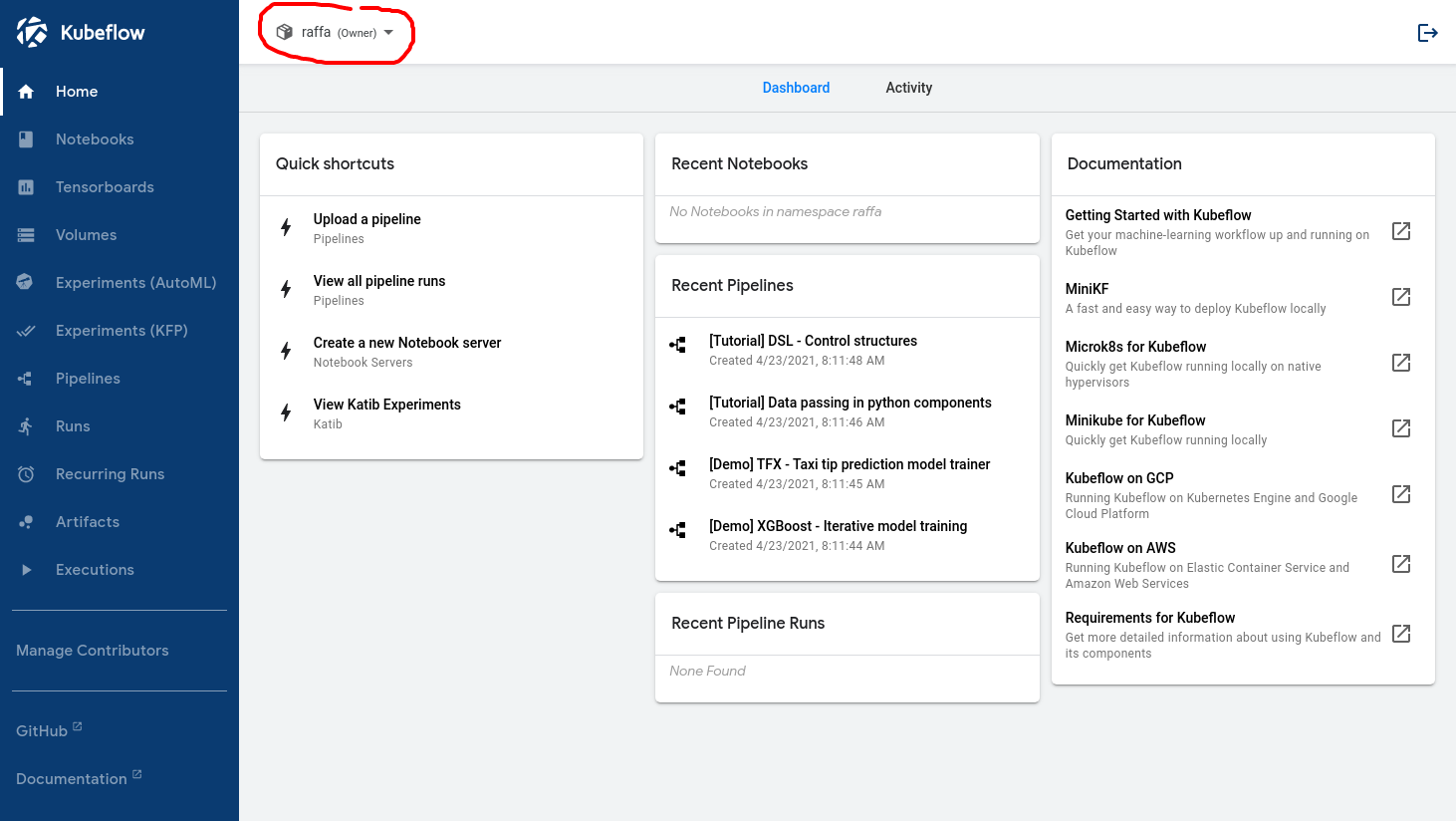
El nombre dentro del círculo rojo confirma que Kubeflow reconoció al usuario.
Permitir los nodos de GPU y su ajuste automático
A esta altura, los analistas de datos pueden iniciar sesión en el panel principal de Kubeflow y comenzar a utilizarla. Una de las funciones que se necesita para admitir varios de los casos prácticos de inteligencia artificial/machine learning es la capacidad de acceder a las GPU.
Es muy sencillo activar los nodos de las GPU siempre que se cumplan los requisitos previos. En esta publicación de blog se describe el proceso en detalle.
Sin embargo, los nodos de GPU son recursos costosos, por lo que debemos implementar dos requisitos para reducir al mínimo los gastos:
- Solo se deben permitir cargas de trabajo relacionadas con la inteligencia artificial y el machine learning en los nodos de GPU.
- Los nodos de GPU deben poder ampliar su capacidad automáticamente cuando se necesiten más recursos y reducirla cuando ya no se los necesite.
Separar las cargas de trabajo de inteligencia artificial/machine learning de las cargas de trabajo normales
Para separar las cargas de trabajo de inteligencia artificial/machine learning de otras cargas de trabajo que pueden estar presentes en el clúster y que no requieren nodos de GPU, podemos usar los valores taint y toleration.Solo tenemos que crear los nodos de GPU con un taint que evitará que las cargas de trabajo lleguen a esos nodos de manera predeterminada.
Para asegurarnos de que los usuarios a los que no les corresponden cargas de trabajo de inteligencia artificial/machine learning no puedan etiquetarlas como tolerantes al taint, podemos usar esta anotación de espacio de nombres:
scheduler.alpha.kubernetes.io/tolerationsWhitelist: '[]'
Para simplificar la tarea del analista de datos y agregar automáticamente el valor toleration a las cargas de trabajo que se ejecutan en los espacios de nombres de inteligencia artificial/machine learning, aplique la siguiente anotación a todos los espacios de nombres de Kubeflow:
scheduler.alpha.kubernetes.io/defaultTolerations: '[{"operator": "Equal", "effect": "NoSchedule", "key": "workload", "value": "ai-ml"}]'En este ejemplo, los nodos habilitados para GPU se etiquetaron con "workload: ai-ml".
Tenga en cuenta que estas son anotaciones alfa y que, si bien actualmente no son compatibles con Red Hat, funcionan bien según nuestras pruebas.
Como mencionamos anteriormente, Kubeflow creará espacios de nombres para los analistas de datos en el primer inicio de sesión de cada uno de ellos. Dado que no controlamos el modo en que se crean los espacios de nombres, se debe implementar un proceso para que se les apliquen las anotaciones correctas. Esto se logra mediante una configuración del webhook de mutación, el cual intercepta la creación de espacios de nombres y agrega las anotaciones necesarias. Usamos Open Policy Agent (OPA) y el proyecto Gatekeeper, que integra OPA y Kubernetes, y los implementamos a través del operador de Gatekeeper.
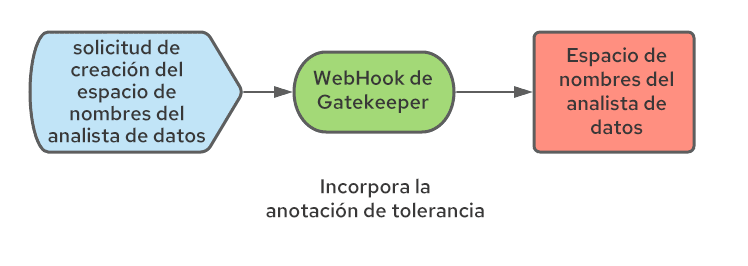
Permitir el ajuste automático de los nodos
Para minimizar la cantidad de nodos de GPU costosos, debemos habilitar el ajuste automático de los nodos de inteligencia artificial/machine learning.
El ajuste automático de los nodos es una función lista para su uso de OpenShift que se puede habilitar siguiendo los pasos que figuran en la documentación oficial.
Al usar la función de ajuste automático de los nodos, se observó que las siguientes situaciones requerían mejoras:
Primero, la herramienta de ajuste automático agregará nodos solo cuando los pods permanezcan en estado "pendiente". Este comportamiento reactivo se traduce en una mala experiencia para los usuarios, ya que los que intenten iniciar cargas de trabajo deberán esperar a que se creen los nodos (aproximadamente 5 minutos en AWS) y a que los controladores de las GPU estén disponibles (entre 3 y 4 minutos adicionales). Para mejorar esta situación, usamos el operador proactive-node-scaling-operator (que se explica en esta publicación de blog).
En segundo lugar, cuando se usan nodos de GPU, la herramienta de ajuste automático tiende a crear más nodos de los necesarios. Esto se debe a que los nodos recién creados no pueden programar los pods pendientes de inmediato debido a que, en principio, no están habilitados para GPU (mientras el operador de GPU lleva a cabo los pasos de inicio, como compilar e insertar los controladores del kernel de la GPU). Para solucionar este problema, se debe agregar una etiqueta específica (cluster-api/accelerator: "true") a la plantilla del nodo, como se explica aquí. Esta etiqueta informará a la herramienta de ajuste automático que un nodo determinado debe tener habilitadas ciertas funciones (como el soporte para GPU), incluso cuando no las tenga actualmente.
Permitir el acceso al lago de datos
El acceso a los datos es esencial para prácticamente todas las tareas que deben realizar los analistas de datos, ya sea el análisis de los datos para comprender su estructura y las posibles correlaciones internas, el entrenamiento de modelos de redes neuronales a través de conjuntos de datos de muestra o la recuperación de un modelo para poder distribuirlo. En el ámbito de a inteligencia artificial y el machine learning, el repositorio de datos, que contiene todos los tipos (relacionales, valores clave, documentos y árbol, entre otros), se denomina lago de datos.
La protección del acceso al lago de datos puede ser un desafío, especialmente en un entorno multiempresa. Además, queremos simplificar la tarea de los analistas de datos reduciendo al mínimo la cantidad de conceptos de gestión de credenciales y Kubernetes sobre la que deben estar al tanto.
En nuestro caso, el lago de datos consistía en un conjunto de buckets de AWS S3. Los tipos de repositorios de almacenamiento alternativos utilizan muchos de estos mismos conceptos.
El equipo de seguridad también solicitó que las credenciales que se requieren para acceder al lago de datos representen una carga de trabajo, no una persona específica. Además, la credencial debe tener una duración breve. El objetivo era evitar la distribución de credenciales estáticas a los analistas de datos, ya que podrían perderse o usarse de manera indebida.
Para resolver este problema, usamos tokens de cuentas de servicios vinculados y la integración de STS y OpenShift, y volvimos a utilizar esta última para las cargas de trabajo de los usuarios.Veamos la manera en que se combinan estas dos tecnologías.
Con los tokens de cuentas de servicios vinculados, se puede lograr que OpenShift genere un token JWT, que representa la carga de trabajo y se monta como volumen proyectado, de manera similar al funcionamiento de los tokens de cuentas de servicios para cualquier otra carga de trabajo. A diferencia de los tokens de cuentas de servicios, este token es de corta duración (el Kubelet se ocupa de actualizarlo) y se puede personalizar definiendo la propiedad de su audiencia.
STS es un servicio de AWS (existen servicios similares de otros proveedores de nube) que nos permite brindar la confianza de AWS a otros sistemas de autenticación, incluso los proveedores de autenticación OIDC. Al configurar STS, podemos indicarle a AWS que confíe en los tokens JWT creados por OpenShift y los intercambie por tokens de AWS con un conjunto específico de permisos. Después de que se produce el intercambio, la aplicación que se ejecuta en un pod puede empezar a consumir recursos de AWS. En el siguiente diagrama, se muestra esta arquitectura:
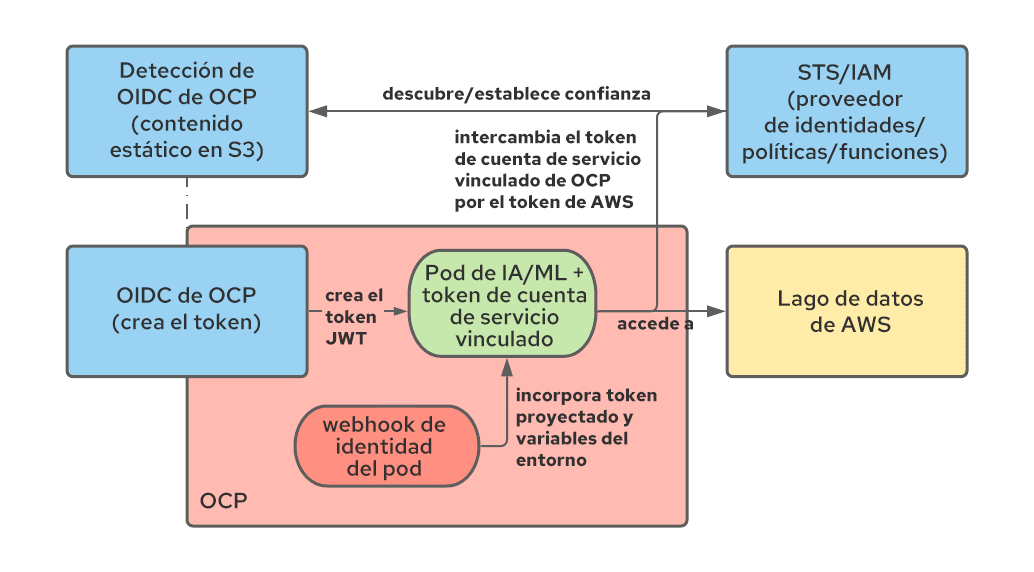
Para configurar la integración de STS, consulte los documentos oficiales y esta publicación de blog.
Uno de los requisitos de este enfoque es que las cuentas de servicios que se usan para ejecutar los pods de inteligencia artificial/machine learning tengan anotaciones específicas adjuntas que indiquen que estas cargas de trabajo requieren el token de cuenta de servicio vinculado adicional. Podemos hacerlo usando OPA e incorporando las anotaciones necesarias en las cuentas de servicios en los espacios de nombres de los analistas de datos.
El resultado de la configuración descrita anteriormente permite que los analistas de datos y, por lo general, las cargas de trabajo de inteligencia artificial/machine learning, accedan al lago de datos con credenciales que representan la carga de trabajo (y no a una persona en particular) y tienen una duración breve (por lo que no deben conservarse en ningún lado). Además, todo esto sucede de manera transparente para los analistas de datos, quienes solo necesitan usar cualquier cliente estándar de AWS (que comprenda el método de autenticación de STS) para acceder al lago de datos.
Integración con Serverless
Con respecto a la distribución de los modelos, la forma predeterminada de lograrlo en Kubeflow es con Kfserving (también se admiten otras estrategias que se describen aquí).
Kfserving se basa en Knative, una función de OpenShift que se puede habilitar mediante la instalación de OpenShift Serverless.
Para que Service Mesh y Serverless se integren correctamente y puedan utilizarse, se deben cumplir ciertos requisitos previos.
En particular, se debe crear una regla NetworkPolicy en cada espacio de nombres de la malla de servicios para permitir el tráfico desde los espacios de nombres de Serverless hacia los espacios de nombres de la malla.
Además, como todos los servicios de la malla en un ecosistema multiempresa de Kubeflow están protegidos por las políticas AuthorizationPolicies de Istio y los elementos sin servidor son externos a la malla, debemos modificar las políticas de RBAC para permitir conexiones desde los pods de los espacios de nombres de Serverless (específicamente, Kourier y Activator):
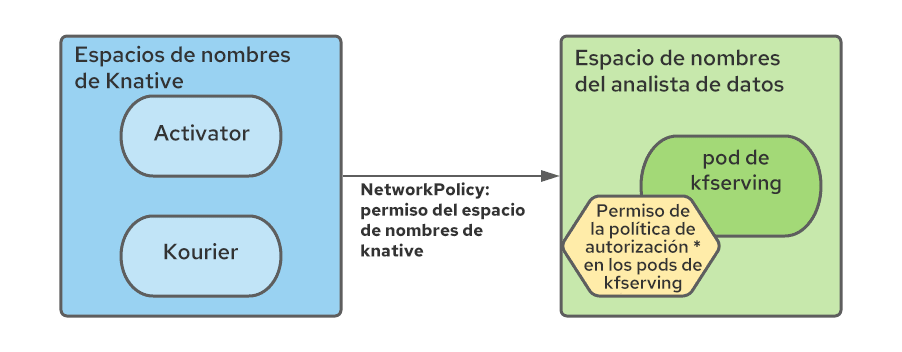
Automatizamos la creación de estas reglas con el operador de la configuración de los espacios de nombres y le indicamos que agregara los recursos NetworkPolicy y AuthorizationPolicy cuando se creen los espacios de nombres de los analistas de datos.
Instalación
Las instrucciones detalladas de la instalación de cada uno de los temas descritos con anterioridad junto con sus correspondientes configuraciones están disponibles en este repositorio. El tutorial también explica varias mejoras secundarias y algunos ejemplos de cargas de trabajo de inteligencia artificial/machine learning para validar la configuración.
Conclusión
En este artículo, analizamos varios aspectos que se deben tener en cuenta a la hora de configurar una implementación multiempresa de Kubeflow en OpenShift. Este es solo el primer paso en el proceso de adopción de la inteligencia artificial y el machine learning, pero es suficiente para comenzar. A partir de aquí, el equipo de analistas de datos puede comenzar a analizar los datos con Jupyter Notebooks y crear canales de datos, los cuales pueden incluir el entrenamiento de modelos de redes neuronales. Cuando los modelos de redes neuronales están listos, Kubeflow también puede participar en el caso práctico de la distribución de modelos.
Es importante recordar que, actualmente, Red Hat no admite el funcionamiento de Kubeflow en OpenShift. Además, Kubeflow es un producto con muchas funciones, pero como parte de esta implementación inicial, no validamos que todas ellas respondan correctamente (consulte la lista de funciones que probamos en el repositorio). Por ejemplo, una función importante que lamentablemente no está operativa en este momento, aunque podría integrarse en una fecha posterior, es toda la stack de determinación del estado interno de los sistemas que proporciona Kubeflow.
Esperamos que este tipo de trabajo se utilice para impulsar a las empresas que buscan ejecutar Kubeflow en OpenShift. Además, estos conceptos deben proporcionar muchas de las premisas comunes que se pueden usar al utilizar otras plataformas de inteligencia artificial/machine learning.
Sobre el autor

Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
Navegar por canal

Automatización
Las últimas novedades en la automatización de la TI para los equipos, la tecnología y los entornos

Inteligencia artificial
Descubra las actualizaciones en las plataformas que permiten a los clientes ejecutar cargas de trabajo de inteligecia artificial en cualquier lugar

Nube híbrida abierta
Vea como construimos un futuro flexible con la nube híbrida

Seguridad
Vea las últimas novedades sobre cómo reducimos los riesgos en entornos y tecnologías

Edge computing
Conozca las actualizaciones en las plataformas que simplifican las operaciones en el edge

Infraestructura
Vea las últimas novedades sobre la plataforma Linux empresarial líder en el mundo

Aplicaciones
Conozca nuestras soluciones para abordar los desafíos más complejos de las aplicaciones
Virtualización
El futuro de la virtualización empresarial para tus cargas de trabajo locales o en la nube